基于层次存储的神经回路体数据处理方法、系统及介质与流程
本发明涉及神经回路精细结构的解析方法的大规模图像处理,具体涉及一种基于层次存储的神经回路体数据处理方法、系统及介质,用于在分布式多核计算平台上实现神经回路体数据分析过程中超大规模图像数据的分块处理。
背景技术:
神经回路信息是理解脑功能和脑疾病机制的关键,如何实现神经回路大数据的自动追踪,是脑科学等神经领域研究所面临的关键科学问题之一。神经元定位是神经回路数据解析的关键,通过对神经回路体数据进行分析得到精确的神经元胞体位置,是后续定量分析的基础。
随着观测技术的不断进步,高精度神经回路图像数据集的数据规模迅速增大,特别是光学分子标记和显微成像技术的巨大进步,使得高分辨率获取全脑数据成为现实。由于灵长类动物大脑体积较大,按照当前显微光学切片断层成像系统(micro-opticalsectioningtomography,most)和荧光显微光学切片断层成像系统(fluorescencemicro-opticalsectioningtomography,fmost)成像技术计算,进行各向1微米分辨率的成像,会产生数十tb图像数据,包括数万个图层。传统的神经回路体数据处理方法需要将体数据从磁盘阵列全部载入内存,然而现有的计算节点内存容量只能达到tb量级,无法处理十tb量级的图像数据。如何有效处理包含数万个图层的十tb级图像数据,在神经回路分析的图像数据处理方面是巨大的挑战,已成为制约能否将获取的数据转化为知识的瓶颈问题。
技术实现要素:
本发明要解决的技术问题:针对现有技术的上述问题,提供一种基于层次存储的神经回路体数据处理方法、系统及介质,本发明能够有效处理十tb量级的超大规模图像数据,具有处理速度快、可扩展性强的特点,能够部署在分布式计算平台,实现灵活且支持参数配置,易于移植与推广。
为了解决上述技术问题,本发明采用的技术方案为:
一种基于层次存储的神经回路体数据处理方法,实施步骤包括:
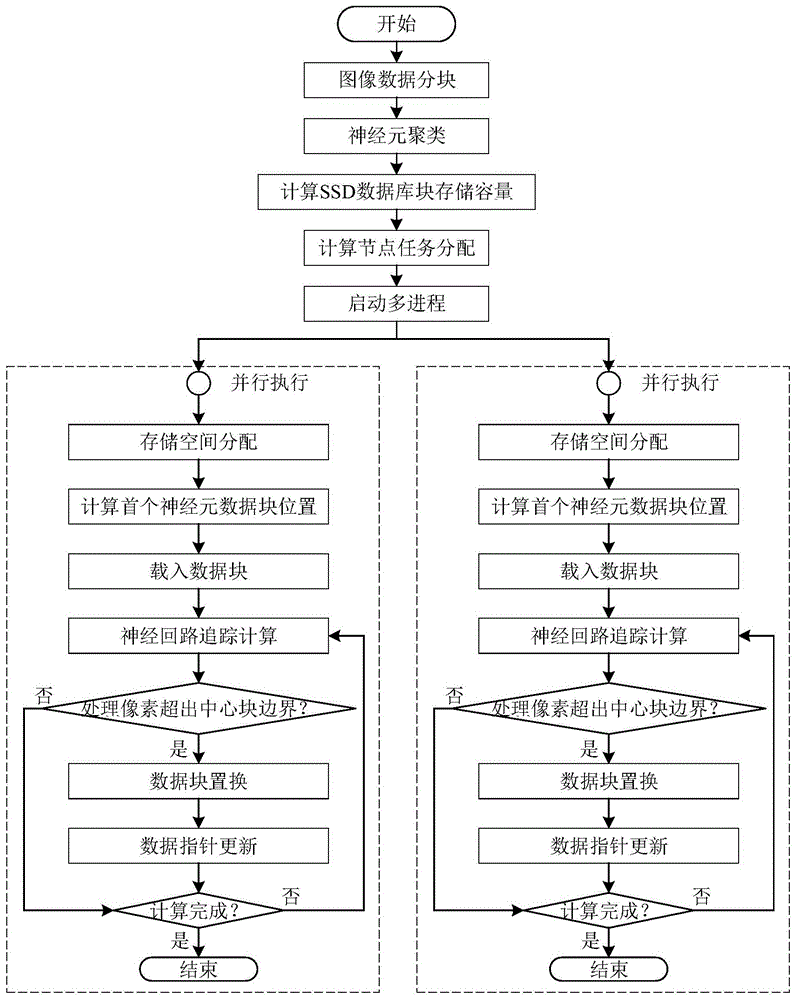
1)根据计算节点配置将输入图像数据进行分块,根据计算节点数量对神经元进行聚类并对计算节点进行神经元聚类结果的任务分配;
2)各计算节点进行变量和存储空间分配及初始化,将各计算节点的首个任务对应的数据块从磁盘阵列分别加载到各计算节点内存;
3)各计算节点启动多进程并通过各进程独立执行神经回路追踪任务,且在计算过程中按数据预取规则从存储设备中将数据块读入内存、按数据替换规则将数据块从内存写入存储设备直至分配的任务全部处理完毕。
可选地,步骤1)中根据计算节点配置将输入图像数据进行分块的详细步骤包括:获取计算节点的内存容量szmem,根据计算节点的内存容量szmem以及下式计算出图像数据的分块尺寸szblk;获取图像数据在x方向的像素数xdim、y方向的像素数ydim、z方向的图层数zdim,将输入的图像数据映射为最大尺寸szblk*szblk*szblk的分块立方体集合,每个数据块具有唯一的坐标(bx,by,bz),其中bx、by、bz为正整数;如果满足xdim<szblk,则x方向分块尺寸xscale的值为xdim,否则x方向分块尺寸xscale的值为szblk,x方向分块数量xnum的值为
可选地,步骤1)中根据计算节点数量对神经元进行聚类并对计算节点进行神经元聚类结果的任务分配的详细步骤包括:获取计算节点个数nnode,计算节点编号为1…nnode,使用指定的聚类算法将输入的神经元集合按照空间坐标分为nnode个簇,每个簇内的神经元的空间位置相对集中,每个簇对应的计算任务分配到一个计算节点,使得每个计算节点负责一个簇内所有的神经元的回路追踪计算。
可选地,步骤2)的详细步骤包括:
2.1)各个计算节点声明规模为3*3*3的指针变量三维数组blkptr,对于该数组内每个指针变量blkptr[i][j][k]分配内存空间容量为szblk3,其中i、j、k为正整数且1≤i,j,k≤3,szblk表示将输入图像数据进行分块得到的图像数据的分块尺寸。
2.2)各个计算节点计算本节点所对应的神经元集合中首个神经元的数据块位置,对于坐标为(x,y,z)的神经元,其所在的数据块坐标(bx,by,bz)中各个方向坐标值均为将对应神经元的相同方向的坐标值除以该方向的分块尺寸再进行上取整得到;各个计算节点将首个神经元对应的坐标为(bx,by,bz)的数据块和邻近的26个数据块按照指定的映射关系分别从磁盘阵列载入blkptr指针所指向的本地内存空间。
可选地,步骤3)中各计算节点启动多进程并通过各进程独立执行神经回路追踪任务的详细步骤包括:
3.1)使用指定算法以当前神经元为起点,开始进行神经回路追踪计算;
3.2)在计算过程中,当处理像素的坐标(x',y',z')超出坐标(bx,by,bz)的数据块的边界时,跳转执行下一步以进行数据块置换;
3.3)计算当前处理像素所属数据块坐标(bx',by',bz'),计算数据块坐标位移(dx,dy,dz),其中dx=bx'-bx,dy=by'-by,dz=bz'-bz,由于像素处理的连续性,当前处理像素必然位于坐标(bx,by,bz)的数据块的邻接数据块,因此dx、dy和dz取值为0或1或-1,且坐标(bx',by',bz')的数据块已经载入内存,可以直接开始像素计算;
3.4)以坐标(bx',by',bz')的数据块作为中心,即将内存数据块中心块坐标更新为(bx+dx,by+dy,bz+dz);
3.5)进行数据块写出操作:遍历blkptr指针索引数组,对于blkptr[i][j][k],如果指针不为空并且满足条件1时,按照指定的映射关系,将符合条件1的指针对应的数据块从内存写出存储设备;条件1的表达式如下:
i-dx>3ori-dx<1orj-dy>3orj-dy<1ork-dz>3ork-dz<1
上式中,(dx,dy,dz)为数据块坐标位移,i、j、k为三维数组blkptr的指针变量blkptr[i][j][k]中的循环变量,其中i、j、k为正整数且取值均为1~3之间;
3.6)进行数据块指针更新操作:遍历blkptr指针索引数组,对于blkptr[i][j][k],满足条件2时,目标数据块已经在内存中,直接进行数据块指针更新:blkptr[i][j][k]=blkptr[i+dxj+dyk+dz;不满足条件2时,按照指定的映射关系获取应载入的数据块坐标(bx,by,bz)并将对应的数据块加载到内存;其中,条件2的表达式如下:
1≤i+dx≤3and1≤j+dy≤3and1≤k+dz≤3
上式中,(dx,dy,dz)为数据块坐标位移,i、j、k为三维数组blkptr的指针变量blkptr[i][j][k]中的循环变量,其中i、j、k为正整数且取值均为1~3之间。
可选地,步骤3)之前还包括计算固态盘最大可存储的数据块个数nssd的步骤,详细步骤包括:获取计算节点固态盘容量szssd,设置固态盘当前数据块计数器变量cssd为0,计算固态盘最大可存储的数据块个数nssd,声明固态盘数据块位置队列qssd并初始化为空,队列内存储的元素类型为四元组(bx,by,bz,bpos),其中(bx,by,bz)为数据块坐标,bpos为数据块在固态盘上的存储位置;步骤3.5)中将符合条件1的指针对应的数据块从内存写出存储设备的详细步骤包括:如果固态盘当前数据块计数器变量cssd小于固态盘最大可存储的数据块个数nssd成立则表示固态盘有空余存储空间,将数据块写入固态盘,并更新固态盘当前数据块计数器变量cssd的值使其在原值的基础上加1,将数据块坐标(bx,by,bz)和文件位置bpos加入固态盘数据块位置队列qssd尾部;如果固态盘当前数据块计数器变量cssd等于固态盘最大可存储的数据块个数nssd成立则表示固态盘存储空间已满,将固态盘中存入时间最早的数据块迁移到磁盘,所述固态盘中存入时间最早的数据块为固态盘数据块位置队列qssd头部的数据块,并将该数据块信息从固态盘数据块位置队列qssd删除,然后再将当前数据块写入固态盘,并将数据块坐标(bx,by,bz)和数据块在固态盘上的存储位置bpos加入固态盘数据块位置队列qssd尾部;步骤3.6)中将对应的数据块加载到内存具体是指如果数据块坐标存在于固态盘数据块位置队列qssd,则根据对应的数据块在固态盘上的存储位置bpos,从固态盘将对应的数据块加载到内存,否则从磁盘将指针对应的数据块加载到内存。
可选地,步骤3.2)中处理像素的坐标(x',y',z')超出坐标(bx,by,bz)的数据块的边界具体是指满足下述函数表达式中的任意一项:
上式中,(x',y',z')为处理像素的坐标,(bx,by,bz)为所在的数据块坐标,xscale为z方向分块尺寸,yscale为z方向分块尺寸,zscale为z方向分块尺寸。
此外,本发明还提供一种基于层次存储的神经回路体数据处理系统,包括:
调度管理节点,用于根据计算节点配置将输入图像数据进行分块,根据计算节点数量对神经元进行聚类并对计算节点进行神经元聚类结果的任务分配;
计算节点,用于进行变量和存储空间分配及初始化,将各计算节点的首个任务对应的数据块从磁盘阵列分别加载到各计算节点内存;启动多进程并通过各进程独立执行神经回路追踪任务,且在计算过程中按数据预取规则从存储设备中将数据块读入内存、按数据替换规则将数据块从内存写入存储设备直至分配的任务全部处理完毕。
此外,本发明还提供一种基于层次存储的神经回路体数据处理系统,包括计算机设备,该计算机设备被编程或配置以执行所述基于层次存储的神经回路体数据处理方法的步骤,或者该计算机设备的存储介质上存储有被编程或配置以执行所述基于层次存储的神经回路体数据处理方法的计算机程序。
此外,本发明还提供一种计算机可读存储介质,该计算机可读存储介质上存储有被编程或配置以执行所述基于层次存储的神经回路体数据处理方法的计算机程序。
和现有技术相比,本发明具有下述优点:本发明采用分块方法进行神经回路体数据处理,能够处理十tb量级的超大规模图像数据,计算速度快、易于在分布式多核计算平台上并行计算且可扩展性强;通过采用ssd作为数据缓存,提高了热点数据块的读取速度;数据i/o与数据计算并行进行,有效的隐藏了数据传输延迟。本发明实现灵活且支持参数配置,具备处理速度快、程序执行时间短、易于移植与推广的优点。
附图说明
图1为本发明实施例方法的基本流程示意图。
图2为本发明实施例方法的数据块坐标和blkptr指针索引的映射关系。
图3为本发明实施例方法的示例数据块坐标和blkptr指针索引的映射关系。
具体实施方式
下文将以配备20个计算节点的分布式计算集群作为计算平台的示例,其中每个计算节点配置双路十二核2.4ghzcpu,内存容量为128gb,每个计算节点配置ssd容量为1tb,共享磁盘阵列容量为100tb,对本发明基于层次存储的神经回路体数据处理方法、系统及介质进行进一步的详细说明。输入数据由10000张分辨率为20000×40000的单图层图像序列组成,每个像素为2个字节,数据总量为16tb。
如图1所示,本实施例基于层次存储的神经回路体数据处理方法的步骤包括:
1)根据计算节点配置将输入图像数据进行分块,根据计算节点数量对神经元进行聚类并对计算节点进行神经元聚类结果的任务分配;
2)各计算节点进行变量和存储空间分配及初始化,将各计算节点的首个任务对应的数据块从磁盘阵列分别加载到各计算节点内存;
3)各计算节点启动多进程并通过各进程独立执行神经回路追踪任务,且在计算过程中按数据预取规则从存储设备中将数据块读入内存、按数据替换规则将数据块从内存写入存储设备直至分配的任务全部处理完毕。
本实施例中,步骤1)中根据计算节点配置将输入图像数据进行分块的详细步骤包括:获取计算节点的内存容量szmem,根据计算节点的内存容量szmem以及下式计算出图像数据的分块尺寸szblk;获取图像数据在x方向的像素数xdim、y方向的像素数ydim、z方向的图层数zdim,将输入的图像数据映射为最大尺寸szblk*szblk*szblk的分块立方体集合,每个数据块具有唯一的坐标(bx,by,bz),其中bx、by、bz为正整数;如果满足xdim<szblk,则x方向分块尺寸xscale的值为xdim,否则x方向分块尺寸xscale的值为szblk,x方向分块数量xnum的值为
本实施例中,获取计算节点内存容量szmem=128gb,图像数据的分块尺寸szblk的计算方法为:
因此,获取图像数据在x、y方向的像素数xdim=20000,ydim=40000,以及在z方向的图层数zdim=10000,将输入的图像数据映射为最大尺寸szblk*szblk*szblk=1000*1000*1000的分块立方体集合,每个数据块具有唯一的坐标(bx,by,bz),其中bx、by、bz为正整数。
由于20000>1000,x方向分块尺寸xscale=1000,分块数量
由于40000>1000,y方向分块尺寸yscale=1000,分块数量
由于10000>1000,z方向分块尺寸zscale=1000,分块数量
分块总数量bnum=xnum*ynum*znum=20*40*10=8000,x、y和z方向分别从1开始依次编号。
本实施例中,步骤1)中根据计算节点数量对神经元进行聚类并对计算节点进行神经元聚类结果的任务分配的详细步骤包括:获取计算节点个数nnode,计算节点编号为1…nnode,使用指定的聚类算法将输入的神经元集合按照空间坐标分为nnode个簇,每个簇内的神经元的空间位置相对集中,每个簇对应的计算任务分配到一个计算节点,使得每个计算节点负责一个簇内所有的神经元的回路追踪计算。具体地,本实施例中获取计算节点个数nnode=20,计算节点编号为1…20,使用k-means聚类算法,将输入的神经元集合按照空间坐标分为20个簇,每个簇内的神经元的空间位置相对集中,每个簇对应的计算任务分配到一个计算节点,即每个计算节点负责一个簇内所有的神经元的回路追踪计算。本实施例中,前述指定的聚类算法具体采用k-means聚类算法,此外也可以根据需要采用其他聚类算法。
本实施例中,步骤2)的详细步骤包括:
2.1)各个计算节点声明规模为3*3*3的指针变量三维数组blkptr,对于该数组内每个指针变量blkptr[i][j][k]分配内存空间容量为szblk3,其中i、j、k为正整数且1≤i,j,k≤3,szblk表示将输入图像数据进行分块得到的图像数据的分块尺寸。
2.2)各个计算节点计算本节点所对应的神经元集合中首个神经元的数据块位置,对于坐标为(x,y,z)的神经元,其所在的数据块坐标(bx,by,bz)中各个方向坐标值均为将对应神经元的相同方向的坐标值除以该方向的分块尺寸再进行上取整得到;各个计算节点将首个神经元对应的坐标为(bx,by,bz)的数据块和邻近的26个数据块按照指定的映射关系分别从磁盘阵列载入blkptr指针所指向的本地内存空间。
本实施例中,步骤2.1)中数组内每个指针变量blkptr[i][j][k]分配内存空间容量为2*10003byte=2gb,步骤2.2)中各个计算节点计算本节点所对应的神经元集合中首个神经元的数据块位置,以坐标为(10011,25432,1039)的神经元为例,其所在的数据块坐标(bx,by,bz)的计算方法为:
各个计算节点将首个神经元对应坐标为(bx,by,bz)的数据块和邻近26个数据块分别从磁盘阵列载入blkptr指针指向的本地内存空间,具体映射关系如图2所示。对于上述神经元所在的坐标为(11,26,2)的数据块,载入的数据块坐标和blkptr指针索引的映射关系如图3所示。
本实施例中,步骤3)中各计算节点启动多进程并通过各进程独立执行神经回路追踪任务的详细步骤包括:
3.1)使用指定算法以当前神经元为起点,开始进行神经回路追踪计算;本实施例中,进行神经回路追踪计算的指定算法采用neurotree算法,此外也可以根据需要采用其他可实现神经回路追踪计算的算法;
3.2)在计算过程中,当处理像素的坐标(x',y',z')超出坐标(bx,by,bz)的数据块的边界时,跳转执行下一步以进行数据块置换;
3.3)计算当前处理像素所属数据块坐标(bx',by',bz'),计算数据块坐标位移(dx,dy,dz),其中dx=bx'-bx,dy=by'-by,dz=bz'-bz,由于像素处理的连续性,当前处理像素必然位于坐标(bx,by,bz)的数据块的邻接数据块,因此dx、dy和dz取值为0或1或-1,且坐标(bx',by',bz')的数据块已经载入内存,可以直接开始像素计算;
3.4)以坐标(bx',by',bz')的数据块作为中心,即将内存数据块中心块坐标更新为(bx+dx,by+dy,bz+dz);
3.5)进行数据块写出操作:遍历blkptr指针索引数组,对于blkptr[i][j][k],如果指针不为空并且满足条件1时,按照指定的映射关系,将符合条件1的指针对应的数据块从内存写出存储设备;条件1的表达式如下:
i-dx>3ori-dx<1orj-dy>3orj-dy<1ork-dz>3ork-dz<1
上式中,(dx,dy,dz)为数据块坐标位移,i、j、k为三维数组blkptr的指针变量blkptr[i][j][k]中的循环变量,其中i、j、k为正整数且取值均为1~3之间;
3.6)进行数据块指针更新操作:遍历blkptr指针索引数组,对于blkptr[i][j][k],满足条件2时,目标数据块已经在内存中,直接进行数据块指针更新:blkptr[i][j][k]=blkptr[i+dxj+dyk+dz;不满足条件2时,按照指定的映射关系获取应载入的数据块坐标(bx,by,bz)并将对应的数据块加载到内存;其中,条件2的表达式如下:
1≤i+dx≤3and1≤j+dy≤3and1≤k+dz≤3
上式中,(dx,dy,dz)为数据块坐标位移,i、j、k为三维数组blkptr的指针变量blkptr[i][j][k]中的循环变量,其中i、j、k为正整数且取值均为1~3之间。
本实施例中,步骤3.2)中处理像素的坐标(x',y',z')超出坐标(bx,by,bz)的数据块的边界具体是指满足下述函数表达式中的任意一项:
上式中,(x',y',z')为处理像素的坐标,(bx,by,bz)为所在的数据块坐标,xscale为x方向分块尺寸,yscale为y方向分块尺寸,zscale为z方向分块尺寸。由于本实施例中xscale,yscale,zscale均为1000,上式可表示为:
步骤3.3)~3.6)为进行数据置换(内存、存储设备之间)的步骤,为了提高内存、存储设备之间数据置换的性能,本实施例中还通过ssd(固态盘)进行加速。步骤3)之前还包括计算固态盘最大可存储的数据块个数nssd的步骤,详细步骤包括:获取计算节点固态盘容量szssd,设置固态盘当前数据块计数器变量cssd为0,计算固态盘最大可存储的数据块个数nssd,声明固态盘数据块位置队列qssd并初始化为空,队列内存储的元素类型为四元组(bx,by,bz,bpos),其中(bx,by,bz)为数据块坐标,bpos为数据块在固态盘上的存储位置;本实施例中获取计算节点固态盘容量szssd=1tb=1*1012byte,每个像素为16位,对应2个字节,相应的nbyte=2。设置固态盘当前数据块计数器变量cssd为0,计算固态盘最大可存储的数据块个数nssd,计算方法为:
在完成初始化后,后续的通过ssd(固态盘)进行加速的步骤包括:
其一、步骤3.5)中将符合条件1的指针对应的数据块从内存写出存储设备的详细步骤包括:如果cssd<nssd成立则表示固态盘有空余存储空间,将数据块写入固态盘,并更新cssd=cssd+1,将数据块坐标(bx,by,bz)和文件位置bpos加入固态盘数据块位置队列qssd尾部;如果cssd=nssd成立则表示固态盘存储空间已满,将ssd中存入时间最早的数据块迁移到磁盘,所述固态盘中存入时间最早的数据块为固态盘数据块位置队列qssd头部的数据块,并将该数据块信息从固态盘数据块位置队列qssd删除,然后再将当前数据块写入固态盘,并将数据块坐标(bx,by,bz)和文件位置bpos加入固态盘数据块位置队列qssd尾部;
其二、步骤3.6)中将对应的数据块加载到内存具体是指如果数据块坐标存在于固态盘数据块位置队列qssd,则根据对应的数据块文件位置bpos,从固态盘将对应的数据块加载到内存,否则从磁盘将指针对应的数据块加载到内存。
综上所述,本实施例基于层次存储的神经回路体数据处理方法使用分布式多核计算平台,采用分块处理的方式,基于层次存储进行神经回路体数据处理。本实施例基于层次存储的神经回路体数据处理方法可以处理十tb级数据,具有良好的适应性和扩展性。
此外,本实施例还提供一种基于层次存储的神经回路体数据处理系统,包括:
调度管理节点,用于根据计算节点配置将输入图像数据进行分块,根据计算节点数量对神经元进行聚类并对计算节点进行神经元聚类结果的任务分配;
计算节点,用于进行变量和存储空间分配及初始化,将各计算节点的首个任务对应的数据块从磁盘阵列分别加载到各计算节点内存;启动多进程并通过各进程独立执行神经回路追踪任务,且在计算过程中按数据预取规则从存储设备中将数据块读入内存、按数据替换规则将数据块从内存写入存储设备直至分配的任务全部处理完毕。
需要说明的是,调度管理节点、计算节点是逻辑层面的节点划分方式,两者既可以采用不同的物理计算机节点实现,也可以采用相同的物理计算机节点实现。
此外,本实施例还提供一种基于层次存储的神经回路体数据处理系统,包括计算机设备,该计算机设备被编程或配置以执行本实施例前述基于层次存储的神经回路体数据处理方法的步骤,或者该计算机设备的存储介质上存储有被编程或配置以执行本实施例前述基于层次存储的神经回路体数据处理方法的计算机程序。
此外,本实施例还提供一种计算机可读存储介质,该计算机可读存储介质上存储有被编程或配置以执行本实施例前述基于层次存储的神经回路体数据处理方法的计算机程序。
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!