基于欧式距离的自适应集成的不平衡数据分类方法与流程
本发明属于人工智能领域,具体说是一种基于欧式距离的自适应集成的不平衡数据分类方法。
背景技术:
不平衡数据是指训练样本中一个类别的样本或多个类别的样本与其他类别样本数量相差很大的情况。根据研究报告,类别不平衡问题发生在现实世界各种各样的领域中,如面部年龄估计,检测卫星图像漏油,异常检测,识别欺诈性信用卡交易,软件缺陷预测和图像标注等。因此,研究人员非常重视数据不平衡问题并举办了几次专题研讨会和会议,如人工智能促进协会(aaai)2000,国际机器学习会议(icml)2003,以及2004年知识发现和数据挖掘(sigkdd)探索acm特别兴趣小组。
对于二分类不平衡问题,学习样本通常分为多数类和少数类。一般来说,人们对少数类样本的关注程度要超过多数类样本,比如将信用卡欺诈交易识别成正常交易的代价要比信用卡正常交易识别成欺诈交易代价高得多,因为后者可以通过工作人员联系信用卡持有人确认交易是否由本人发起的。但是少数类样本的数量远远低于多数类样本数量这种情况带过来的后果可能非常严重。由于大多数传统的分类算法如决策树,k-最近邻和ripper倾向于生成最大化整体分类准确性的模型,少数类样本是通常被忽略的。例如,对于只有1%的样本属于少数类的数据集,即使模型将所有样本分类为多数类,它仍然可以达到99%的总体准确度,用这种高准确度的分类器会将想要准确分类的少数类错误分类。
目前应用于机器学习和数据挖掘领域的集成学习方法在不平衡数据分类方面的实际应用越来越多被提出来,但大多数该类算法只能有限提高不平衡数据分类的预测精度,每个基础分类器都是局部区域的专家,没有考虑到每个基础分类器对于不同的测试样本的分类能力是不同的,将这些性能较差的基础分类器参与最终集成会影响集成模型的泛化能力,并且产生用于基础分类器学习的子集应该是多样的,保证基础分类器的多样性,同时大多数集成学习的集成规则都是通过多数类投票确定的,未考虑训练样本和测试样本之间的关系,即时优化后的基础分类器给出的预测结果也得不到更进一步的提高。
技术实现要素:
为解决集成学习中子分类多样性不足、未考虑性能较差基础分类器和集成规则设计的问题,本申请提出一种基于欧式距离的自适应集成的不平衡数据分类方法,提高不平衡数据分类精度。
为实现上述目的,本发明的技术方案为:基于欧式距离的自适应集成的不平衡数据分类方法,具体包括如下步骤:
步骤一、数据预处理,得到多样性平衡子集;
步骤二、在m个平衡子集上采用同样的分类学习算法得到m个同质分类器构建候选分类器池;
步骤三、在候选分类器池中预选择基础分类器,将不具有少数类样本能力的分类器删除;
步骤四、采用动态选择算法从步骤三筛选得到的分类器池中将测试样本周围区域样本分类能力强的候选子分类器挑选出来构成基础分类器集合;
步骤五、采用一种基于距离的自适应集成规则将选择出的基础分类器集合对于测试样本的预测结果输出。
进一步的,在步骤一中,对数据预处理:包括对训练集随机平衡获得的平衡子集,验证集以及测试集;具体步骤为:
①按照训练集strain,验证集sva和测试集样本stest数量比例为a:b:c,在原始数据集中划分样本,并且保证在划分后训练集,验证集和测试集样本内的多数类与少数类的比例与原始数据集中多数类与少数类的比例保持一致;
②按照公式(1)随机指定一个随机数numrand;
numrand=smin+rand(0,1)*(smax-smin)(1)
其中smin为训练集strain中少数类样本数量,rand(0,1)是0和1之间的随机数,smax是训练集strain中多数类样本数量;
③在训练集strain多数类样本中随机拿取不放回样本直至新组成的样本达到样本数量为numrand,同时按照公式(2)对少数类样本进行过采样生成新的样本z加入少数类样本中,重复过采样直到加入后的少数类样本个数为numrand,将新组成的多数类样本和过采样后的少数类样本合并则得到一个平衡子集;
z=βp+(1-β)q(2)
其中p,q是strain中少数类样本,β是0到1之间的随机数;
④重复步骤②和③直到获得m个平衡子集。
进一步的,在步骤二中,构建候选分类器池,具体步骤:对步骤一获得的m个子集均应用同样的分类学习算法得到m个同质基础分类器组成候选分类器池。
进一步的,在步骤三中,需要对候选分类器池中的基础分类器预选择;具体步骤为:
①对当前在测试集stest中待分类的样本xq,在验证集sva中计算它的k个最近邻居,若k个最近邻居中存在不同类别的样本,则记录当前的k个邻居为ψ;若k个最近邻居中存在同一类别的样本,则进入步骤四;
②将获得的ψ作为输入,候选分类器池中的每个基础分类器hi对于抹掉标签的ψ预测得到输出yp;
③比较基础分类预测输出yp和真实ψ的标签y,如果存在不能同时至少正确分类一组少数类和多数类的样本的基础分类器给予删除;删除后候选分类器中的基础分类器为n个。
进一步的,在步骤四中,需要对预选择后的候选分类器进行动态选择,具体步骤为:
①对当前在测试集stest中待分类的样本xq,在验证集sva中计算它的k个最近邻居,将k个样本记为£;
②将获得的£作为输入,候选分类器池中的每个基础分类器hi对于抹掉标签的£预测得到输出yout;针对预测输出yout和真实的标签y,根据公式(3)计算每个基础分类器的能力权重:
其中i()为指示函数,θj为第j个样本类别的权值系数,θj定义如下:
③在计算完能力权重后按照数值大小排序,从n个基础分类器中取前p%构成基础分类器集合c'。
进一步的,在步骤五中,对选择得到分类器集合c'给出对当前待分类样本的预测集成输出,具体步骤为:
①按照公式(4)和(5)分别计算出参数r1和r2
其中t为集合c'中的基础分类器数量,pi1和pi2分别对应于第i个分类器中对于测试样本给出的少数类和多数类的概率,di1和di2分别对应于测试样本到第i个基础分类器中少数类和多数类的训练样本的平均欧式距离,α是自适应参数,需要根据不同的分类算法确立;
在计算距离之前,需要按公式(6)对样本进行归一化:
其中
②比较参数r1和r2的值,若r1>r2,则当前样本分类为少数类,反之则为多数类;
重复步骤三、步骤四和步骤五到所有测试集样本stest中的样本分类完成。
本发明通过以上方法,可以取得如下效果:
(1)使用随机平衡方法获得的子集上具有多样性的特点,保证在其上建立的基础分类器具有多样性。
(2)加入了预选择方法,保证了下一步动态选择算法可以更好更快的选择基础分类器。
(3)运用动态选择算法为每个待分类样本选择能力较强的基础分类器,避免了将性能较差的基础分类器带入最终的决策输出引起的泛化性能下降问题。
(4)提出的集成规则综合了每个基础分类器的输出,并且考虑到训练集和测试集之间的关系,这个关系就是待分类样本更应该分类到距离最近的样本类别中。采用该集成规则可以有效将多个输出结果值合并集成输出,提高集成输出精度。
附图说明
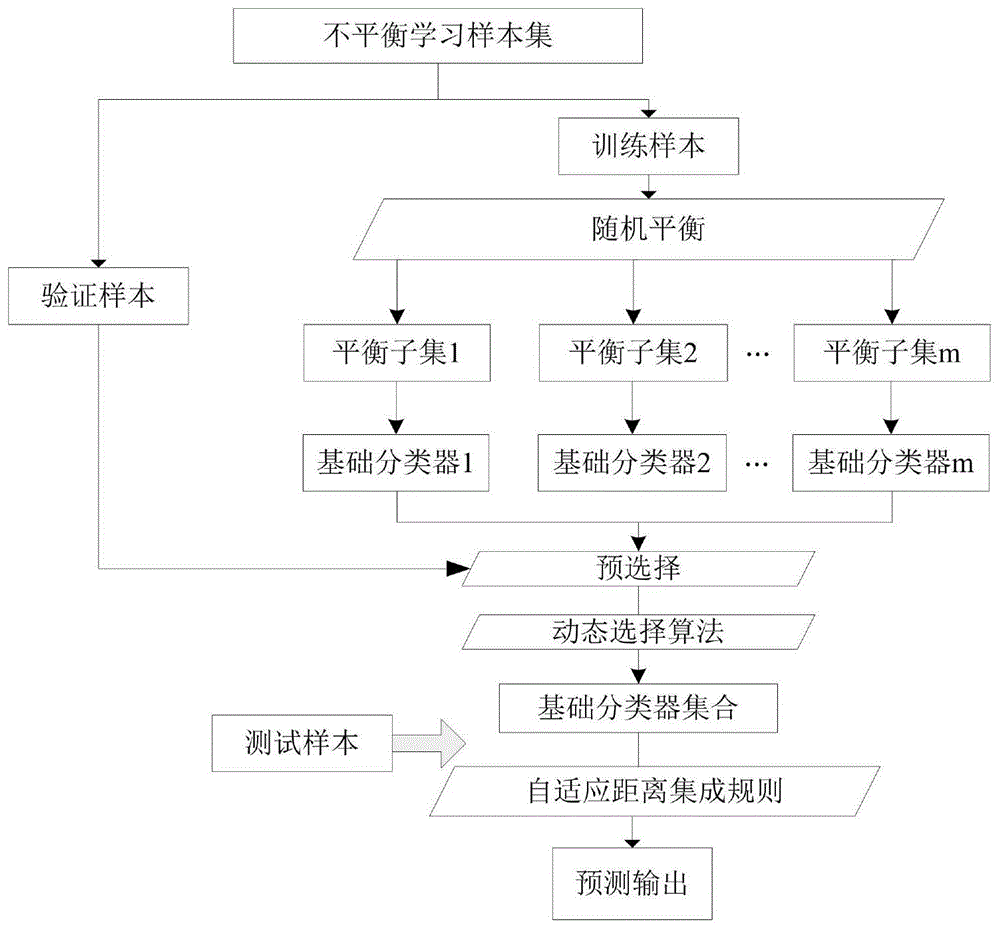
图1为本发明的实现流程图。
具体实施方式
参考图1,它是本发明实现步骤的流程图,结合该图对本发明的实施过程作详细的说明。本发明的实施例是在以本发明技术方案为前提下进行实施的,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述实施例。
一种基于欧式距离的自适应集成的不平衡数据分类方法,包括候选分类器池的生成、动态选择分类能力较强的基础分类器集合以及基础分类器的自适应集成输出,依次包括以下步骤:
(1)数据预处理,得到训练集,验证集和测试集;并在训练集中应用随机平衡方法得到m个平衡子集;
(2)在这m个平衡子集上采用同样的分类学习算法得到m个同质分类器构建候选分类器池中;
(3)在候选分类器池中预选择基础分类器,将不具有分类少数类的样本能力的分类器删除;
(4)采用动态选择算法从步骤(3)中筛选得到的分类器池中将测试样本周围区域样本分类能力最强的候选子分类器挑选出来;
(5)采用一种基于距离的自适应集成规则将选择出的基础分类器对于测试样本的预测结果输出;
采用随机平衡方法来获得多样性子集,随机指定多数类样本数量和少数类样本数量之间的一个值,对多数类样本进行欠采样而对少数类样本进行过采样,达到数据平衡的目的,重复上述步骤直到生成的子集数量达到想要的子集数量。
为了减少候选分类器的数量提高动态选择算法的效率并且更利于动态选择算法选取能力更强的基础分类器,利用预选择方法删除一部分基础分类器,具体方法是,在验证集中取当前待测试样本的k个最近邻居,将这k个最近邻居作为输入,候选分类器池中的每个子分类器对其进行预测输出,删掉不具有区分少数类样本能力的基础分类器。
通过测试样本最近邻的验证集分类情况来计算每个基础分类器分类能力,其具体方法为,在验证集中取当前测试样本的k个最近邻居,分别用候选分类器池中的每个基础分类器对这k个最近邻居进行预测输出,将正确分类少数类别能力较强同时又能保证总体正确率的基础分类器选择出来,区别于传统的动态选择算法,传统的选择算法设计大都在保证总体正确率的情况下进行的,但这在不平衡样本中选择出来的基础分类器会偏向于多数类。
每个基础分类器都会给出待预测样本的输出,不仅考虑了每个基础分类器的输出,同时也考虑了待分类样本和训练样本之间的关系,公式为:
其中t为基础分类器数量,pi1和pi2分别对应于第i个分类器中对于测试样本给出的类别1和类别2的概率,di1和di2分别对应于测试样本到第i个基础分类器中类别1和类别2的训练样本的平均欧式距离,α是自适应参数,需要根据不同的分类算法确立。
若r1>r2,则当前样本分类为类别1,反之则为类别2。
本实施例采用了一个公开的标准不平衡数据库keel所收集的ecoli046vs5数据集。ecoli046vs5数据集总共包含203个样本,每个样本具有7种属性,其中20个少数类样本,183个多数类样本。不平衡度为9.15。具体的不平衡数据分类过程如下:
(1)按照训练集中样本数量,验证集中样本数量以及测试集中样本数量为8:1:1的比例划分原始不平衡学习样本集,并保证划分后的数据集中多数类样本和少数类样本数量的比例与原始不平衡学习样本集的比例一致。
(2)在训练集上随机平衡具体步骤如下:
①按照公式(1)随机指定一个随机数numrand;
②对训练集strain中少数类样本进行按照公式(2)过采样达到样本个数为numrand,对多数类样本进行欠采样达到样本个数为numrand,得到一个平衡子集;
③重复步骤①和②直到获得100个平衡子集。
(3)在这100个平衡子集上采用决策树算法得到100个同质分类器构建候选分类器池中;
(4)对步骤(3)获得的基础分类器执行预选择方法,具体步骤如下:
①对当前在训练集stest中待分类的样本xq,在验证集sva中计算它的7个最近邻居,若7个最近邻居中存在不同类别的样本,则记录当前的7个邻居为ψ。若7个最近邻居中存在同一类别的样本,则进入步骤(5);
②将获得的ψ作为输入,候选分类器池中的每个基础分类器hi对于抹掉标签的ψ预测得到输出yp;
③比较基础分类预测输出yp和真实的ψ的标签y,如果存在不能同时至少分类正确分类一组少数类和多数类的样本的基础分类器给予删除。删除后候选分类器中的基础分类器为n个。
(5)对步骤(4)获得到的n个基础分类器进行动态选择,具体步骤如下:
①对当前在训练集stest中待分类的样本xq,在验证集sva中计算它的7个最近邻居,将7个样本记为£;
②将获得的£作为输入,候选分类器池中的每个基础分类器hi对于抹掉标签的£预测得到输出yout。针对预测输出yout和真实的标签y,根据公式(3)计算每个基础分类器的能力权重;
③在计算完能力权重后按照数值大小排序,从n个基础分类器中取前15%构成基础分类器集合c'。
(6)为了确定公式(4)-(5)中的α值,利用验证集对不同的α值进行交叉验证,最终得到在运用决策树情况下α值为1,将α值带入公式(2)-(3)分别计算r1和r2的值并比较,若r1>r2,则当前样本分类为少数类,反之则为多数类。
重复步骤(4)(5)和步骤(6)直到所有测试集样本stest中的样本分类完成。
为了更好的说明算法的有效性,仅用决策树算法和smote处理后使用决策树算法做为算法对比,同时为了量化最后的结果输出,使用auc为算法指标。
表1:不同方法对ecoli046vs5数据集的分类结果比较
通过表1可以看出,在基于ecoli046vs5不平衡数据分类实验中,本申请提出的基于欧式距离的自适应集成的不平衡数据分类方法得到的auc值为0.9192,相比于其它的典型的处理方法在分类性能上有了较大的提高。实验结果说明了该方法能有效的结合动态选择算法和集成规则设计各自的优势,可有效提高不平衡数据的预测精度和集成模型的泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!