一种大数据分析中两个大整数降维比较方法与流程
本发明属于大数据分析技术领域,涉及一种大数据分析中两个大整数降维比较方法。
背景技术:
计算机内存的大小由地址总线的位数决定,如果地址总线的位数是32,那么内存的大小为232=4gb。利用计算机实现对问题的求解,需要把处理的数据和对应的程序调入内存后,程序才能运行并对数据实现处理。在大数据应用环境下,需要处理的数据的二进制长度远远大于地址总线的位数,换句话说,内存无法存储需要处理的数据。在此情况下,如何实现大整数的比较?目前的技术基于的思想普遍是“分而治之”,对大整数进行划分,然后通过迭代或递归的方式实现对大整数的比较,其存储效率和计算效率不高。假设比较两个属于[29999,210000-1]范围内的两个大整数,将每个整数按照大小为220的分块进行划分,那么每个整数将被划分为500个分块,比较需要进行500次迭代,每轮迭代需要花费的存储空间大小是(2×220)/8=218b,其存储效率和计算效率均不高。因此,如何实现高效的大整数比较是一个值得研究问题。
技术实现要素:
为了解决上述问题,本发明提供了一种大数据分析中两个大整数降维比较方法。
本发明所采用的技术方案是:本发明所采用的技术方案是:一种大数据分析中两个大整数的降维比较方法。假设给定的两个大整数是a和b,它们的二进制长度为n,n接近或大于计算机地址总线的位数,即a和b的大小接近或超过计算机内存所能存储的最大整数。用(an-1,an-2,…,a1,a0)表示大整数a的n个二进制位,用(bn-1,bn-2,…,b1,b0)表示大整数b的n个二进制位。
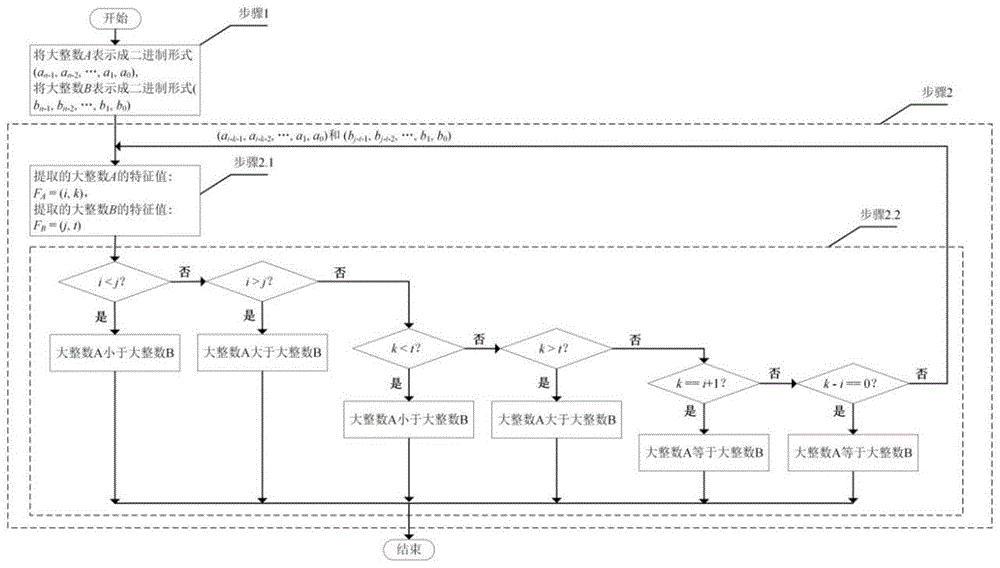
其特征在于,所述方法包括以下步骤:
步骤1:将大整数a和大整数b表示成二进制形式(an-1,an-2,…,a1,a0)和(bn-1,bn-2,…,b1,b0);
步骤2:基于大整数a和大整数b的二进制形式实现对它们的比较。
作为优选,步骤2的具体实现包括:
步骤2.1:从大整数的最高比特位开始,向低比特位的方向提取大整数的特征值。假设提取的大整数a的特征值为fa=(i,k),提取的大整数b的特征值为fb=(j,t);
步骤2.2:依据大整数a的特征值为fa=(i,k)和大整数b的特征值为fb=(j,t),进行如下判断:
(i)如果i<j,则大整数a小于大整数b,比较过程结束;
(ii)如果i>j,则大整数a大于大整数b,比较过程结束;
(iii)如果i==j,则继续比较k和t:
a)如果k<t,则大整数a小于大整数b,比较过程结束;
b)如果k>t,则大整数a大于大整数b,比较过程结束;
如果(k==t且k==i+1)或者(k==t且i-k==0),则大整数a等于大整数b,比较过程结束;否则从大整数a的第i-k-1位、大整数b的第j-t-1位开始,向低比特位的方向重新提取大整数a的特征值fa=(i,k)和大整数b的特征值fb=(j,t),即从(ai-k-1,ai-k-2,…,a1,a0)和(bj-t-1,bj-t-2,…,b1,b0)的最高比特位开始,向低比特位的方向重新提取大整数a的特征值fa=(i,k)和大整数b的特征值fb=(j,t),然后重复步骤2.2。
作为优选,步骤2.1的具体实现包括:
根据大整数a的二进制位形式(an-1,an-2,…,a1,a0),从高比特位往低比特位的方向找到首个“值为1”的比特位,假设为ai,即an-1=an-2=…=ai+1=0且ai=1,并统计从ai开始出现多少个连续“值为1”的比特位,假设有k(1≤k<i+1)个这样的比特位,即ai=ai-1=…=ai-(k-1)=1且ai-k=0,当k=i+1时,意味着ai=ai-1=…=a0=1。若所有二进制位均为0(即an-1=an-2=…=a0=0),则令i=k=0。将fa=(i,k)定义为大整数a的特征值。显然,大整数a的特征值fa=(i,k)中的i,k均属于[0,n]范围内的整数,它们的二进制长度为log2n。
根据大整数b的二进制位形式(bn-1,bn-2,…,b1,b0),从高比特位往低比特位的方向找到首个“值为1”的比特位,假设为bj,即bn-1=bn-2=…=bj+1=0且bj=1,并统计从bj开始出现多少个连续“值为1”的比特位,假设有t(1≤t<j+1)个这样的比特位,即bj=bj-1=…=bj-(t-1)=1且bj-t=0,当t=j+1时,意味着bj=bj-1=…=b0=1。若所有二进制位均为0(即bn-1=bn-2=…=b0=0),则令j=t=0。将fb=(j,t)定义为大整数b的特征值。显然,大整数b的特征值fb=(j,t)中的j,t均属于[0,n]范围内的整数,它们的二进制长度为
通过上述特征值提取,将两个二进制长度为n的大整数a和b的比较转换为对应的二进制长度为
本发明方法与现有的技术相比有如下的优点和有益效果:
本发明公开了一种大数据分析中两个大整数的降维比较方法。针对大数据应用环境中的大整数比较的问题,本发明首先提取每个大整数的特征值;然后将大整数的比较转换为对应特征值的比较。如果大整数的二进制位长度为n,那么它对于的特征值的二进制位长度为
附图说明
图1:本发明实施例的流程图;
图2:本发明实施例的大整数a特征值提取示意图1;
图3:本发明实施例的大整数a特征值提取示意图2;
图4:本发明实施例的大整数a特征值提取示意图3;
图5:本发明实施例的大整数a特征值提取示意图4;
图6:本发明实施例的大整数b特征值提取示意图1;
图7:本发明实施例的大整数b特征值提取示意图2;
图8:本发明实施例的大整数b特征值提取示意图3;
图9:本发明实施例的大整数b特征值提取示意图4。
具体实施
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
请见图1,本发明提供的一种大数据分析中两个大整数的降维比较方法,包括以下步骤:
步骤1:将大整数a和大整数b表示成二进制形式(an-1,an-2,…,a1,a0)和(bn-1,bn-2,…,b1,b0);
步骤2:基于大整数a和大整数b的二进制形式实现对它们的比较。
步骤2.1:从大整数的最高比特位开始,向低比特位的方向提取大整数的特征值。假设提取的大整数a的特征值为fa=(i,k),提取的大整数b的特征值为fb=(j,t)。
请见图2和图3,根据大整数a的二进制位形式(an-1,an-2,…,a1,a0),从高比特位往低比特位的方向找到首个“值为1”的比特位,假设为ai,即an-1=an-2=…=ai+1=0且ai=1,并统计从ai开始出现多少个连续“值为1”的比特位,假设有k(1≤k<i+1)个这样的比特位,即ai=ai-1=…=ai-(k-1)=1且ai-k=0。
请见图4,当k=i+1时,意味着ai=ai-1=…=a0=1。
请见图5,若所有二进制位均为0(即an-1=an-2=…=a0=0),则令i=k=0。
显然,大整数a的特征值fa=(i,k)中的i,k均属于[0,n]范围内的整数,它们的二进制长度为log2n。
请见图6和图7,根据大整数b的二进制位形式(bn-1,bn-2,…,b1,b0),从高比特位往低比特位的方向找到首个“值为1”的比特位,假设为bj,即bn-1=bn-2=…=bj+1=0且bj=1,并统计从bj开始出现多少个连续“值为1”的比特位,假设有t(1≤t<j+1)个这样的比特位,即bj=bj-1=…=bj-(t-1)=1且bj-t=0。
见图8,当t=j+1时,意味着bj=bj-1=…=b0=1。
见图9,若所有二进制位均为0(即bn-1=bn-2=…=b0=0),则令j=t=0。
显然,大整数b的特征值fb=(j,t)中的j,t均属于[0,n]范围内的整数,它们的二进制长度为
步骤2.2:依据大整数a的特征值为fa=(i,k)和大整数b的特征值为fb=(j,t),进行如下判断:
(i)如果i<j,则大整数a小于大整数b,比较过程结束;
(ii)如果i>j,则大整数a大于大整数b,比较过程结束;
(iii)如果i==j,则继续比较k和t:
a)如果k<t,则大整数a小于大整数b,比较过程结束;
b)如果k>t,则大整数a大于大整数b,比较过程结束;
c)如果(k==t且k==i+1)或者(k==t且i-k==0),则大整数a等于大整数b,比较过程结束;否则从大整数a的第i-k-1位、大整数b的第j-t-1位开始,向低比特位的方向重新提取大整数a的特征值fa=(i,k)和大整数b的特征值fb=(j,t),即从(ai-k-1,ai-k-2,…,a1,a0)和(bj-t-1,bj-t-2,…,b1,b0)的最高比特位开始,向低比特位的方向重新提取大整数a的特征值和大整数b的特征值,然后重复步骤2.2。
本发明针对如何高效解决大数据应用环境下两个大整数比较的问题,提出一种降维比较的方法。首先分别提取两个大整数的特征值,然后通过比较大整数的特征值得到两个大整数的比较结果。如果大整数是n比特长的数,本发明提出的大整数的特征值是
本发明可用于大数据环境下的搜索、排序、匹配等应用,具有很高的实用性。
应当理解的是,本说明书未详细阐述的部分均属于现有技术;上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!