一种基于孤立森林算法的销量异常值检测方法与流程
本发明涉及大数据分析技术领域,特别涉及一种基于孤立森林算法的销量异常值检测方法。
背景技术:
如何从有限的数据中挖掘出尽可能多的信息一直是进行大数据分析和建模的目标所在,而异常值检测方向也是大数据分析和研究的重点之一,通过对某种商品的每日销量进行异常值检测,能够更好地发现商品销量的趋势,同时也能更好地对出现异常销量的日期进行规律性的探索,更加有针对性地从业务上对出现异常销量的原因进行探究和分析,从而达到指导业务方向,提高生产效率的目的。
目前市场上的销量异常检测方法大多有两种:第一种是通过人为的筛选,它的缺点是非常耗费人力成本,并且容易出错。第二种是使用简单的计算公式设定阈值来进行异常值检测,它的缺点是准确率较低。
技术实现要素:
本发明的目的是克服上述背景技术中不足,提供一种基于孤立森林算法的销量异常值检测方法,使用基于统计学的孤立森林算法,结合销量数据构建异常值检测系统,能够以较高的准确率自动检测出销量数据中的异常值,在节省了人力成本的同时也提高了检测准确率,很好的解决了上面所述的目前市场上的销量检测系统的问题。
为了达到上述的技术效果,本发明采取以下技术方案:
一种基于孤立森林算法的销量异常值检测方法,包括以下步骤:
a.使用python中pandas模块读取销量数据;
b.对读取的数据进行数据清洗;
c.将清洗后的数据使用pandas.sample方法进随机抽样;抽样的目的是为了使每个树模型有差异性,从而使最终的数据结果更加准确;
d.对每个抽样的数据集建立一个树模型;
e.使用公式
f.依次计算销量数据中每一个样本点的异常概率,并输出异常值。
进一步地,所述步骤b包括:
b1.使用python中pandas模块dropna方法去除销量数据中的空值;
b2.将销量数据按日期进行排序,完成数据清洗过程得到目标数据集。
进一步地,所述步骤c具体为对清洗后的数据使用pandas.sample方法进行有放回采样,且每次采样30%的数据集。
进一步地,所述步骤d包括:
d1.建立一个node结点类用来保存树中的每个结点;
d2.对经过结点的样本取值进行随机分割;
d3.在build_tree方法中将每个结点类使用递归的方式连接起来形成一棵树结构。
进一步地,所述步骤f中,当样本的异常概率大于0.5时,便将其判定为异常值。
进一步地,所述步骤f中,对于一个样本点,如果超过半数的树模型都判定为异常值,则就将该样本点作为一个异常值输出。
本发明与现有技术相比,具有以下的有益效果:
本发明的基于孤立森林算法的销量异常值检测方法,通过孤立森林算法,可以以较高的效率和准确率找出销量数据中的异常值,以便后续针对异常值进行业务分析,并且算法能够根据数据分布的变化自动调整判定异常值的阈值,能够在数据规模越来越大的情况下依然保持较高的检测准确率,解决了现有的销量异常值检测系统存在的过于笼统和准确率不佳的问题。
附图说明
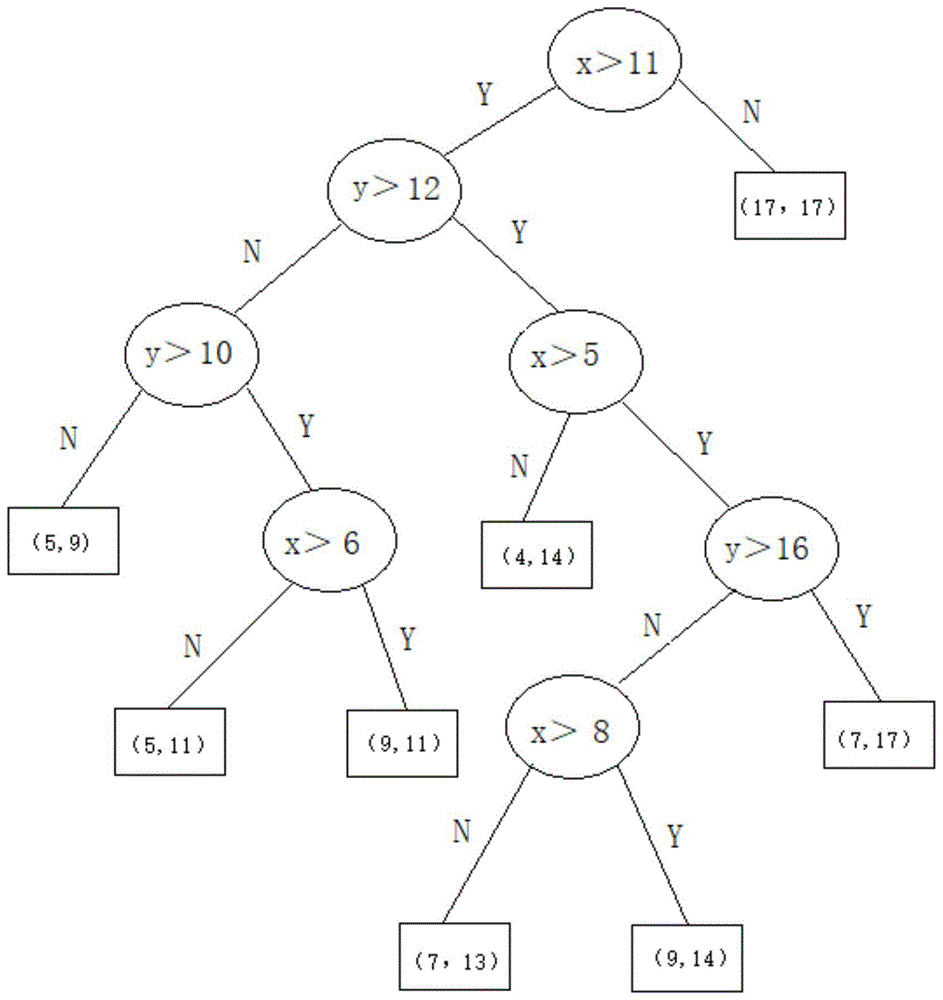
图1是本发明的一个实施例中建立的数模型的示意图。
图2是本发明的一个实施例中对结点进行随机分割的示意图。
具体实施方式
下面结合本发明的实施例对本发明作进一步的阐述和说明。
实施例:
实施例一:
孤立森林(isolationforest)是一种异常点检测算法,主要是利用集成学习的思路来做异常点检测,它通过对数据进行采样后建立多个树结构的模型来对数据进行随机分割,在这种随机分割的策略下,异常点通常具有较短的路径,也就是说,那些密度很高的簇是需要被切分很多次才能被孤立,但是那些密度很低的点很容易就可以被孤立。对于销量数据而言,使用孤立森林算法能够提取出肉眼不容易发现的异常值,对比传统的人工筛选方式更加高效和准确。
本实施例中公开了一种基于孤立森林算法的销量异常值检测方法,具体利用孤立森林算法拟合目标销量数据,以较高准确率输出销量的异常点,从而达到检测异常值的目的,解决了对于销量异常值检测系统而言存在的过于笼统和准确率不佳的问题,具体包括以下步骤:
步骤1.收集销量数据,本实施例具体是使用python中pandas模块读取销量数据。
步骤2.对读取的数据进行数据清洗,从而去除因格式或采集错误产生的错误数据。
本实施例中具体为先使用python中pandas模块dropna方法去除销量数据中的空值,然后将销量数据按日期进行排序,完成数据清洗过程得到目标数据集。
步骤3.将清洗后的数据使用pandas.sample方法进随机抽样,抽样的目的是为了使每个树模型有差异性,从而使最终的数据结果更加准确。
本实施例中具体为对清洗后的数据使用pandas.sample方法进行有放回采样,且每次采样30%的数据集。
步骤4.如图1所示,对每个抽样的数据集建立一个树模型,即用采样的数据集传入bulid_tree方法构建一棵树模型,在树模型中每个结点node对数据的取值进行随机划分,重复上述过程建立20-25棵树结构。
本实施例中具体包括:
步骤4.1.建立一个node结点类用来保存树中的每个结点;
步骤4.2.对经过结点的样本取值进行随机分割;
步骤4.3.在build_tree方法中将每个结点类使用递归的方式连接起来形成一棵树结构。
步骤5.使用公式
上述异常概率其实也就是树模型中各个样本点距离根节点的距离,因为在树模型中各个结点是随机分割的,如图2所示,密度越低的样本被分割的次数就会越少,对应的距离根节点的距离就越近,它是异常点的概率就越大。
步骤6.依次计算销量数据中每一个样本点的异常概率,并输出异常值。
本实施例中,具体设定当样本的异常概率大于0.5时,便将其判定为异常值,依次计算销量数据中每一个样本点的异常概率,对于一个样本点,如果超过半数的树模型都判定为异常值,则就将该样本点作为一个异常值输出,最后便可输出所有的销量异常值。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!