一种基于AP聚类的远景年典型日负荷预测方法与流程
本发明属于电力系统分析领域,特别涉及一种基于ap聚类的远景年典型日负荷预测方法。
背景技术:
新一代综合能源电力系统是能源互联网的物理载体,是以电能为主体形式,在规划、建设和运行等过程中,对各种能源的产生、传输与分配(供能网络)、转换、存储、消费、交易等环节实施有机协调与优化,进而形成的能源产供消一体化系统。新一代综合能源电力系统是我国未来综合能源发展的必然趋势。同时,社会经济技术、升天环境约束等电网发展的外部环境发生剧烈变化,对特大型城市电网远景年电力需求预测提出挑战。
电力负荷预测的开展始于上世纪七十年代初。最早的电力负荷预测工作完全依靠预测人员的运行经验,没有科学的理论做指导,预测误差往往较大。随着电力行业的不断发展,电力系统日趋复杂,单纯地依靠人工预测己经远远不能满足预测的要求。因此,要求电力负荷预测更科学、更准确,极大地促发了电力负荷预测理论研究的开展。
电力系统是一个大规模的电力生产、输送、消费的复杂网络,电力生产和消费具有即时性的特点,且大规模的存储电力并不经济,为了实现电力系统的安全、经济、稳定地运行,这不仅需要提高饱和负荷预测的精度,更需要对电网做出更合理的规划。电力饱和负荷预测是电网规划中最为重要的基础性工作之一,电力饱和负荷预测的合理性与准确性直接影响着电网规划的质量,远景年目标网架规划对电网发展有高屋建瓴的指导意义。
技术实现要素:
为了使电网规划的投资更加经济,电网规划方案更加合理,这需要对远景年典型负荷的预测更精准。本发明的目的在于提供一种基于ap聚类的远景年典型日负荷预测方法。本发明根据历史日负荷数据,进行标幺化处理,并基于ap聚类算法对历史日负荷数据进行聚类,以此作为远景年的负荷特征。此外,基于远景年负荷的预测值,并结合聚类后的负荷特征,计算出远景年典型日负荷曲线,本文方法为远景年日负荷预测提供了有效的科学依据。
由于电网规划是以年为周期,负荷曲线往往是以小时为单位,这样导致建立电网规划模型时负荷数据量极大,求解十分困难。为了解决这一问题,本发明基于ap聚类算法对远景年典型日负荷进行建模,利用典型日负荷数据研究电网规划问题,大大降低了电网规划模型中的数据规模,进而解决了模型求解困难的问题。
具体技术方案包括以下步骤:
一种基于ap聚类的远景年典型日负荷预测方法,包括如下步骤:
s1、基于历史负荷曲线,选定n年日负荷曲线,得到日负荷数据样本集{l1,l2,...,l365×n};
s2、选定基准负荷数据,将365×n个日负荷数据样本除以基准负荷数据,得到负荷数据的标幺值;
s3、基于ap聚类算法(affinitypropagationclusteringalgorithm)对365×n个标幺化处理的历史日负荷数据样本进行聚类;
s4、基于聚类结果,得到h个类型,类型集合为w=[w1,w2,…,wh],根据第h类负荷中包含的日负荷曲线的数量与日负荷曲线总数量的比值,确定出各类负荷的权重向量m=[m1,m2,…,mh]。
s5、预测远景年电力负荷需求
所述s3步骤,对365×n个日负荷数据样本进行聚类步骤为:
3.1、根据日负荷数据样本集{l1,l2,...,l365×n},基于2-范数设置相似度矩阵f,表示两个数据之间的相似程度,f(i,j)为相似度矩阵中的元素,其物理含义为日负荷数据li与lj之间的相似程度,使用欧氏距离来计算,相似度值越大说明两类负荷之间的距离越近;
3.2、设置吸引信息矩阵r,r(i,k)为吸引信息矩阵中的元素,描述的是日负荷数据lk适合作为日负荷数据li的聚类中心的程度,表示负荷数据从li到lk的信息;
3.3、设置归属信息矩阵a,a(i,k)为归属信息矩阵中的元素,描述的是日负荷数据li选择日负荷数据lk作为聚类中心的适合程度,表示负荷数据从lk到li的信息;
3.4、设置t=1,开始进行第一次迭代计算,得到吸引信息矩阵r、设置归属信息矩阵a、相似度矩阵f初始值;
3.5、更新吸引信息矩阵,计算第t+1次的吸引信息矩阵rt+1(i,k),其计算公式为:
归属信息矩阵中,计算第t+1次的归属信息矩阵at+1(i,k),其计算公式为:当i≠k时,即
3.6、更新吸引信息矩阵和归属信息矩阵后,计算日负荷数据的聚类结果;
3.7、对3.5、3.6步骤进行迭代,如果日负荷数据的聚类经过数次迭代后聚类结果保持不变或者算法执行超过设定的迭代次数,则算法结束,得到h个类型,类型集合为w=[w1,w2,…,wh]。
所述s4步骤,各类负荷的权重计算方法为:
其中,ih为第h类负荷中包含的日负荷曲线的数量,365×n为选取历史日负荷曲线总数量。
所述s5步骤,远景年典型日负荷计算方法为:
其中,
与现有技术相比,本发明的有益效果是:
由于电网规划是以年为周期,负荷曲线往往是以小时为单位,这样导致建立电网规划模型时负荷数据量极大,求解十分困难,针对这一问题,本发明基于ap聚类算法对远景年典型日负荷进行建模,利用典型日负荷数据研究电网规划问题,大大降低了电网规划模型中的数据规模,进而解决了模型求解困难的问题。
附图说明
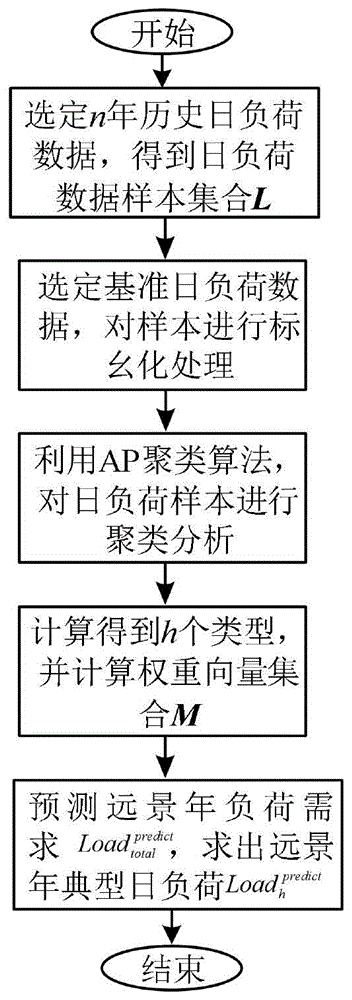
图1为本发明提供的一种基于ap聚类的远景年典型日负荷预测方法流程示意图;
具体实施方式
下面结合附图对本发明做出详细地说明:
如图1所示,本发明提供一种基于ap聚类的远景年典型日负荷预测方法,包括如下步骤:
步骤1基于历史负荷曲线,选定n年日负荷曲线,得到日负荷数据样本集{l1,l2,...,l365×n};
步骤2选定基准负荷数据,将365×n个日负荷数据样本除以基准负荷数据,得到负荷数据的标幺值;
步骤3基于ap聚类算法(affinitypropagationclusteringalgorithm)对365×n个标幺化处理的历史日负荷数据样本进行聚类;所述步骤3,利用ap聚类算法净负荷曲线进行聚类,具体包括:
3.1、根据日负荷数据样本集{l1,l2,...,l365×n},基于2-范数设置相似度矩阵f,表示两个数据之间的相似程度,f(i,j)为相似度矩阵中的元素,其物理含义为日负荷数据li与lj之间的相似程度,使用欧氏距离来计算,相似度值越大说明两类负荷之间的距离越近;
3.2、设置吸引信息矩阵r,r(i,k)为吸引信息矩阵中的元素,描述的是日负荷数据lk适合作为日负荷数据li的聚类中心的程度,表示负荷数据从li到lk的信息;
3.3、设置归属信息矩阵a,a(i,k)为归属信息矩阵中的元素,描述的是日负荷数据li选择日负荷数据lk作为聚类中心的适合程度,表示负荷数据从lk到li的信息;
3.4、设置t=1,开始进行第一次迭代计算,得到吸引信息矩阵r、设置归属信息矩阵a、相似度矩阵f初始值;
3.5、更新吸引信息矩阵,计算第t+1次的吸引信息矩阵rt+1(i,k),其计算公式为:
归属信息矩阵中,计算第t+1次的归属信息矩阵at+1(i,k),其计算公式为:当i≠k时,即
3.6、更新吸引信息矩阵和归属信息矩阵后,计算日负荷数据的聚类结果;
3.7、对3.5、3.6步骤进行迭代,如果日负荷数据的聚类经过数次迭代后聚类结果保持不变或者算法执行超过设定的迭代次数,则算法结束,得到h个类型,类型集合为w=[w1,w2,…,wh]。
步骤4基于聚类结果,得到h个类型,类型集合为w=[w1,w2,…,wh],根据第h类负荷中包含的日负荷曲线的数量与日负荷曲线总数量的比值,确定出各类负荷的权重向量m=[m1,m2,…,mh]。所述步骤4中,各类负荷的权重向量计算方法为:
其中,ih为第h类负荷中包含的日负荷曲线的数量,365×n为选取n年历史日负荷曲线总数量。
步骤5预测远景年电力负荷需求
所述步骤5中,远景年典型日负荷计算方法为:
其中,
- 还没有人留言评论。精彩留言会获得点赞!