一种计算节点故障虚拟机的自动疏散方法及装置与流程
本发明涉及计算机技术领域,具体的说是一种云计算下计算节点故障虚拟机的自动疏散方法及装置。
背景技术:
openstack是一个开源的云计算管理平台项目,旨在为公共及私有云的建设与管理。随着越来越多的企业选择openstack作为云建设的基础软件,openstack运行的稳定性和可运维性提出越来越高的要求。openstack环境中分为控制节点和计算节点,控制节点包含各组件(nova/cinder/neutron/…)的api和调度等服务,已具备很成熟的高可用方案,如使用keepalived+haproxy保证各api服务的稳定性,mq和db都有各自的高可用方案,但是在计算节点仍缺少可靠的保障方案,尽管nova组件已提供疏散(evacuate)的api,但仅仅是一个疏散的工具,距离完整的解决方案还有很大的差距,特别是在运维成本上,需要技术能力高的运维人员进行精确的判断,然后再手动对故障计算节点上的虚拟机一一进行疏散,耗费大量的人力和精力,且很容易出现人为判断出错导致更严重的故障。
目前,业界使用的方案一般会使用pacemaker+corosync的方案,使用pacemaker的心跳来判断计算节点是否存在故障,如果存在故障则执行隔离和疏散策略。但此方案具有几个比较关键的限制,1)心跳的互传使用管理网,租户使用的是业务网,这样心跳如果存在丢失,并不能代表业务网出现问题,这时执行疏散会导致业务中断,反过来,如果心跳完好,但业务不通了,这时无法触发疏散操作;2)心跳丢失并不能判断计算节点出现了影响业务的故障,比如因bug或者系统资源争用,心跳的程序停止或者崩溃,但用户的业务还在正常运行,这时疏散也会影响业务,还需要更丰富和精准的监控指标供程序进行精准判断;3)此方案受限于pacemaker支持的节点数,无法满足大规模环境下的应用。
技术实现要素:
本发明针对openstack环境下的计算节点出现故障时需要耗费大量的人力和精力来进行疏散的问题,提供一种计算节点故障虚拟机的自动疏散方法及装置。
首先,本发明提供一种计算节点故障虚拟机的自动疏散方法,解决上述技术问题采用的技术方案如下:
一种计算节点故障虚拟机的自动疏散方法,在使用openstack搭建的环境中,
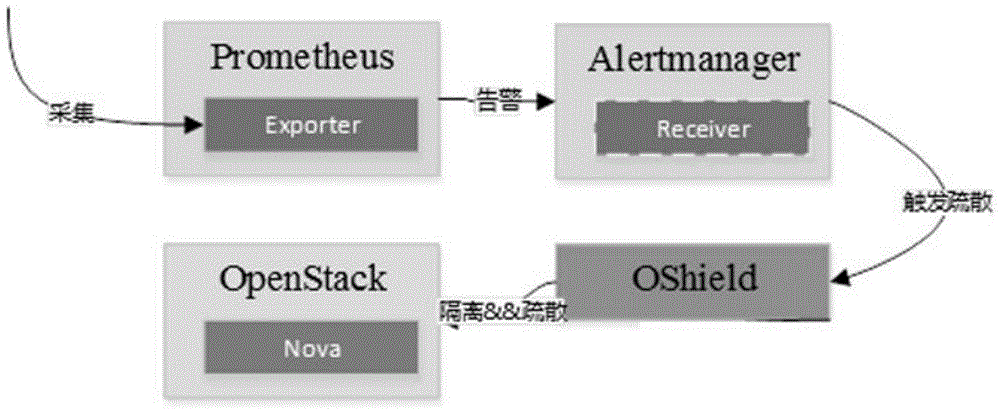
1)计算节点的采集程序定期去采集监控指标,并上报到prometheus;
2)prometheus的exporter对监控指标进行分析,如超出阈值并满足触发告警规则,则发送告警到alertmanager;
3)alertmanager发送告警到运维人员,并通过receiver调用oshield的api;
4)oshield处理api请求,对计算节点的故障虚拟机进行状态标记和隔离,同时,疏散计算节点上的其余虚拟机。
在步骤2)中,prometheus的exporter首先对监控指标进行组合,随后对组合后监控指标进行权重和打分,最后将打分结果与设定阈值进行比较,在打分结果超出设定阈值时,触发告警规则。
在步骤4)中,oshield调用ipmi命令对标记的故障虚拟机进行下电,完成隔离,同时,oshield调用novaevacuateapi疏散计算节点上的其余虚拟机。
可选的,所涉及计算节点为source计算节点,且source计算节点发生故障时,首先对source计算节点进行隔离,随后调用evacuateapi对source计算节点上的虚拟机进行疏散。
具体的,所涉及计算节点从主机、进程、虚拟机三个层面采集监控指标;
所涉及主机的cpu、内存条、硬盘三方面容易发生故障,所述主机发生故障时,运行在主机的虚拟机宕机,且无法运行,此时业务处于断掉状态;
所涉及进程发生故障时,一定会影响即将部署的虚拟机,已部署运行的虚拟机可能继续运行且业务不中断,但是,进程故障的发生必然影响对虚拟机将要进行的操作;
所涉及虚拟机发生故障时,不影响其余未发生故障的虚拟机。
其次,本发明还提供一种计算节点故障虚拟机的自动疏散装置,其包括:
采集端,部署于计算节点,用于定期采集计算节点的监控指标;
服务端,包括使用容器部署的prometheus、alertmanager和oshield,
其中,prometheus的exporter对监控指标进行分析,并在分析结果超出阈值且满足触发告警规则时发送告警到alertmanager,
alertmanager发送告警到运维人员,并通过receiver调用oshield的api,
oshield处理api请求,对计算节点的故障虚拟机进行状态标记和隔离,同时,疏散计算节点上的其余虚拟机。
可选的,一个计算节点部署有一个采集端telegraf;
一个服务端对多个计算节点的监控指标进行采集。
具体的,所涉及prometheus的exporter首先对监控指标进行组合,随后对组合后监控指标进行权重和打分,最后将打分结果与设定阈值进行比较,在打分结果超出设定阈值时,触发告警规则。
具体的,所涉及oshield调用ipmi命令对标记的故障虚拟机进行下电,完成隔离,同时,oshield调用novaevacuateapi疏散计算节点上的其余虚拟机。
具体的,所涉及计算节点从主机、进程、虚拟机三个层面采集监控指标;
所涉及主机的cpu、内存条、硬盘三方面容易发生故障,所述主机发生故障时,运行在主机的虚拟机宕机,且无法运行,此时业务处于断掉状态;
所涉及进程发生故障时,一定会影响即将部署的虚拟机,已部署运行的虚拟机可能继续运行且业务不中断,但是,进程故障的发生必然影响对虚拟机将要进行的操作;
所涉及虚拟机发生故障时,不影响其余未发生故障的虚拟机。
本发明的一种计算节点故障虚拟机的自动疏散方法及装置,与现有技术相比具有的有益效果是:
本发明在使用openstack搭建的环境中,利用计算节点的采集程序定期去采集监控指标,并上报到prometheus,prometheus的exporter对监控指标进行分析,如超出阈值并满足触发告警规则,则发送告警到alertmanager,alertmanager发送告警到运维人员,并通过receiver调用oshield的api,oshield处理api请求,对计算节点的故障虚拟机进行状态标记,通过oshield调用ipmi命令对标记的故障虚拟机进行下电,完成隔离,同时,通过oshield调用novaevacuateapi疏散计算节点上的其余虚拟机,解决了现有手动疏散计算节点上故障虚拟机时耗时耗力的问题,实现了自动化运维,适用于大规模的应用环境。
附图说明
附图1是本发明自动疏散方法的流程图;
附图2是本发明自动疏散装置的连接框图。
具体实施方式
为使本发明的技术方案、解决的技术问题和技术效果更加清楚明白,以下结合具体实施例,对本发明的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。
实施例一:
结合附图1,本实施例提出一种计算节点故障虚拟机的自动疏散方法,在使用openstack搭建的环境中,
1)计算节点的采集程序定期去采集监控指标,并上报到prometheus;
2)prometheus的exporter首先对监控指标进行组合,随后对组合后监控指标进行权重和打分,最后将打分结果与设定阈值进行比较,在打分结果超出设定阈值时,触发告警规则,进而发送告警到alertmanager;
3)alertmanager发送告警到运维人员,并通过receiver调用oshield的api;
4)oshield处理api请求,对计算节点的故障虚拟机进行状态标记,oshield调用ipmi命令对标记的故障虚拟机进行下电,完成隔离,同时,oshield调用novaevacuateapi疏散计算节点上的其余虚拟机。
在本实施例中,所涉及计算节点为source计算节点,且source计算节点发生故障时,首先对source计算节点进行隔离,随后调用evacuateapi对source计算节点上的虚拟机进行疏散。
在本实施例中,所涉及计算节点从主机、进程、虚拟机三个层面采集监控指标;
所涉及主机的cpu、内存条、硬盘三方面容易发生故障,所述主机发生故障时,运行在主机的虚拟机宕机,且无法运行,此时业务处于断掉状态;
所涉及进程发生故障时,一定会影响即将部署的虚拟机,已部署运行的虚拟机可能继续运行且业务不中断,但是,进程故障的发生必然影响对虚拟机将要进行的操作;
所涉及虚拟机发生故障时,不影响其余未发生故障的虚拟机。
实施例二:
结合附图1、2,本实施例提出一种计算节点故障虚拟机的自动疏散装置,其包括:
采集端,部署于计算节点,用于定期采集计算节点的监控指标;
服务端,包括使用容器部署的prometheus、alertmanager和oshield,
其中,prometheus的exporter首先对监控指标进行组合,随后对组合后监控指标进行权重和打分,最后将打分结果与设定阈值进行比较,在打分结果超出设定阈值时,触发告警规则,进而发送告警到alertmanager,
alertmanager发送告警到运维人员,并通过receiver调用oshield的api,
oshield处理api请求,对计算节点的故障虚拟机进行状态标记,
oshield调用ipmi命令对标记的故障虚拟机进行下电,完成隔离,同时,oshield调用novaevacuateapi疏散计算节点上的其余虚拟机。
结合附图2,在本实施例中,一个计算节点部署有一个采集端telegraf;
一个服务端对多个计算节点的监控指标进行采集。
在本实施例中,所涉及计算节点从主机、进程、虚拟机三个层面采集监控指标;
所涉及主机的cpu、内存条、硬盘三方面容易发生故障,所述主机发生故障时,运行在主机的虚拟机宕机,且无法运行,此时业务处于断掉状态;
所涉及进程发生故障时,一定会影响即将部署的虚拟机,已部署运行的虚拟机可能继续运行且业务不中断,但是,进程故障的发生必然影响对虚拟机将要进行的操作;
所涉及虚拟机发生故障时,不影响其余未发生故障的虚拟机。
综上可知,采用本发明的一种计算节点故障虚拟机的自动疏散方法及装置,可以通过oshield调用ipmi命令对标记的故障虚拟机进行下电,完成隔离,同时,通过oshield调用novaevacuateapi疏散计算节点上的其余虚拟机,解决现有手动疏散计算节点上故障虚拟机时耗时耗力的问题,实现自动化运维,尤其适用于大规模的应用环境。
以上应用具体个例对本发明的原理及实施方式进行了详细阐述,这些实施例只是用于帮助理解本发明的核心技术内容,并不用于限制本发明的保护范围。基于本发明的上述具体实施例,本技术领域的技术人员在不脱离本发明原理的前提下,对本发明所作出的任何改进和修饰,皆应落入本发明的专利保护范围。
- 还没有人留言评论。精彩留言会获得点赞!