一种基于微信公众平台的汉蒙语料库众包构建方法与流程
本发明涉及一种基于微信公众平台的汉蒙语料库众包构建方法,属于语料资源建设技术领域。
背景技术:
由于目前蒙古语语料库种类单一、规模较小,汉蒙口语语音语料库建构的探索逐渐成为了自然语言研究领域的一个重要研究内容,特别是资源构建方法的研究将影响大规模语料资源的相关研究。另一方面因蒙古语自身复杂性而造成的文字编码不统一的问题,以语音语料库作为切入点可以作为语料库资源建设的一条可行途径。然而,目前的汉蒙口语语音语料库构建采用专家标注的方法缺花费大量的人力和物力,并且语料内容受限于单一领域,录音环境受限于单一场景,需要专门的人员对语料库构建过程进行采集、编辑以及处理,成本较大,周期相对较长。
技术实现要素:
本发明的目的在为了克服上述现有汉蒙语料库众包构建方法存在收集真实场景下的口语语音成本高、投入大的技术缺陷,提供了一种基于微信公众平台的汉蒙语料库众包构建方法。
为实现上述技术目的,本发明采用如下技术方案:
首先进行相关定义,具体如下:
定义1:微信客户端,即安装微信客户端的移动设备,主要为手机和平板电脑,数量范围为25000到30000个;
定义2:微信公众平台,功能是用于注册一订阅号或者服务号,用于与微信客户端建立连接和交互信息;
定义3:蒙古语水平测试问卷,即考核微信客户端语言能力的测试,内容包括15个汉蒙翻译测试题与用户的基本信息如微信昵称、学历、年龄,所在城市和蒙古语学习年长等;
定义4:过滤规则,即过滤微信客户端的规则,通过结合翻译测试结果打分和用户信息统计结果对微信客户端进行过滤的人工定义的规则;
定义5:后台管理员,即微信公众平台的管理人员,用于登录公众号平台实现与微信客户端的交互并进行语料管理;
定义6:众包,即一种面向互联网大众的分布式问题解决机制,通过整合计算机和互联网上未知的大众来完成特定任务;
定义7:众包质量控制,即对众包完成的任务进行答案整合,主要通过算法来保证结果的质量;
一种基于微信公众平台的汉蒙语料库众包构建方法,具体操作包括如下步骤:
步骤1、对原始语料进行预处理,得到经过预处理后的原始数据集;
其中,原始语料为教育、文娱、旅游、饮食以及百度贴吧领域的语料;
其中,对原始语料进行预处理的具体过程因翻译方向的不同而异,目的为对语料进行规范化处理,得到经过预处理后的原始语料;
其中,规范化处理包括断句及删除无意义数据操作;
步骤2、微信公众平台向微信客户端推送蒙古语水平测试问卷,利用过滤规则对参与翻译任务的微信客户端进行初步过滤,得到过滤后的微信客户端;
其中,微信公众平台的阐述见定义2;微信客户端的阐述见定义1;蒙古语水平测试问卷的阐述见定义3;初步过滤中过滤规则的阐述见定义4;
步骤3、结合步骤1得到的预处理后的原始语料以及步骤2得到的过滤后的微信客户端,后台管理员得到汉语语料集,把汉语语料集通过推送的方式发送给有效微信客户端;
其中,汉语语料集的每一条由一个汉语句构成,后台管理员的阐述见定义5;
步骤4、微信客户端利用步骤3推送的汉语句,选择其中的若干汉语句翻译成蒙古语,通过微信客户端的语音功能,以语音形式将翻译后的蒙语句发送给微信公众平台,完成语料的众包收集;
其中,众包的阐述见定义6;
步骤5、结合人工审核与多人投票的众包质量控制机制,后台管理员评估步骤4得到的语音语料,实现对已获取语料的质量评估;
其中,众包质量控制的阐述见定义7。
有益效果
本发明一种基于微信公众平台的汉蒙语料库众包构建方法,与现有的语料库构建方法相比,具有如下有益效果:
1.围绕蒙古语文字无统一计算机编码而引起的文本语料库不规范现象,以语音语料收集作为切入点,设计并开发面向众包征集口语语音任务的微信公众平台,有效解决了在真实蒙语语言环境下收集开放域自然口语语料的问题;
2.相对传统线下采集语料的方法,本方法通过微信公众平台完成线上语料收集,系统在线上操作、交互简单、用户体验好、用户参与度高,有效解放了大量的人力工作量;
3.利用众包模式建设少数民族语言语料资源,缓解资源稀缺语言训练语料规模小的不利影响,在互联网移动平台下展现了极高的实用前景。
附图说明
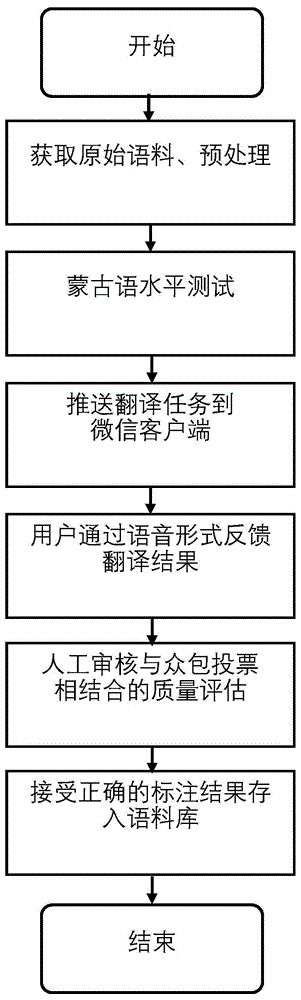
图1为本发明实施例基于微信公众平台的汉蒙语料库众包构建方法的整体流程图。
具体实施方式
下面结合附图对本发明实施例中的所述方法进行详细、完整地叙述。
本实施例中使用的基于微信公众平台的汉蒙语料库众包构建方法,如图1所示。其具体步骤为:
本发明实施例中语料包括文本语料、语音语料,包括机器翻译和自然语言处理领域的汉蒙双语对齐语料、单语文本对齐语料等。
步骤a、根据定义1、定义2,对原始文本进行预处理,其中,对原始语料进行预处理的具体过程因翻译方向的不同而异,目的为对语料进行规范化处理,其中,本实施例不限定语料来源,对其进行断句处理,然后删除其中无意义的数据。表1为原始语料示例。
表1
步骤b、根据定义3、定义4,结合定义1、定义2,通过微信公众平台向微信客户端推送蒙古语水平测试问卷,对参与翻译任务的微信客户端进行初步过滤。其中,初步过滤具体为:发布汉蒙翻译试题并回收答案,通过结合翻译结果打分、用户学历和用户蒙语学习年限三个维度的统计结果,利用人工定义的规则过滤掉语言能力不合格者并选出若干个有效的擅长蒙语人员;
步骤c、根据定义5,结合步骤a得到的预处理后的原始语料以及步骤b得到的过滤后的微信客户端,后台管理员每次随机挑选20个待翻译汉语句,利用微信公众平台编辑成包含20个待翻译句的图文,通过微信公众号推送给25000-30000个微信客户端。
步骤d、根据定义6,微信客户端利用步骤c推送的汉语句,选择其中的若干汉语句翻译成蒙古语,通过微信客户端的语音功能,以语音形式将翻译后的蒙语句发送给所述微信公众平台。具体地,步骤b得到的25000-30000个有效蒙古语用户,通过微信客户端订阅并查看图文翻译任务,选择其中的1-20个汉语句翻译成蒙古语,通过终端的语音发送功能以语音形式将翻译好的1-20个相应蒙语语音返回给微信公众平台,完成蒙语句的众包翻译。
步骤e、根据定义5、定义6、定义7,结合众包质量控制机制,后台管理员对步骤d得到的语音语料进行质量评估。具体的,质量监控环节需要进行文本之间的相似度计算,本实施例采用基于tf-idf的指标来进行度量。对于两个文本m和m’,如果m是参考文本,则相似度计算执行以下步骤。
(1)使用tf-idf算法,找出两个文本的关键词;
其中,si,j是词
其中,|d|是语料库文件总数2,|{j:wi∈di}|是包含词语wi的文件总数2。
通过计算公式tfidfi,j=tfi,j×idfi找出关键词
(2)对于每个文本各取出若干关键词形成集合,计算每个文本对集合中词的词频;
其中,列出全部出现过的词语如下。
(3)生成两个文本句各自的词频向量;
(4)计算两个向量的余弦相似度;
至此,通过采用融合语义信息的tf-idf方法计算文本相似度,达到预设阈值的文本被确定为初步正确的候选结果。
进一步,对于上述得到的人工标注结果通过微信公众号进一步进行了众包投票,具体做法是,将选出的蒙语语音转写成蒙文文本后推送给微信客户端,用户根据汉语原句与对应的蒙语翻译选项,选择自己认为正确的结果反馈给微信公众平台,统计投票人数最多的结果,选择有效的翻译结果。
步骤f、后台管理员接受正确的翻译结果;具体的,将所述正确的基于真实场景采集的汉蒙双语语料结果存储到语料库中。
至此,从步骤a到步骤f,完成了一种基于微信公众平台的汉蒙语料库众包构建方法。
以上所述为本发明的较佳实施例而已,本发明不应该局限于该实施例和附图所公开的内容。凡是不脱离本发明所公开的精神下完成的等效或修改,都落入本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!