一种基于空间金字塔池的多模态融合显著性检测方法与流程
本发明涉及一种视觉显著性检测技术,尤其是涉及一种基于空间金字塔池的多模态融合显著性检测方法。
背景技术:
近年来,显著性检测已经成为计算机视觉领域一个非常有吸引力的研究课题。视觉显著性检测是一种识别图像中最明显的物体或区域的方法,其作为计算机视觉的预处理步骤,在视觉应用领域取得了巨大的成功,比如目标重定向、场景分类、视觉跟踪、图像检索、语义分割等。受人类视觉注意机制的启发,许多早期的视觉显著性检测方法利用低层次的视觉特征(如颜色、纹理和对比度)和启发式先验来模拟和近似人类的显著性。这些传统的技术被认为是有用的,因为能保持良好的图像结构和减少计算。然而,这种低级的特征和先验很难捕获关于图像中的对象特征及其周围环境的高级语义知识。相比而言,采用深度学习的方法来对图像进行显著性检测能够更好地提取对象特征以及周围环境的高级语义知识。
采用深度学习的方法,是直接进行像素级别端到端(end-to-end)的显著性检测,其只需要将训练集中的图像输入到模型框架中训练,然后得到权重与训练好的模型,即可在测试集中进行预测。卷积神经网络最大的优点在于它的结构多层次,能够自动学习特征,并且是可以学习到多个层次的特征。目前,显著性检测的方法可以分为两种:第一种是自顶向下的方法,它依赖于高级显著性先验来识别显著性区域,与受先验知识影响的识别过程有关,如要执行的任务、视觉场景的上下文等;第二种是自底向上的方法,它是一种独立于任务的数据驱动方法,通过将本地或全局上下文中每个区域的独特性与低级特征进行对比以度量显著性值,用于图像显著性自动选择的感知处理。
现有的显著性检测方法大多数采用的是深度学习的方法,利用卷积层与池化层相结合的模型较多,然而单纯的使用卷积操作与池化操作获得的特征图单一且不具有代表性,从而会导致得到的图像特征信息少,最终还会导致得到的显著性预测图效果较差,预测的准确度低。
技术实现要素:
本发明所要解决的技术问题是提供一种基于空间金字塔池的多模态融合显著性检测方法,其检测准确度高,且检测效率高。
本发明解决上述技术问题所采用的技术方案为:一种基于空间金字塔池的多模态融合显著性检测方法,其特征在于包括训练阶段和测试阶段两个过程;
所述的训练阶段过程的具体步骤为:
步骤1_1:选取m幅原始的立体图像的左视点图像、深度图像及真实人眼注视图,并构成训练集,将训练集中的第i幅原始的立体图像的左视点图像、深度图像及真实人眼注视图对应记为
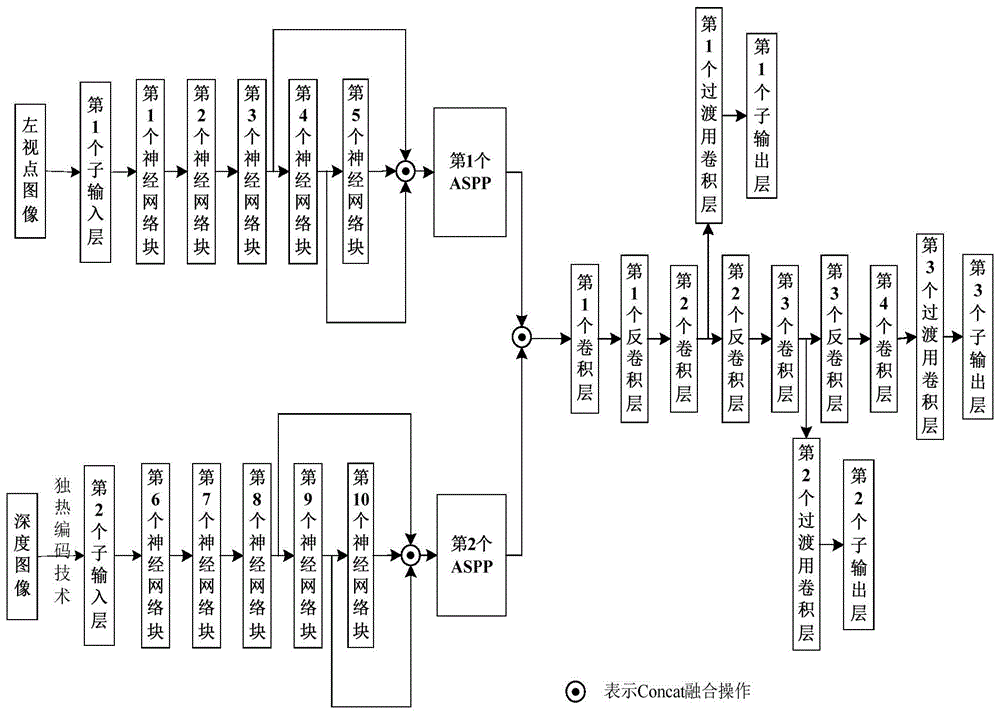
步骤1_2:构建卷积神经网络:卷积神经网络包括输入层、隐层和输出层,输入层包括2个子输入层,隐层包括10个神经网络块、2个空间金字塔池多模态融合层、4个卷积层、3个反卷积层、3个过渡用卷积层,输出层包括3个子输出层;其中,第1个卷积层的卷积核数目为2048、卷积核大小为3×3、补零参数的值为1、步长为1,第1个反卷积层的卷积核数目为2048、卷积核大小为4×4、补零参数的值为1、步长为2,第2个卷积层的卷积核数目为1024、卷积核大小为3×3、补零参数的值为1、步长为1,第2个反卷积层的卷积核数目为1024、卷积核大小为4×4、补零参数的值为1、步长为2,第3个卷积层的卷积核数目为512、卷积核大小为3×3、补零参数的值为1、步长为1,第3个反卷积层的卷积核数目为512、卷积核大小为4×4、补零参数的值为1、步长为2,第4个卷积层的卷积核数目为256、卷积核大小为3×3、补零参数的值为1、步长为1,第1个至第3个过渡用卷积层的卷积核数目均为1、卷积核大小均为3×3、补零参数的值均为1、步长均为1;
对于输入层:第1个子输入层的输入端接收一幅训练用左视点图像的r通道分量、g通道分量和b通道分量,第1个子输入层的输出端输出训练用左视点图像的r通道分量、g通道分量和b通道分量给隐层;第2个子输入层的输入端接收对应的训练用深度图像经独热编码技术后处理成的r通道分量、g通道分量和b通道分量,第2个子输入层的输出端输出训练用深度图像的r通道分量、g通道分量和b通道分量给隐层;其中,要求训练用左视点图像和训练用深度图像的宽度为w、高度为h;
对于隐层:第1个神经网络块的输入端接收第1个子输入层的输出端输出的训练用左视点图像的r通道分量、g通道分量和b通道分量,第1个神经网络块的输出端输出64幅宽度为
对于输出层:第1个子输出层的输入端接收第1个过渡用卷积层的输出端输出的特征图,第1个子输出层的输出端输出其接收的特征图,并作为第一显著性检测图;第2个子输出层的输入端接收第2个过渡用卷积层的输出端输出的特征图,第2个子输出层的输出端输出其接收的特征图,并作为第二显著性检测图;第3个子输出层的输入端接收第3个过渡用卷积层的输出端输出的特征图,第3个子输出层的输出端输出其接收的特征图,并作为第三显著性检测图;
步骤1_3:将训练集中的每幅左视点图像作为训练用左视点图像,并将训练集中对应的深度图像作为训练用深度图像;然后将训练用左视点图像的r通道分量、g通道分量和b通道分量及训练用深度图像的r通道分量、g通道分量和b通道分量输入到卷积神经网络中进行训练,得到训练集中的每幅左视点图像对应的第一显著性检测图、第二显著性检测图、第三显著性检测图;再将训练集中的所有左视点图像对应的第一显著性检测图构成的集合记为kpre1,并将训练集中的所有左视点图像对应的第二显著性检测图构成的集合记为kpre2,将训练集中的所有左视点图像对应的第三显著性检测图构成的集合记为kpre3;
步骤1_4:对训练集中的每幅左视点图像对应的真实人眼注视图进行缩放处理,将缩放处理成的宽度为
步骤1_5:重复执行步骤1_3和步骤1_4共n次,得到卷积神经网络训练模型,并共得到n个最终损失函数值;然后从n个最终损失函数值中找出值最小的最终损失函数值;接着将最小的最终损失函数值对应的权值矢量和偏置项对应作为卷积神经网络训练模型的最优权值矢量和最优偏置项,对应记为ωbest和bbest;其中,n>1;
所述的测试阶段过程的具体步骤为:
步骤2_1:将待显著性检测的立体图像的左视点图像和深度图像对应记为{rtest,l(x',y')}和{dtest(x',y')};然后采用独热编码技术将{dtest(x',y')}处理成与{rtest,l(x',y')}一样具有r通道分量、g通道分量和b通道分量;其中,1≤x'≤w',1≤y'≤h',w'表示待显著性检测的立体图像的宽度,h'表示待显著性检测的立体图像的高度,rtest,l(x',y')表示{rtest,l(x',y')}中坐标位置为(x',y')的像素点的像素值,dtest(x',y')表示{dtest(x',y')}中坐标位置为(x',y')的像素点的像素值;
步骤2_2:将{rtest,l(x',y')}的r通道分量、g通道分量和b通道分量及{dtest(x',y')}的r通道分量、g通道分量和b通道分量输入到卷积神经网络训练模型中,并利用ωbest和bbest进行预测,得到待显著性检测的立体图像对应的显著性检测图像,该显著性检测图像的宽度为w'且高度为h'。
所述的步骤1_2中,第1个神经网络块和第6个神经网络块的结构相同,其由依次设置的第一卷积层、第一激活层、第二卷积层、第二激活层、第一最大池化层组成,第一卷积层的输入端为其所在的神经网络块的输入端,第一激活层的输入端接收第一卷积层的输出端输出的所有特征图,第二卷积层的输入端接收第一激活层的输出端输出的所有特征图,第二激活层的输入端接收第二卷积层的输出端输出的所有特征图,第一最大池化层的输入端接收第二激活层的输出端输出的所有特征图,第一最大池化层的输出端为其所在的神经网络块的输出端;其中,第一卷积层和第二卷积层的卷积核数目均为64、卷积核大小均为3×3、补零参数的值均为1,第一激活层和第二激活层的激活方式均为“relu”,第一最大池化层的池化尺寸为2、步长为2;
第2个神经网络块和第7个神经网络块的结构相同,其由依次设置的第三卷积层、第三激活层、第四卷积层、第四激活层、第二最大池化层组成,第三卷积层的输入端为其所在的神经网络块的输入端,第三激活层的输入端接收第三卷积层的输出端输出的所有特征图,第四卷积层的输入端接收第三激活层的输出端输出的所有特征图,第四激活层的输入端接收第四卷积层的输出端输出的所有特征图,第二最大池化层的输入端接收第四激活层的输出端输出的所有特征图,第二最大池化层的输出端为其所在的神经网络块的输出端;其中,第三卷积层和第四卷积层的卷积核数目均为128、卷积核大小均为3×3、补零参数的值均为1,第三激活层和第四激活层的激活方式均为“relu”,第二最大池化层的池化尺寸为2、步长为2;
第3个神经网络块和第8个神经网络块的结构相同,其由依次设置的第五卷积层、第五激活层、第六卷积层、第六激活层、第七卷积层、第七激活层、第三最大池化层组成,第五卷积层的输入端为其所在的神经网络块的输入端,第五激活层的输入端接收第五卷积层的输出端输出的所有特征图,第六卷积层的输入端接收第五激活层的输出端输出的所有特征图,第六激活层的输入端接收第六卷积层的输出端输出的所有特征图,第七卷积层的输入端接收第六激活层的输出端输出的所有特征图,第七激活层的输入端接收第七卷积层的输出端输出的所有特征图,第三最大池化层的输入端接收第七激活层的输出端输出的所有特征图,第三最大池化层的输出端为其所在的神经网络块的输出端;其中,第五卷积层、第六卷积层和第七卷积层的卷积核数目均为256、卷积核大小均为3×3、补零参数的值均为1,第五激活层、第六激活层和第七激活层的激活方式均为“relu”,第三最大池化层的池化尺寸为2、步长为2;
第4个神经网络块和第9个神经网络块的结构相同,其由依次设置的第八卷积层、第八激活层、第九卷积层、第九激活层、第十卷积层、第十激活层、第四最大池化层组成,第八卷积层的输入端为其所在的神经网络块的输入端,第八激活层的输入端接收第八卷积层的输出端输出的所有特征图,第九卷积层的输入端接收第八激活层的输出端输出的所有特征图,第九激活层的输入端接收第九卷积层的输出端输出的所有特征图,第十卷积层的输入端接收第九激活层的输出端输出的所有特征图,第十激活层的输入端接收第十卷积层的输出端输出的所有特征图,第四最大池化层的输入端接收第十激活层的输出端输出的所有特征图,第四最大池化层的输出端为其所在的神经网络块的输出端;其中,第八卷积层、第九卷积层和第十卷积层的卷积核数目均为512、卷积核大小均为3×3、补零参数的值均为1,第八激活层、第九激活层和第十激活层的激活方式均为“relu”,第四最大池化层的池化尺寸为1、步长为1;
第5个神经网络块和第10个神经网络块的结构相同,其由依次设置的第十一卷积层、第十一激活层、第十二卷积层、第十二激活层、第十三卷积层、第十三激活层、第五最大池化层组成,第十一卷积层的输入端为其所在的神经网络块的输入端,第十一激活层的输入端接收第十一卷积层的输出端输出的所有特征图,第十二卷积层的输入端接收第十一激活层的输出端输出的所有特征图,第十二激活层的输入端接收第十二卷积层的输出端输出的所有特征图,第十三卷积层的输入端接收第十二激活层的输出端输出的所有特征图,第十三激活层的输入端接收第十三卷积层的输出端输出的所有特征图,第五最大池化层的输入端接收第十三激活层的输出端输出的所有特征图,第五最大池化层的输出端为其所在的神经网络块的输出端;其中,第十一卷积层、第十二卷积层和第十三卷积层的卷积核数目均为512、卷积核大小均为3×3、补零参数的值均为1,第十一激活层、第十二激活层和第十三激活层的激活方式均为“relu”,第五最大池化层的池化尺寸为1、步长为1。
所述的步骤1_2中,第1个空间金字塔池多模态融合层和第2个空间金字塔池多模态融合层的结构相同,它由第十四卷积层、第十四激活层、第一空洞卷积层、第十五激活层、第二空洞卷积层、第十六激活层、第三空洞卷积层、第十七激活层和第六最大池化层组成,第十四卷积层的输入端、第一空洞卷积层的输入端、第二空洞卷积层的输入端、第三空洞卷积层的输入端相连接,且其公共连接端为其所在的空间金字塔池多模态融合层的输入端,第十四激活层的输入端接收第十四卷积层的输出端输出的所有特征图,第六最大池化层的输入端接收第十四激活层的输出端输出的所有特征图,第十五激活层的输入端接收第一空洞卷积层的输出端输出的所有特征图,第十六激活层的输入端接收第二空洞卷积层的输出端输出的所有特征图,第十七激活层的输入端接收第三空洞卷积层的输出端输出的所有特征图,对第十四激活层的输出端输出的所有特征图、第六最大池化层的输出端输出的所有特征图、第十五激活层的输出端输出的所有特征图、第十六激活层的输出端输出的所有特征图、第十七激活层的输出端输出的所有特征图进行concat操作,将concat操作后得到的所有特征图作为所在的空间金字塔池多模态融合层的输出端输出的特征图;其中,第十四卷积层的卷积核大小为1×1、补零参数的值为0、步长为1,第十四激活层、第十五激活层、第十六激活层和第十七激活层的激活方式均为“relu;第一空洞卷积层的卷积核大小为3×3、补零参数的值为2、膨胀率为2,第二空洞卷积层的卷积核大小为3×3、补零参数的值为6、膨胀率为6,第三空洞卷积层的卷积核大小为3×3、补零参数的值为12、膨胀率为12,第六最大池化层的池化尺寸为3、补零参数的值为1、步长为1。
与现有技术相比,本发明的优点在于:
1)本发明方法在构建卷积神经网络时结合了多模态融合和深度信息的处理,因此能够准确地预测图像中的显著性区域,从而有效地提高了视觉显著性检测的精确度。
2)本发明方法采用了aspp模块(空间金字塔池)来处理多模态特征融合,该模块结构新颖且能减少融合过程中细节特征的丢失,从而能够获得较高的视觉显著性检测效率。
3)本发明方法采用了多尺度监督的方法进行卷积神经网络的训练,其通过多个输出的方式能够提升卷积神经网络的训练效率和最终的卷积神经网络训练模型的性能。
4)本发明方法在搭建卷积神经网络时不包括任何完全连接层,降低了计算复杂度,且改变了固有的向下采样操作,保持了图像的空间特征。
附图说明
图1为本发明方法中构建的卷积神经网络的组成结构示意图;
图2为本发明方法中构建的卷积神经网络中的空间金字塔池多模态融合层的组成结构示意图;
图3a为同一场景的第1幅待显著性检测的原始立体图像对应的真实人眼注视图;
图3b为利用本发明方法对第1幅待显著性检测的原始立体图像进行预测,得到的显著性检测图像;
图4a为同一场景的第2幅待显著性检测的原始立体图像对应的真实人眼注视图;
图4b为利用本发明方法对第2幅待显著性检测的原始立体图像进行预测,得到的显著性检测图像;
图5a为同一场景的第3幅待显著性检测的原始立体图像对应的真实人眼注视图;
图5b为利用本发明方法对第3幅待显著性检测的原始立体图像进行预测,得到的显著性检测图像;
图6a为同一场景的第4幅待显著性检测的原始立体图像对应的真实人眼注视图;
图6b为利用本发明方法对第4幅待显著性检测的原始立体图像进行预测,得到的显著性检测图像。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种基于空间金字塔池的多模态融合显著性检测方法,其包括训练阶段和测试阶段两个过程;
所述的训练阶段过程的具体步骤为:
步骤1_1:选取m幅原始的立体图像的左视点图像、深度图像及真实人眼注视图,并构成训练集,将训练集中的第i幅原始的立体图像的左视点图像、深度图像及真实人眼注视图对应记为
在此,直接选用由新加坡国立大学提供的视觉显著性检测数据库nus训练集中的420幅左视点图像、对应的深度图像及对应的真实人眼注视图构成训练集。
步骤1_2:构建卷积神经网络:如图1所示,卷积神经网络包括输入层、隐层和输出层,输入层包括2个子输入层,隐层包括10个神经网络块、2个空间金字塔池多模态融合层、4个卷积层、3个反卷积层、3个过渡用卷积层,输出层包括3个子输出层;其中,第1个卷积层的卷积核数目为2048、卷积核大小为3×3、补零参数(padding)的值为1、步长(stride)为1,第1个反卷积层的卷积核数目为2048、卷积核大小为4×4、补零参数的值为1、步长为2,第2个卷积层的卷积核数目为1024、卷积核大小为3×3、补零参数的值为1、步长为1,第2个反卷积层的卷积核数目为1024、卷积核大小为4×4、补零参数的值为1、步长为2,第3个卷积层的卷积核数目为512、卷积核大小为3×3、补零参数的值为1、步长为1,第3个反卷积层的卷积核数目为512、卷积核大小为4×4、补零参数的值为1、步长为2,第4个卷积层的卷积核数目为256、卷积核大小为3×3、补零参数的值为1、步长为1,第1个至第3个过渡用卷积层的卷积核数目均为1、卷积核大小均为3×3、补零参数的值均为1、步长均为1。
对于输入层:第1个子输入层的输入端接收一幅训练用左视点图像的r通道分量、g通道分量和b通道分量,第1个子输入层的输出端输出训练用左视点图像的r通道分量、g通道分量和b通道分量给隐层;第2个子输入层的输入端接收对应的训练用深度图像经独热编码技术后处理成的r通道分量、g通道分量和b通道分量,第2个子输入层的输出端输出训练用深度图像的r通道分量、g通道分量和b通道分量给隐层;其中,要求训练用左视点图像和训练用深度图像的宽度为w、高度为h。
对于隐层:第1个神经网络块的输入端接收第1个子输入层的输出端输出的训练用左视点图像的r通道分量、g通道分量和b通道分量,第1个神经网络块的输出端输出64幅宽度为
对于输出层:第1个子输出层的输入端接收第1个过渡用卷积层的输出端输出的特征图,第1个子输出层的输出端输出其接收的特征图,并作为第一显著性检测图;第2个子输出层的输入端接收第2个过渡用卷积层的输出端输出的特征图,第2个子输出层的输出端输出其接收的特征图,并作为第二显著性检测图;第3个子输出层的输入端接收第3个过渡用卷积层的输出端输出的特征图,第3个子输出层的输出端输出其接收的特征图,并作为第三显著性检测图。
步骤1_3:将训练集中的每幅左视点图像作为训练用左视点图像,并将训练集中对应的深度图像作为训练用深度图像;然后将训练用左视点图像的r通道分量、g通道分量和b通道分量及训练用深度图像的r通道分量、g通道分量和b通道分量输入到卷积神经网络中进行训练,得到训练集中的每幅左视点图像对应的第一显著性检测图、第二显著性检测图、第三显著性检测图;再将训练集中的所有左视点图像对应的第一显著性检测图构成的集合记为kpre1,并将训练集中的所有左视点图像对应的第二显著性检测图构成的集合记为kpre2,将训练集中的所有左视点图像对应的第三显著性检测图构成的集合记为kpre3。
步骤1_4:对训练集中的每幅左视点图像对应的真实人眼注视图进行缩放处理,将缩放处理成的宽度为
步骤1_5:重复执行步骤1_3和步骤1_4共n次,得到卷积神经网络训练模型,并共得到n个最终损失函数值;然后从n个最终损失函数值中找出值最小的最终损失函数值;接着将最小的最终损失函数值对应的权值矢量和偏置项对应作为卷积神经网络训练模型的最优权值矢量和最优偏置项,对应记为ωbest和bbest;其中,n>1,在本实施例中取n=600。
所述的测试阶段过程的具体步骤为:
步骤2_1:将待显著性检测的立体图像的左视点图像和深度图像对应记为{rtest,l(x',y')}和{dtest(x',y')};然后采用现有的独热编码技术(hha)将{dtest(x',y')}处理成与{rtest,l(x',y')}一样具有r通道分量、g通道分量和b通道分量;其中,1≤x'≤w',1≤y'≤h',w'表示待显著性检测的立体图像的宽度,h'表示待显著性检测的立体图像的高度,rtest,l(x',y')表示{rtest,l(x',y')}中坐标位置为(x',y')的像素点的像素值,dtest(x',y')表示{dtest(x',y')}中坐标位置为(x',y')的像素点的像素值。
步骤2_2:将{rtest,l(x',y')}的r通道分量、g通道分量和b通道分量及{dtest(x',y')}的r通道分量、g通道分量和b通道分量输入到卷积神经网络训练模型中,并利用ωbest和bbest进行预测,得到待显著性检测的立体图像对应的显著性检测图像,该显著性检测图像的宽度为w'且高度为h'。
在此具体实施例中,步骤1_2中,第1个神经网络块和第6个神经网络块的结构相同,其由依次设置的第一卷积层、第一激活层、第二卷积层、第二激活层、第一最大池化层组成,第一卷积层的输入端为其所在的神经网络块的输入端,第一激活层的输入端接收第一卷积层的输出端输出的所有特征图,第二卷积层的输入端接收第一激活层的输出端输出的所有特征图,第二激活层的输入端接收第二卷积层的输出端输出的所有特征图,第一最大池化层的输入端接收第二激活层的输出端输出的所有特征图,第一最大池化层的输出端为其所在的神经网络块的输出端;其中,第一卷积层和第二卷积层的卷积核数目均为64、卷积核大小均为3×3、补零参数的值均为1,第一激活层和第二激活层的激活方式均为“relu”,第一最大池化层的池化尺寸(pool_size)为2、步长(srtide)为2。
在此具体实施例中,第2个神经网络块和第7个神经网络块的结构相同,其由依次设置的第三卷积层、第三激活层、第四卷积层、第四激活层、第二最大池化层组成,第三卷积层的输入端为其所在的神经网络块的输入端,第三激活层的输入端接收第三卷积层的输出端输出的所有特征图,第四卷积层的输入端接收第三激活层的输出端输出的所有特征图,第四激活层的输入端接收第四卷积层的输出端输出的所有特征图,第二最大池化层的输入端接收第四激活层的输出端输出的所有特征图,第二最大池化层的输出端为其所在的神经网络块的输出端;其中,第三卷积层和第四卷积层的卷积核数目均为128、卷积核大小均为3×3、补零参数的值均为1,第三激活层和第四激活层的激活方式均为“relu”,第二最大池化层的池化尺寸为2、步长为2。
在此具体实施例中,第3个神经网络块和第8个神经网络块的结构相同,其由依次设置的第五卷积层、第五激活层、第六卷积层、第六激活层、第七卷积层、第七激活层、第三最大池化层组成,第五卷积层的输入端为其所在的神经网络块的输入端,第五激活层的输入端接收第五卷积层的输出端输出的所有特征图,第六卷积层的输入端接收第五激活层的输出端输出的所有特征图,第六激活层的输入端接收第六卷积层的输出端输出的所有特征图,第七卷积层的输入端接收第六激活层的输出端输出的所有特征图,第七激活层的输入端接收第七卷积层的输出端输出的所有特征图,第三最大池化层的输入端接收第七激活层的输出端输出的所有特征图,第三最大池化层的输出端为其所在的神经网络块的输出端;其中,第五卷积层、第六卷积层和第七卷积层的卷积核数目均为256、卷积核大小均为3×3、补零参数的值均为1,第五激活层、第六激活层和第七激活层的激活方式均为“relu”,第三最大池化层的池化尺寸为2、步长为2。
在此具体实施例中,第4个神经网络块和第9个神经网络块的结构相同,其由依次设置的第八卷积层、第八激活层、第九卷积层、第九激活层、第十卷积层、第十激活层、第四最大池化层组成,第八卷积层的输入端为其所在的神经网络块的输入端,第八激活层的输入端接收第八卷积层的输出端输出的所有特征图,第九卷积层的输入端接收第八激活层的输出端输出的所有特征图,第九激活层的输入端接收第九卷积层的输出端输出的所有特征图,第十卷积层的输入端接收第九激活层的输出端输出的所有特征图,第十激活层的输入端接收第十卷积层的输出端输出的所有特征图,第四最大池化层的输入端接收第十激活层的输出端输出的所有特征图,第四最大池化层的输出端为其所在的神经网络块的输出端;其中,第八卷积层、第九卷积层和第十卷积层的卷积核数目均为512、卷积核大小均为3×3、补零参数的值均为1,第八激活层、第九激活层和第十激活层的激活方式均为“relu”,第四最大池化层的池化尺寸为1、步长为1。
在此具体实施例中,第5个神经网络块和第10个神经网络块的结构相同,其由依次设置的第十一卷积层、第十一激活层、第十二卷积层、第十二激活层、第十三卷积层、第十三激活层、第五最大池化层组成,第十一卷积层的输入端为其所在的神经网络块的输入端,第十一激活层的输入端接收第十一卷积层的输出端输出的所有特征图,第十二卷积层的输入端接收第十一激活层的输出端输出的所有特征图,第十二激活层的输入端接收第十二卷积层的输出端输出的所有特征图,第十三卷积层的输入端接收第十二激活层的输出端输出的所有特征图,第十三激活层的输入端接收第十三卷积层的输出端输出的所有特征图,第五最大池化层的输入端接收第十三激活层的输出端输出的所有特征图,第五最大池化层的输出端为其所在的神经网络块的输出端;其中,第十一卷积层、第十二卷积层和第十三卷积层的卷积核数目均为512、卷积核大小均为3×3、补零参数的值均为1,第十一激活层、第十二激活层和第十三激活层的激活方式均为“relu”,第五最大池化层的池化尺寸为1、步长为1。
在此具体实施例中,步骤1_2中,第1个空间金字塔池多模态融合层和第2个空间金字塔池多模态融合层的结构相同,如图2所示,它由第十四卷积层、第十四激活层、第一空洞卷积层、第十五激活层、第二空洞卷积层、第十六激活层、第三空洞卷积层、第十七激活层和第六最大池化层组成,第十四卷积层的输入端、第一空洞卷积层的输入端、第二空洞卷积层的输入端、第三空洞卷积层的输入端相连接,且其公共连接端为其所在的空间金字塔池多模态融合层的输入端,第十四激活层的输入端接收第十四卷积层的输出端输出的所有特征图,第六最大池化层的输入端接收第十四激活层的输出端输出的所有特征图,第十五激活层的输入端接收第一空洞卷积层的输出端输出的所有特征图,第十六激活层的输入端接收第二空洞卷积层的输出端输出的所有特征图,第十七激活层的输入端接收第三空洞卷积层的输出端输出的所有特征图,对第十四激活层的输出端输出的所有特征图、第六最大池化层的输出端输出的所有特征图、第十五激活层的输出端输出的所有特征图、第十六激活层的输出端输出的所有特征图、第十七激活层的输出端输出的所有特征图进行concat操作,将concat操作后得到的所有特征图作为所在的空间金字塔池多模态融合层的输出端输出的特征图;其中,第十四卷积层的卷积核大小为1×1、补零参数的值为0、步长为1,第十四激活层、第十五激活层、第十六激活层和第十七激活层的激活方式均为“relu;第一空洞卷积层的卷积核大小为3×3、补零参数的值为2、膨胀率为2,第二空洞卷积层的卷积核大小为3×3、补零参数的值为6、膨胀率为6,第三空洞卷积层的卷积核大小为3×3、补零参数的值为12、膨胀率为12,第六最大池化层的池化尺寸为3、补零参数的值为1、步长为1。
为了进一步验证本发明方法的可行性和有效性,进行实验。
使用基于python的深度学习库pytorch0.4.1搭建卷积神经网络的架构。采用新加坡国立大学提供的视觉显著性检测数据库nus测试集来分析利用本发明方法检测得到的显著性检测图像(取420幅立体图像)的检测效果如何。这里,利用评估显著性检测方法的4个常用客观参量作为评价指标,即线性相关系数(linearcorrelationcoefficient,cc)、kullback-leibler散度系数(kullback-leiblerdivergence,kldiv)、auc参数(theaeraunderthereceiveroperatingcharacteristicscurve,auc)、标准化扫描路径显著性(normalizedscanpathsaliency,nss)来评价显著性检测图像的检测性能。
利用本发明方法对新加坡国立大学提供的视觉显著性检测数据库nus测试集中的每幅立体图像进行检测,得到每幅立体图像对应的显著性检测图像,反映本发明方法的显著性检测效果的线性相关系数cc、kullback-leibler散度系数kldiv、auc参数、标准化扫描路径显著性nss如表1所列。从表1所列的数据可知,按本发明方法得到的显著性检测图像的检测结果是较好的,表明利用本发明方法来获取立体图像对应的显著性检测图像是可行且有效的。
表1利用本发明方法在测试集上的评测结果
图3a给出了同一场景的第1幅待显著性检测的原始立体图像对应的真实人眼注视图;图3b给出了利用本发明方法对第1幅待显著性检测的原始立体图像进行预测,得到的显著性检测图像;图4a给出了同一场景的第2幅待显著性检测的原始立体图像对应的真实人眼注视图;图4b给出了利用本发明方法对第2幅待显著性检测的原始立体图像进行预测,得到的显著性检测图像;图5a给出了同一场景的第3幅待显著性检测的原始立体图像对应的真实人眼注视图;图5b给出了利用本发明方法对第3幅待显著性检测的原始立体图像进行预测,得到的显著性检测图像;图6a给出了同一场景的第4幅待显著性检测的原始立体图像对应的真实人眼注视图;图6b给出了利用本发明方法对第4幅待显著性检测的原始立体图像进行预测,得到的显著性检测图像。对比图3a和图3b,对比图4a和图4b,对比图5a和图5b,对比图6a和图6b,可以看出利用本发明方法得到的显著性检测图像的分割精度较高。
- 还没有人留言评论。精彩留言会获得点赞!