快速检索方法及系统与流程
[0001]
本发明属于自然语言处理信息检索领域,特别是涉及一种快速检索方法及系统。
背景技术:
[0002]
随着互联网技术的飞速发展,数据成为信息传播的重要载体。在人机对话领域,对于海量的数据检索,传统的方法具有较高的时间复杂度,在某些实时性要求较高的场景中,显然不满足要求,因此,构建一种快速检索方法显得尤为重要。
技术实现要素:
[0003]
本发明针对现有技术存在的问题和不足,提供一种新型的快速检索方法及系统。
[0004]
本发明是通过下述技术方案来解决上述技术问题的:
[0005]
本发明提供一种快速检索方法,其特点在于,其包括以下步骤:
[0006]
s1、将海量的待检索的用户提问文本进行预处理,将预处理后的用户提问文本进行文本量化表示,预处理过程包括分词和去停用词;
[0007]
s2、根据文本量化后的量化结果构建n维空间,其中n>=100;
[0008]
s3、在n维空间中随机选取n个点,基于n个点构建n维空间的分割超平面及分割超平面的垂直平分面;
[0009]
s4、重复执行步骤s3直到分割的区域中剩下m个点,m≤n;
[0010]
s5、构建二叉树,建立二叉树索引;
[0011]
s6、将检索文本进行分词、去停用词、文本量化表示处理;
[0012]
s7、根据二叉树结构进行检索遍历直到叶子节点,得到检索文本的相似文本数据,计算检索文本与每一相似文本数据的相似度,取相似度最高的相似文本数据;
[0013]
s8、基于相似度最高的相似文本数据在数据库中进行检索,得到相似度最高的相似文本数据的最终答案,最终答案作为检索本体的回答。
[0014]
较佳地,在步骤s1中,利用word2vec对预处理后的用户提问文本进行文本量化。
[0015]
较佳地,在步骤s8中,数据库采用mysql数据库。
[0016]
本发明还提供一种快速检索系统,其特点在于,其包括处理量化模块、空间构建模块、平面构建模块、调用模块、索引构建模块、预处理模块、计算模块和检索模块;
[0017]
处理量化模块用于将海量的待检索的用户提问文本进行预处理,将预处理后的用户提问文本进行文本量化表示,预处理过程包括分词和去停用词;
[0018]
空间构建模块用于根据文本量化后的量化结果构建n维空间,其中n>=100;
[0019]
平面构建模块用于在n维空间中随机选取n个点,基于n个点构建n维空间的分割超平面及分割超平面的垂直平分面;
[0020]
调用模块用于重复调用平面构建模块直到分割的区域中剩下m个点,m≤n;
[0021]
索引构建模块用于构建二叉树,建立二叉树索引;
[0022]
预处理模块用于将检索文本进行分词、去停用词、文本量化表示预处理;
[0023]
计算模块用于根据二叉树结构进行检索遍历直到叶子节点,得到检索文本的相似文本数据,计算检索文本与每一相似文本数据的相似度,取相似度最高的相似文本数据;
[0024]
检索模块用于基于相似度最高的相似文本数据在数据库中进行检索,得到相似度最高的相似文本数据的最终答案,最终答案作为检索本体的回答。
[0025]
较佳地,处理量化模块用于利用word2vec对预处理后的用户提问文本进行文本量化。
[0026]
较佳地,数据库采用mysql数据库。
[0027]
在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。
[0028]
本发明的积极进步效果在于:
[0029]
本发明对于海量数据检索,通过构建树形结构,提高数据检索的速度。
附图说明
[0030]
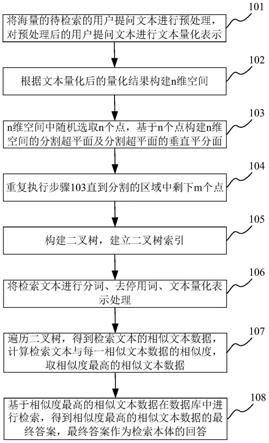
图1为本发明较佳实施例的快速检索方法的流程图。
[0031]
图2为本发明较佳实施例的快速检索系统的结构框图。
具体实施方式
[0032]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0033]
如图1所示,本实施例提供一种快速检索方法,其包括以下步骤:
[0034]
步骤101、将海量的待检索的用户提问文本进行预处理,利用word2vec对预处理后的用户提问文本进行文本量化表示,预处理过程包括分词和去停用词。
[0035]
步骤102、根据文本量化后的量化结果构建n维空间,其中n>=100。
[0036]
步骤103、在n维空间中随机选取n个点,基于n个点构建n维空间的分割超平面及分割超平面的垂直平分面。
[0037]
步骤104、重复执行步骤s3直到分割的区域中剩下m个点,m≤n。
[0038]
步骤105、构建二叉树,建立二叉树索引。
[0039]
步骤106、将检索文本进行分词、去停用词、文本量化表示处理。
[0040]
步骤107、根据二叉树结构进行检索遍历直到叶子节点,得到检索文本的相似文本数据,计算检索文本与每一相似文本数据的相似度,取相似度最高的相似文本数据。
[0041]
步骤108、基于相似度最高的相似文本数据在mysql数据库中进行检索,得到相似度最高的相似文本数据的最终答案,最终答案作为检索本体的回答。
[0042]
如图2所示,本实施例还提供一种快速检索系统,其包括处理量化模块1、空间构建模块2、平面构建模块3、调用模块4、索引构建模块5、预处理模块6、计算模块7和检索模块8。
[0043]
处理量化模块1用于将海量的待检索的用户提问文本进行预处理,利用word2vec对预处理后的用户提问文本进行文本量化表示,预处理过程包括分词和去停用词。
[0044]
空间构建模块2用于根据文本量化后的量化结果构建n维空间,其中n>=100。
[0045]
平面构建模块3用于在n维空间中随机选取n个点,基于n个点构建n维空间的分割超平面及分割超平面的垂直平分面。
[0046]
调用模块4用于重复调用平面构建模块直到分割的区域中剩下m个点,m≤n。
[0047]
索引构建模块5用于构建二叉树,建立二叉树索引。
[0048]
预处理模块6用于将检索文本进行分词、去停用词、文本量化表示预处理。
[0049]
计算模块7用于根据二叉树结构进行检索遍历直到叶子节点,得到检索文本的相似文本数据,计算检索文本与每一相似文本数据的相似度,取相似度最高的相似文本数据。
[0050]
检索模块8用于基于相似度最高的相似文本数据在mysql数据库中进行检索,得到相似度最高的相似文本数据的最终答案,最终答案作为检索本体的回答。
[0051]
本发明对于海量数据检索,通过构建树形结构,提高数据检索的速度。
[0052]
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这些仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1