基于多模型融合的电网故障抢修时长预测方法与流程
本发明属于模型预测领域,尤其涉及基于多模型融合的电网故障抢修时长预测方法。
背景技术:
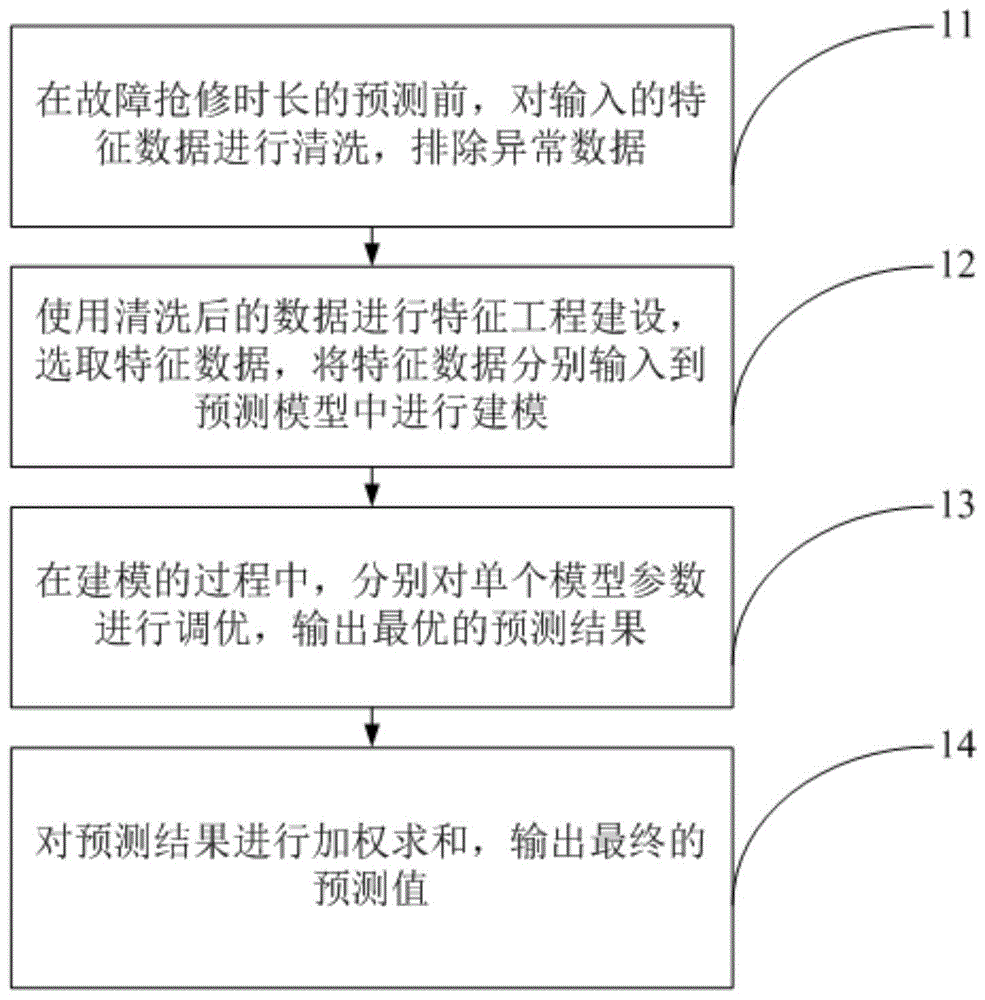
:电网故障的分析和预测是电网自动化和智能化中的重要一环。由于电网故障种类繁多、原因复杂,电网故障的分析和预测较为困难,尤其是对电网故障抢修时长的预测更加困难。随着智能电网的建设,调度自动化水平不断提高,信息采集系统的功能不断强大,已有众多学者展开对电网故障预测的研究。文献[1]综述了广泛应用于电网故障诊断的多种智能方法结合的故障诊断方法,包括基于专家系统、petri网、神经网络、贝叶斯网络等技术结合的诊断技术;文献[2]使用模型预测和溯因推理网络相结合的方法进行电网故障的预测,能在保护装置和断路器动作前进行故障定位,具有故障预警功能;文献[3]提出了一种基于长短期记忆网络lstm的故障时间序列预测方法,证明lstm在电网故障预测中相比传统方法更加准确。已有的研究多从电网内部收集的信息作为预测依据,如电压、电流、功率等指标,这些指标某种程度上反映了电网的运行状况,但忽略了天气、人为破坏等外部因素。技术实现要素:为了解决现有技术中存在的缺点和不足,本发明提出了基于多模型融合的电网故障抢修时长预测方法,能够使用多种机器学习方法进行建模,并将预测结果进行加权,融合多模型的优势特点,得到相较于单模型更为准确的预测结果。具体的,所述网故障抢修时长预测方法包括:在故障抢修时长的预测前,对输入的特征数据进行清洗,排除异常数据;使用清洗后的数据进行特征工程建设,选取特征数据,将特征数据分别输入到预测模型中进行建模;在建模的过程中,分别对单个模型参数进行调优,输出最优的预测结果;对预测结果进行加权求和,输出最终的预测值。可选的,所述预测模型包括xgboost、lightgbm以及lstm。可选的,当所述预测模型为xgboost、lightgbm的提升树模型时,所述将特征数据分别输入到预测模型中进行建模,包括:以分类树或回归树作为基分类器,以分类器构建过程中错误分类产生的残差作为损失函数,即通过拟合残差构造损失函数。假设初始提升树为f0(x)=0,则第m步的模型表达式如公式一所示fm(x)=fm-1(x)+t(xiθ)公式一,其中,fm-1(x)为当前模型,l为损失函数,通过经验风险极小化确定如公式二所示的下一棵树的参数θm:随着树的不断生成,损失函数不断下降,每一棵树学习的都是之前所有树的结论和残差。可选的,当所述预测模型为lstm的深度学习模型时,所述将特征数据分别输入到预测模型中进行建模,包括:确定长短期时记忆网络(longshort-termmemory,lstm)的门结构;基于已确定的门结构,建立最终输出数据与前一状态和当前状态的参数表达式ft=δ(wf·[ht-1,xt]+bf)公式三,it=δ(wi·[ht-1,xt]+bi)公式四,ot=δ(wo·[ht-1,xt]+bo)公式五,ht=ot×tanh(ct)公式八;公式三至公式五分别是遗忘门、输入门和输出门的计算公式,公式六至公式八是对细胞状态进行更新,公式八计算记忆单元最终的输出;其中δ为计算系数,xt是t时刻输入数据,ft是t时刻遗忘门输出,wf为遗忘门的权重,bf是遗忘门的计算参数,wi为输入门的权重,bi是输入门的计算参数,wo为输出门的权重,bo是输出门的计算参数,wc为输出层的权重,bc是输出层的计算参数,it为更新系数,ct是t时刻输出门输出,为t时刻的输出门预设输出,ot是t时刻输出门输出,ht-1为上一时刻的输出数据,ht为最终输出数据,tanh(·)为约束运算符,c为记忆单元的值。本发明提供的技术方案带来的有益效果是:从历史的故障抢修工单出发,依据多种内外部指标,对电网故障的抢修时长进行预测。首先,对电网故障数据进行数据清洗,进行电网故障数据分析,探究影响故障抢修时长的因素。使用多种机器学习方法进行建模,并将预测结果进行加权,融合多模型的优势特点。实验证明,多模型融合的故障抢修时长预测模型比单模型的预测结果更加准确。附图说明为了更清楚地说明本发明的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本申请实施例提出的基于多模型融合的电网故障抢修时长预测方法的流程示意图;图2为本申请实施例提出的平均温度与平均抢修时长关系示意图;图3为本申请实施例提出的故障发生时间区与平均抢修时长关系示意图;图4为本申请实施例提出的长短期记忆网络lstm的门结构;图5为本申请实施例提出的lightgbm模型的抢修时长预测结果;图6为本申请实施例提出的单个模型预测结果对比;图7为本申请实施例提出的多模型融合的抢修时长预测结果。具体实施方式为使本发明的结构和优点更加清楚,下面将结合附图对本发明的结构作进一步地描述。实施例一本文从历史的故障抢修工单出发,依据多种内外部指标,对电网故障的抢修时长进行预测。首先,对电网故障数据进行数据清洗,进行电网故障数据分析,探究影响故障抢修时长的因素。使用多种机器学习方法进行建模,并将预测结果进行加权,融合多模型的优势特点。实验证明,多模型融合的故障抢修时长预测模型比单模型的预测结果更加准确。具体的,如图1所示,所述网故障抢修时长预测方法包括:11、在故障抢修时长的预测前,对输入的特征数据进行清洗,排除异常数据;12、使用清洗后的数据进行特征工程建设,选取特征数据,将特征数据分别输入到预测模型中进行建模;13、在建模的过程中,分别对单个模型参数进行调优,输出最优的预测结果;14、对预测结果进行加权求和,输出最终的预测值。在实施中,本文研究数据来自电力系统服务热线——95598热线系统。主要数据是抢修人员现场抢修完毕后,反馈回系统的故障抢修工单。数据包括杭州市2016年3月至2019年2月所有故障抢修工单,共21万余条记录。除了内部电网故障数据外,还采集了公开的气象、地理、节假日等外部数据。故障反馈工单数据是由抢修人员手动输入的半结构化数据,需要将数据进行格式化处理。图2展示了数据的格式化过程,其中使用了命名体识别、实体对齐等自然语言处理技术。自然语言处理步骤包括命名实体识别、实体对齐以及实体消歧的步骤,而格式化数据的处理格式对象则具体包括报修时间、抢修部门、抢修时长、平均气温以及是否为节假日等信息。影响故障抢修时长的因素众多。为了发现影响抢修时长的相关因素,分析了包括环境因素(温度等天气状况)、抢修人因素(抢修队、抢修人等)、发生时间、故障所在位置、故障类型等。图2展示了平均气温与每天平均抢修时长的变化关系,这里的平均抢修时长是当天的总抢修时长除去总故障数。从图中可以发现,平均抢修时长与平均气温有很强的相关性,随着气温的上升平均抢修时长也呈上升的趋势。故障发生时间也会影响故障的抢修时长。为了探索故障发生时间对故障抢修时长的影响,将全天划分为5个时间段,分别为:0:00-8:00、8:00-12:00、12:00-16:00、16:00-20:00和20:00-24:00。从图3中可以看出,发生在凌晨以后的故障平均抢修时长较长,发生在白天的故障平均抢修时长较短。除了上述影响因素,还分析了不同故障类型、是否发生在节假日、发生区域、不同的抢修单位和抢修人等对抢修时长的影响。分析发现这些因素都会对抢修时长产生一定影响,因此可根据这些影响因素对故障的抢修时长进行预测。可选的,所述预测模型包括xgboost、lightgbm以及lstm。当所述预测模型为xgboost、lightgbm的提升树模型时,所述将特征数据分别输入到预测模型中进行建模,包括:以分类树或回归树作为基分类器,以分类器构建过程中错误分类产生的残差作为损失函数,即通过拟合残差构造损失函数。假设初始提升树为f0(x)=0,则第m步的模型表达式如公式一所示fm(x)=fm-1(x)+t(xiθ)公式一,其中,fm-1(x)为当前模型,l为损失函数,通过经验风险极小化确定如公式二所示的下一棵树的参数θm:随着树的不断生成,损失函数不断下降,每一棵树学习的都是之前所有树的结论和残差。在实施中,在深度学习技术出现以前的相当长一段时间内,以boosting技术为代表的集成学习方法一直是机器学习领域综合性能最为出众的算法之一。boosting技术是从弱学习算法出发,反复学习,得到一系列的弱分类器(基分类器),然后组合这些弱分类器,构成一个强分类器。基于树模型的提升算法被称为提升树(boostingtree),它以分类树或回归树作为基分类器,以分类器构建过程中错误分类产生的残差作为损失函数,即通过拟合残差构造损失函数。随着树的不断生成,损失函数不断下降,每一棵树学习的都是之前所有树的结论和残差。对于一般损失函数,优化比较困难,因此提出了更一般的提升树模型—梯度提升树(gradientboostingdecisiontree,gbdt),它使用负梯度代替残差,基分类器使用cart回归树。gbdt主要思想是利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值,拟合一个回归树。当前较为先进和出众的是lightgbm[7]和xgboost[8],它们都是基于梯度提升树技术改进实现的。本研究分别尝试了使用lightgbm和xgboost进行建模。当所述预测模型为lstm的深度学习模型时,所述将特征数据分别输入到预测模型中进行建模,包括:确定长短期时记忆网络(longshort-termmemory,lstm)的门结构;基于已确定的门结构,建立最终输出数据与前一状态和当前状态的参数表达式ft=δ(wf·[ht-1,xt]+bf)公式三,it=δ(wi·[ht-1,xt]+bi)公式四,ot=δ(wo·[ht-1,xt]+bo)公式五,ht=ot×tanh(ct)公式八;公式三至公式五分别是遗忘门、输入门和输出门的计算公式,公式六至公式八是对细胞状态进行更新,公式八计算记忆单元最终的输出;其中δ为计算系数,xt是t时刻输入数据,ft是t时刻遗忘门输出,wf为遗忘门的权重,bf是遗忘门的计算参数,wi为输入门的权重,bi是输入门的计算参数,wo为输出门的权重,bo是输出门的计算参数,wc为输出层的权重,bc是输出层的计算参数,it为更新系数,ct是t时刻输出门输出,为t时刻的输出门预设输出,ot是t时刻输出门输出,ht-1为上一时刻的输出数据,ht为最终输出数据,tanh(·)为约束运算符,c为记忆单元的值。在实施中,传统的前馈神经网络中,层与层之间的神经元是全连接的,层内部的神经元无连接。这种神经网络对存在前后依赖关系的序列数据是无能为力的。为此,具有特殊结构的循环神经网络(recurrentneuralnetwork,rnn)被提出,它可以保存序列间的前后关系。但是,循环神经网络很难通过反向传播算法来训练。主要的困难在于梯度消失和梯度爆炸问题。长短期时记忆网络(longshort-termmemory,lstm)对传统的循环神经网络结构进行了修改,通过“门”结构控制细胞状态,避免了消失梯度问题,保持了训练算法的稳定性。图4展示了lstm的门结构。其中x是输入数据,f是遗忘门门输出,o是输出门输出,h为最终输出数据,c为记忆单元的值。从图中可以看出lstm最终的输出数据不仅与当前状态有关,还与上一个状态存在关系。在t时刻,门结构接受上一时刻记忆单元的输出ht-1和当前时刻记忆单元的输入xt,与各自的权重矩阵w相乘,然后加上偏置向量,通过sigmoid函数产生一个0到1之间的值,对信息进行筛选,本研究尝试使用lstm对故障抢修时长进行预测,通过学习历史故障工单的抢修数据,对未来新故障数据进行预测。基于前述内容所建立的多模型融合的抢修时长预测模型如图5所示。在故障抢修时长的预测前,对输入的特征数据进行清洗,排除异常数据;使用清洗后的数据进行特征工程建设,找出适合特征最后分别输入到xgboost、lightgbm或者lstm中进行建模;在建模的过程中,分别对单个模型参数进行调优,输出最优的预测结果;最后,对预测结果进行加权求和,输出最终的预测值。实验结果与分析故障抢修反馈工单是抢修人员手动输入,这导致部分异常数据存在。在实验过程中,需要先对异常数据进行清洗。表1给出了抢修时长的统计分布情况。从表1中可以看出,未去除异常数据的原始数据中,均值为69.95分钟,最大值达到了44718分钟,即31天。由于少量极大异常数据的影响,导致的标准差非常大,达到了290,这显然是不合理的,需要过滤掉少量的异常数据。表1的第2、3列为分别过滤掉抢修时长超过1天和超过6小时的数据分布情况。可以发现,去除抢修时长超过6小时的数据,仍保留了96.5%的数据,但是数据的标准差从290.84下降到了58.47,下降了80%左右。过滤异常数据,有利于模型更好的发现数据分布规律,提高模型的准确率。表1异常数据清洗结果为了更精准的预测故障的抢修时长,尽可能减少潜在的未知因素对抢修时长预测的影响,将抢修时长以15分钟为单位进行重新计算,在预测时也以15分钟为单位进行预测。故障抢修时长的预测采用平均绝对误差(meanabsoluteerror[11],mae)作为主要的性能评价指标。模型训练完成后,可以使用测试集数据对模型进行验证。故障抢修时长的预测任务训练模型时使用的训练集样本为2019年1月1日-2019年2月17日数据,共194333个训练样本。测试数据为2019年2月18日的数据,共89个测试样本。模型训练时,分别对单个模型进行训练,并进行模型参数的调优。为了对比单个模型的建模效果,分别测试单个模型的预测效果。图5给出了lightgbm在测试样本的预测效果,从图中可以看出模型预测值和真实值在大部分趋势上是拟合的,部分抢修工单存在预测不准确的情况。图6给出了lightgbm、xgboost和lstm三种模型的预测结果对比,从图中可以看出lightgbm和lstm的预测效果相对较好,xgboost的预测值则比实际值整体偏小。通过实验发现,单个模型的预测能力有限。本文分别训练完三种算法后,需要将三种算法输出结果根据权重进行融合。根据多次实验结果,经过分析给出lightgbm、xgboost和lstm的权重分别为:0.65、0.15和0.2时输出的加权结果较好。图7给出了根据权重融合了3种模型的预测结果。为了对比个模型的预测性能,使用平均绝对误差mae对预测结果进行评价。表2给出了三种算法的性能对比。从表中可以看出,单个算法中lightgbm的效果最佳;而进行多模型的融合后,加权结果预测效果最好。由于时长的预测以15分钟为单位,预测最好结果的mae为1.15,对应的抢修时长误差大致为17.25分钟。算法类型平均绝对误差maelightgbm1.21xgboost1.52lstm1.23加权结果1.15表2不同模型的故障抢修时长预测误差随着电网信息化和智能化进程的推进,信息采集系统的功能不断强大,已有较多针对电网故障预测的研究。目前关于电网故障预测本身的预测较多,故障抢修时长的预测相对较少。本文以95598电力系统服务热线的故障抢修反馈工单为研究对象,分析了影响故障抢修时长的各种因素,分别使用xgboost、lightgbm和lstm三种模型进行抢修时长预测模型的建模。最后,根据实验结果对三种模型的预测结果进行加权融合。实验表明,多模型融合的抢修时长预测模型相比单模型更加准确,这可以为电力抢修调度的智能化提供更加有效地支撑。上述实施例中的各个序号仅仅为了描述,不代表各部件的组装或使用过程中的先后顺序。以上所述仅为本发明的实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1