一种基于多XGBoost模型融合的母线负荷预测方法与流程
本发明涉及母线负荷预测技术领域,具体为一种基于多xgboost模型融合的母线负荷预测方法。
背景技术:
母线负荷是指由变电站的主变压器供给某一供电区域的终端负荷的总和。由于供电区域通常较小,母线负荷量级低,一般仅为几百兆瓦。此外由于不同供电区域的用户性质存在差异,例如,某些区域居民负荷偏多,而某些区域工业负荷偏多,因此各母线的负荷成分往往不同,导致预测难度更大。
近年来,机器学习技术快速发展,被广泛应用于负荷预测领域。极限梯度提升(xgboost)是基于梯度提升手段实现的机器学习模型,在各类机器学习预测比赛中表现优异。对于母线负荷预测,由于母线负荷的随机性较强,模型学习不充分的现象时有发生。为此,可考虑采用模型融合手段将多个模型集成,构成综合预测系统,以强化学习效果,提升预测精度。
综上,对于母线负荷预测问题,单一的机器学习模型难以有效应对,因此可考虑结合模型融合手段解决母线负荷预测问题。
技术实现要素:
本发明所要解决的技术问题是如何提高母线负荷的预测精度。
为实现以上目的,本发明提出的技术方案为:一种基于多xgboost模型融合的母线负荷预测方法,包括以下步骤:
步骤a:对母线负荷数据及其相关数据进行数据预处理;
步骤b:构建样本集,划分训练集与测试集;
步骤c:构建分层预测系统,共2层,第一层为n个xgboost模型,第二层为1个xgboost模型;n≥1;
步骤d:利用粒子群算法优化分层预测系统参数;
步骤e:应用分层预测系统进行训练与预测。
进一步,步骤a中,对母线负荷数据及其相关数据进行数据预处理,包括:
步骤a1:获取母线负荷数据及其相关数据,相关数据包括日期类型、时刻、气象条件等;
步骤a2:采用线性插值法填补母线负荷数据中的缺失值,并对填补后的母线负荷数据进行归一化处理;
步骤a3:对日期类型、时刻、风速、降雨量等数据进行独热编码,对温度、湿度等数据进行归一化处理。
进一步,步骤c中,构建分层预测系统,共2层,第一层为3个xgboost模型,第二层为1个xgboost模型,包括:
步骤c1:建立3个xgboost模型,以并行方式分布,用于一次学习,3个xgboost模型的输出为母线负荷一次预测值;
步骤c2:建立1个xgboost模型,顺序连接在3个xgboost模型之后,即以第一层的3个xgboost模型的输出作为第二层的xgboost模型的输入,整体构成分层预测系统。
进一步,步骤d中,利用粒子群算法优化分层预测系统参数,包括:
步骤d1:初始化分层预测系统中各个xgboost模型的参数,参数集合即为粒子;
步骤d2:设定粒子群算法的适应度函数,计算公式如下:
式中,fitness表示适应度函数,mape表示平均绝对百分比误差;
步骤d3:计算粒子适应度,根据适应度更新粒子,若达到最大迭代次数或适应度的增量小于给定阈值,则结束迭代,输出参数优化结果,否则重复步骤d3。
本发明具有以下有益效果:
1.本发明的一种基于多xgboost模型融合的母线负荷预测方法,将多个xgboost模型以分层的形式进行模型融合,构成分层预测系统,强化了学习效果。相较于单个模型,分层预测系统具有更好的预测精度。
2.本发明的一种基于多xgboost模型融合的母线负荷预测方法,构建的分层预测系统采用粒子群算法优化系统参数,有效解决了系统参数较多难以配置的问题,使得所提方法具备良好的实用价值。
附图说明
图1是本发明方法的实现流程图;
图2是本发明方法中分层预测系统的示意图;
图3是本发明方法中粒子群算法优化分层预测系统参数的实现流程图。
具体实施方式
下面结合附图对本发明所提方法进行详细阐述。
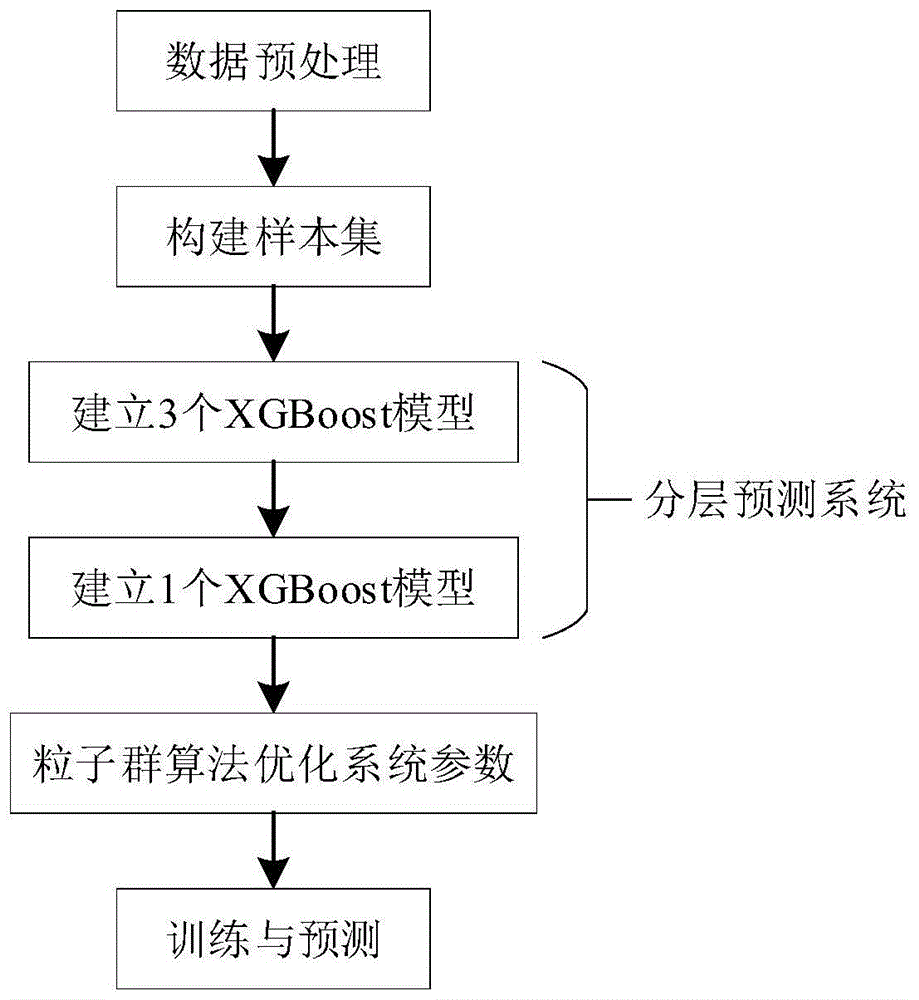
图1为本发明所提方法的实现流程图。如图1所示,包括以下步骤:
步骤a:对母线负荷数据及其相关数据进行数据预处理;
步骤b:构建样本集,划分训练集与测试集;
步骤c:构建分层预测系统,共2层,第一层为3个xgboost模型,第二层为1个xgboost模型;
步骤d:利用粒子群算法优化分层预测系统参数;
步骤e:应用分层预测系统进行训练与预测。
进一步,步骤a中,对母线负荷数据及其相关数据进行数据预处理,包括:
步骤a1:获取母线负荷数据及其相关数据,相关数据包括日期类型、时刻、气象条件等;
步骤a2:采用线性插值法填补母线负荷数据中的少量缺失值,并对填补后的母线负荷数据进行归一化;
步骤a3:对日期类型、时刻、风速、降雨量等数据进行独热编码,对温度、湿度等数据进行归一化处理。
特别地,步骤a2中,采用线性插值法填补母线负荷数据中的少量缺失值,线性插值法的计算公式如下:
式中,p指t时刻缺失的母线负荷数据的填补值,p0指t时刻之前t0时刻已知的母线负荷值,p1指t时刻之后t1时刻已知的母线负荷值。对于母线负荷数据中存在少量缺失值的情况,采用线性插值法可以快速、简单地解决该问题,避免数据缺失造成的不良影响。
特别地,步骤a2和步骤a3中,对母线负荷数据和温度、湿度等数据进行归一化处理,归一化方法为最大最小归一化,转换公式如下:
式中,x指待归一化的数据,xmax为待归一化的数据中的最大值,xmin为待归一化的数据中的最小值,x*为归一化后的数据。归一化有助于模型更好地利用数据。
进一步,步骤c中,构建分层预测系统,其结构示意图如图2所示,第一层为3个xgboost模型,第二层为1个xgboost模型,包括:
步骤c1:建立3个xgboost模型,以并行方式分布,用于一次学习,3个xgboost模型的输出为母线负荷一次预测值;
步骤c2:建立1个xgboost模型,顺序连接在3个xgboost模型之后,即以第一层的3个xgboost模型的输出作为第二层的xgboost模型的输入,整体构成分层预测系统。
为了验证本发明的有效性,在本实施例对比了不同数量模型融合的分层预测系统与单一xgboost模型的预测精度,结果如下表所示,其中多xgboost模型融合(n+1)表示第一层为n个xgboost、第二层为1个xgboost模型的分层预测系统,其中n=2,3,4,5。结果显示,多xgboost模型融合的预测精度高于单一xgboost模型的预测精度,且第一层为3个xgboost、第二层为1个xgboost的分层预测系统的预测精度最高,说明了本发明方法的有效性。
特别地,步骤c中,构建分层预测系统的基本模型为xgboost模型。xgboost是基于梯度提升技术实现的机器学习算法,其是由多个分类与回归树(cart)组合而成。对于一个具有n个样本和m个特征的给定数据集d={(xi,yi)}(|d|=n,xi∈rm,yi∈r),其中xi为具有m维特征的样本向量,yi为与xi对应的实际值,r为实数集。采用由k棵cart集成的xgboost模型预测输出,如式(3)所示,
式中,γ={fk(xi)=ωq(xi)}(q:rm→t,ω∈rt)是cart的函数空间,fk(·)表示第k棵树。q表示树结构,t表示叶结点的数量,每个fk都对应一个独立的树结构q与叶权重ω。为了将开棵树有效组合构成xgboost,要将式(4)所示的正则化目标函数l最小化。
式中,
xgboost模型的建立是迭代地添加树的过程,
对式(5)采用二阶泰勒展开,展开结果如式(6)所示。
式中,
定义ij={i|q(xi)=j}为叶结点j的样本集。将正则项ω展开,式(7)改写为式(8),
对于某一树结构q(x),令式(8)对叶结点j的权重ωj求偏导可获得其最优权重
式(10)为评价树结构q的评分函数,该函数值越小,说明树的结构越好。至此,xgboost模型建立完成。
进一步,步骤d中,粒子群算法优化分层预测系统参数,其流程图如图3所示,包括:
步骤d1:初始化分层预测系统中各个xgboost模型的参数,参数集合即为粒子;
步骤d2:设定粒子群算法的适应度函数,计算公式如下:
式中,fitness表示适应度函数,mape表示平均绝对百分比误差。
步骤d3:计算粒子适应度,根据适应度更新粒子,若达到最大迭代次数或适应度的增量小于给定阈值,则结束迭代,输出参数优化结果,否则重复步骤d3。
- 还没有人留言评论。精彩留言会获得点赞!