基于序列上下文关系学习的行人属性识别方法和识别系统与流程
本发明属于行人属性识别
技术领域:
,具体涉及一种结合图像与属性类内和类间关系的行人识别方法与系统。
背景技术:
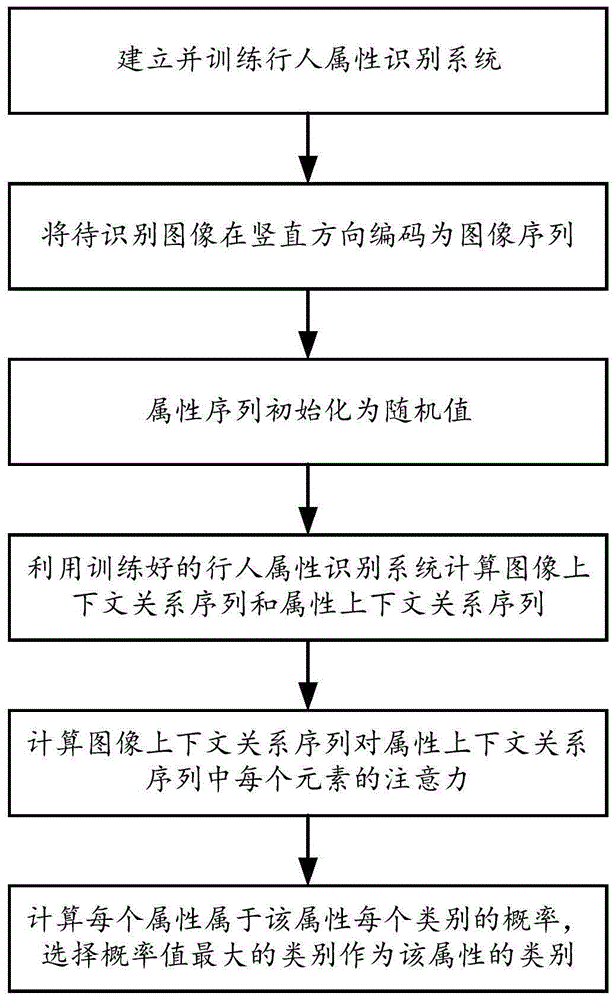
:行人属性识别的任务就是去预测图像中的行人的属性标签,包括年龄,性别,衣服的颜色等。这些属性中包含着能够描述行人外观丰富的语义信息,能够给行人识别任务带来有益的信息,具有较高的应用价值,从而其获得了广泛的关注。其主要难点在于行人角度和照片光照的变化以及远距离会影响到识别的准确度。为了提交行人属性识别的准确度,目前的方法大多通过输入一整张图像进入分类网络,分别将每一种属性做分类预测,例如性别为一个男或者女的二分类预测。虽然上述方法取得了较好的结果,但是其仍然忽略了图像间以及属性间的问题。属性间不同的元素,包含着大量的上下文关系,例如穿裙子的人基本都是女性。同时图像间的不同元素,也包含着大量相互关系,例如图像中的不同元素包括着行人的不同身体区域,这些区域之间存在着内在的空间关系。这些上下文关系均将有助于提高识别的准确率。因此有些方法采用将图像手动分块或是将属性手动分组并来获取图像间或是属性间的元素间上下文关系,但是这些方法需要利用先验知识来将图像分成固定数量的块数或是将属性分成固定的组,这样固定的分组使得属性间上下文关系的学习具有局限性且有一些不合理,普适性较低,当有新的属性加入时还需要重新分组。技术实现要素:发明目的:本发明旨在提供一种识别准确率较高的行人属性识别方法,该方法充分利用了图像序列间的上下文关系、属性间的上下文关系以及图像与属性间的上下文关系,提高了行人属性识别的准确率。技术方案:本发明一方面提供了一种基于序列上下文关系学习的行人属性识别方法,包括训练阶段和识别阶段;所述训练阶段的步骤为:(1)建立图像竖直方向编码网络,所述编码网络将图像在竖直方向编码为长度为m的图像序列p=[p1,p2,…,pm];m为图像序列的长度;(2)建立属性映射表,所述属性映射表中定义了图像中行人的属性;根据属性映射表将行人属性编码为属性序列a=[a1,a2,…,an];n为属性种类总数;(3)建立类内注意力模型,所述类内注意力模型计算图像序列p各元素间的上下文关系p″m和属性序列a各元素间的上下文关系a″n,得到图像上下文关系序列p″=[p″1,p″2,…,p″m]和属性上下文关系序列a″=[a″1,a″2,…,a″n];其中p″m表示图像序列p对其第m个元素的注意力;a″n表示属性序列a对其第n个元素的注意力;m=1,2,…,m,n=1,2,…,n;(4)建立类间注意力模型,所述类间注意力模型计算图像上下文关系序列p″与属性上下文关系序列a″中每个元素的注意力,构成关系序列pa″=[pa″1,pa″2,…,pa″n];pa″n表示图像上下文关系序列p″对属性上下文关系序列a″中第n个元素a″n的注意力;(5)构建训练样本集,所述训练样本集中的图像为行人全身图像,并对图像中的行人标定每个属性标签gn和类别标签w;将样本集中的图像输入图像竖直方向编码网络,将样本图像中的行人属性序列初始化为随机值;通过最小化损失函数的值,得到训练好的图像竖直方向编码网络、类内注意力模型和类间注意力模型;所述损失函数包括属性损失和行人识别损失;所述属性损失为:其中lan为第n个属性的损失,kn为第n个属性的类别数,pa(k)为第n个属性为第k类的概率;当k=gn时,qa(k)=1,否则qa(k)=0;gn为训练样本中行人第n个属性的真实标签;所述行人识别损失为:其中pid(c)为样本行人属于第c类的概率;c为行人类别总数;当c=w时,qid(c)=1,否则qid(c)=0;w为训练样本中行人的真实类别标签;总的损失函数为:lfinal=la+lid;所述识别阶段的步骤为:(6)将待识别图像中行人的属性序列初始化为随机值,且p≠q时待识别图像输入到图像竖直方向编码网络中,得到图像序列at和pt经过类内注意力模型,得到属性上下文关系序列a″t和图像上下文关系序列pt″;a″t和pt″经过类间注意力模型得到图像与属性之间的关系序列pat″;pat″经过softmax层,得到待识别图像中行人每个属性属于该属性每个类别的概率,选择概率值最大的类别作为该属性的类别。所述图像竖直方向编码网络的采用resnet50的残差网络结构。所述类内注意力模型计算序列seq=[seq1,seq2,…,seqb]对其元素seqb的注意力seq″b,b=1,2,…,b;所述类内注意力模型包括并行的u个子类内注意力模型和一个全连接层f3,每个子类内注意力模型的结构相同,参数不同,在不同的映射子空间计算seq对seqb的注意力seq′b;f3的参数为wf;将不同映射子空间中seq对seqb的注意力seqb合并到同一空间,经过全连接层f3得到seq对seqb的最终注意力seq″b;所述第u个子类内注意力模型,u=1,2,…,u,包括:两个全连接层f1u和其中f1u的参数为输入为seq中的每个元素seqj,j=1,2,…,b;的参数为输入为seqb;f1u和输出数据的维度为输入数据维度的矩阵计算模块,根据f1u和的输出计算当前子空间中seq对seqb的注意力seq′b:其中rjb为seq第j个元素seqj与seqb在当前子空间的归一化相似度,其中为seqj与seqb在当前子空间的相似度,db为的输出维度;u个子类内注意力模型的输出拼接起来经过全连接层f3,得到seq″b:所述类间注意力模型计算序列seq=[seq1,seq2,…,seqb]对序列req=[req1,req2,…,reql]中的元素reql的注意力sreq″l,l=1,2,…,l;所述类间注意力模型包括并行的u个子类间注意力模型和一个全连接层f6,每个子类间注意力模型的结构相同,参数不同,在不同的映射子空间计算seq对reql的注意力sreq′l;f6的参数为wfa;将不同映射子空间seq对reql的注意力sreq′l合并到同一空间,经过全连接层f6得到seq对reql的最终注意力sreq″l;所述第u个子类间注意力模型,u=1,2,…,u,包括:两个全连接层和其中的参数为输入为seq中的每个元素seqj,j=1,2,…,b;的参数为输入为reql;和输出数据的维度为输入数据维度的矩阵计算模块,根据和的输出计算当前子空间中seq对reql的注意力sreql′u:其中sjl为seq第j个元素seqj与reql在当前子空间的归一化相似度,其中为seqj与reql在当前子空间的相似度,fl为的输出维度u个子类间注意力模型的输出拼接起来经过全连接层f6,得到sreq″l:本发明中,相似度归一化采用softmax函数实现。作为一种改进,对训练样本集图像中的行人标定属性标识串,所述属性标识串为图像中行人所具备的属性在属性映射表中序号所组成的数字串;所述损失函数还包括ctc损失,所述ctc损失为:lctc=-ln(pctc(y|ps))其中ps为样本图像经过图像竖直方向编码网络编码后的图像序列;y为样本图像中行人的属性标识串;pctc(y|ps)为根据样本图像的图像序列将样本图像中行人属性标识串识别为其真实属性标识串y的概率;总的损失函数为:lfinal=la+lid+lctc。所述pctc(y|ps)的计算步骤为:(7.1)将样本图像经过图像竖直方向编码网络编码的图像序列ps输入循环神经网络rnn1中得到样本图像中行人所具有的属性的概率和属性的组合;所述rnn1包含两层双向rnn层,每层双向rnn层的节点数与ps中每个元素的维数相同;rnn1的输出单元个数为m,第m个输出单元的输出frm为根据图像序列ps第m个元素psm将样本图像中的行人识别为具有属性πm的概率p(πm|psm);πm∈[1,2,…,n]∪[ε],ε表示无法识别的属性;πm构成属性组合π=(π1,π2,…,πm);(7.2)根据删减规则对π进行删减,如果删减后的属性集合π′等于y,则将当前样本的属性集合π作为一个元素加入到样本属性集合所构成的集合中;(7.3)对样本集中的每个样本图像执行步骤(7.1)-(7.2),得到样本属性集合所构成的集合则p′ctc(y|ps)为将样本图像中的行人识别具有属性y的概率:本发明采用reshape网络计算图像中行人属于第c类的概率pid(c),具体步骤为:构建reshape网络,所述reshape网络包括依次连接的第一卷积层rconv_1、第一最大池化层rmaxpool_1、第二卷积层rconv_2、第二最大池化层rmaxpool_2和全连接层rfc_1;所述第一卷积层rconv_1卷积核为1×1,输出通道为1024,步长为[2,1],输出大小为14×1×1024;所述第一最大池化层rmaxpool_1卷积核为1×1,输出通道为1024,步长为[2,1],输出大小为7×1×1024;所述第二卷积层rconv_2卷积核为1×1,输出通道为1024,步长为[2,1],输出大小为4×1×1024;所述第二最大池化层rmaxpool_2卷积核为3×1,输出通道为1024,步长为[2,1],输出大小为1×1×1024;全连接层rfc_1卷积核为1×1,输出通道为行人类别总数c,步长为1,输出大小为1×c;将样本图像经过图像竖直方向编码网络编码后的图像序列ps输入reshape网络,得到样本图像的特征fid∈r1×1×c,将fid输入softmax层,得到图像中行人属于第c类的概率pid(c):其中fid(i)为fid第i个元素的值。另一方面,本发明提供了一种实现上述行人属性识别方法的识别系统,该识别系统包括:图像竖直方向编码网络1,用于将图像在竖直方向编码为长度为m的图像序列p=[p1,p2,…,pm];m为图像序列的长度;属性映射表存储模块2,用于存储属性映射表;所述属性映射表中定义了图像中行人的属性;根据属性映射表将行人属性编码为属性序列a=[a1,a2,…,an];n为属性种类总数;类内注意力模型3,用于计算图像序列p各元素间的上下文关系p″m和属性序列a各元素间的上下文关系a″n,得到图像上下文关系序列p″=[p1″,p2″,…,p″m]和属性上下文关系序列a″=[a1″,a″2,…,a″n];其中p″m表示图像序列p对其第m个元素的注意力;a″n表示属性序列a对其第n个元素的注意力;m=1,2,…,m,n=1,2,…,n;类间注意力模型4,用于计算图像上下文关系序列p″与属性上下文关系序列a″中每个元素的注意力,构成关系序列pa″=[pa1″,pa″2,…,pa″n];pa″n表示图像上下文关系序列p″对属性上下文关系序列a″中第n个元素a″n的注意力;模型训练模块5,包括训练样本输入模块5-1和损失计算模块5-2,所述损失计算模块包括属性损失计算模块5-2a和行人识别损失计算模块5-2b;训练样本输入模块5-1用于将标定好的训练样本输入图像竖直方向编码网络;属性损失计算模块5-2a用于计算属性损失,属性损失为:其中lan为第n个属性的损失,kn为第n个属性的类别数,pa(k)为第n个属性为第k类的概率;当k=gn时,qa(k)=1,否则qa(k)=0;gn为训练样本中行人第n个属性的真实标签;行人识别损失计算模块5-2b用于计算行人识别损失,所述行人识别损失为:其中pid(c)为样本行人属于第c类的概率;c为行人类别总数;当c=w时,qid(c)=1,否则qid(c)=0;w为训练样本中行人的真实类别标签;总的损失函数为:lfinal=la+lid;属性识别结果输出模块6,用于根据待识别图像的图像与属性之间的关系序列pa″t得到待识别图像中行人每个属性的类别。作为一种改进,损失计算模块5-2还包括ctc损失计算模块5-2c,ctc损失计算模块5-2c用于计算ctc损失,ctc损失为:lctc=-ln(pctc(y|ps));其中ps为样本图像经过图像竖直方向编码网络编码后的图像序列;y为样本图像中行人的属性标识串;pctc(y|ps)为根据样本图像的图像序列将样本图像中行人属性标识串识别为其真实属性标识串y的概率;总的损失函数为:lfinal=la+lid+lctc。有益效果:本发明公开的基于序列上下文关系学习的行人属性识别方法和识别系统将图像和属性编码成序列,并利用类内注意力模型学习图像序列或属性序列的序列间上下文关系,从而获得更多的细节特征;同时,利用类间注意力模型,学习图像序列与属性序列两者之间的关系,从而实现在识别每个属性时可以关注到与该属性更相关的图像序列;由此来提高识别准确率。附图说明图1为本发明公开的行人属性识别方法的流程图;图2为本发明公开的行人属性识别系统的组成图;图3为子类内注意力模型的组成结构图;图4为类内注意力模型的组成结构图;图5为子类间注意力模型的组成结构图;图6为类间注意力模型的组成结构图;具体实施方式下面结合附图和具体实施方式,进一步阐明本发明。如图1所示,本发明一方面提供了一种基于序列上下文关系学习的行人属性识别方法,包括训练阶段和识别阶段;所述训练阶段建立并训练行人属性识别系统,行人属性识别系统的组成框图如图2所示。训练阶段的步骤为:步骤1、建立图像竖直方向编码网络1,编码网络将图像在竖直方向编码为长度为m的图像序列p=[p1,p2,…,pm];m为图像序列的长度;本发明中,图像竖直方向编码网络的采用卷积神经网络cnn对图像在竖直方向编码,具体采用resnet50的残差网络结构,包括第一卷积层conv_1、第一池化层maxpool_1、4个卷积块conv2_x-conv5_x、第二池化层maxpool_2和全连接层fc_1;其参数见表1。表1其中conv_2x,conv_4x,conv_5x的步长为:第一个卷积块的第一个卷积层步长为[1,2],其他层均为1;conv_3x的步长为:第一个卷积块的第一个卷积层步长为[2,1],其他层均为1。本实施例中图像竖直方向编码网络1输入图像的尺寸为224×112,经过编码得到的图像序列为28×1×1024的矩阵,即m=28,p=[p1,p2,…,p28],图像序列p中每个元素pm均为1024维的向量;m=1,2,…,m。步骤2、建立属性映射表,本实施例中,将属性映射表存储于属性映射表存储模块2中;属性映射表中定义了图像中行人的属性;根据属性映射表将行人属性编码为属性序列a=[a1,a2,…,an];n为属性种类总数;本实施例中定义了22种属性,即n=22,具体属性见表2。表21帽子6上衣灰11背包16下衣红21鞋子2上衣黑7上衣蓝12包17下衣灰22性别3上衣白8上衣绿13手拿包18下衣蓝4上衣红9上衣棕14下衣黑19下衣绿5上衣紫10上衣长短15下衣白20下衣棕根据表2可知,可以得到属性序列a=[a1,a2,…,a22],其中第n个元素an表示第n的类别用1024维的向量表示;本实施例中每个属性的类别数均为2,如第1个属性的第一类别为行人戴帽子,第二个类别为不戴帽子,即是否戴帽子用1024维的向量来表示。步骤3、建立类内注意力模型3,所述类内注意力模型计算图像序列p各元素间的上下文关系p″m和属性序列a各元素间的上下文关系a″n,得到图像上下文关系序列p″=[p1″,p2″,…,p″m]和属性上下文关系序列a″=[a″1,a″2,…,a″n];其中p″m表示图像序列p对其第m个元素的注意力;a″n表示属性序列a对其第n个元素的注意力;m=1,2,…,m,n=1,2,…,n;本发明中,类内注意力模型包括并行的u个子类内注意力模型和一个全连接层f3,每个子类内注意力模型的结构相同,参数不同,在不同的映射子空间计算seq对seqb的注意力seq′b;f3的参数为wf;将不同映射子空间中seq对seqb的注意力seqb合并到同一空间,经过全连接层f3得到seq对seqb的最终注意力seq″b;第u个子类内注意力模型,u=1,2,…,u,包括:两个全连接层f1u和其中f1u的参数为输入为seq中的每个元素seqj,j=1,2,…,b;的参数为输入为seqb;f1u和输出数据的维度为输入数据维度的矩阵计算模块3-1a,根据f1u和的输出计算当前子空间中seq对seqb的注意力seq′b:其中rjb为seq第j个元素seqj与seqb在当前子空间的归一化相似度,本实施例中相似度归一化采用softmax函数实现。为seqj与seqb在当前子空间的相似度,能够反映seq对seqb的注意力,db为的输出维度;u个子类内注意力模型的输出拼接起来经过全连接层f3,得到seq″b:即类内注意力模型计算一个序列seq=[seq1,seq2,…,seqb]对其内部元素seqb的注意力seq″b,b=1,2,…,b;seq″b构成的序列seq″=[seq1″,seq″2,…,seq″b]反映了序列seq对其自身的注意力。采用并行的多个子类内注意力模型能够获取不同的映射子空间的序列的相似度。本实施例中,采用8个并行的子类内注意力模型,即u=8,如图3和图4所示,为类内注意力模型3的示意图,其中图3为子类内注意力模型的结构图,图4为类内注意力模型的结构图。每个子类内注意力模型中两个全连接层的输入维度均为1024,输出维度均为128,db=128;第u个子类内注意力模型计算得到的seq对seqb的注意力为128维向量,将8个子类内注意力模型的输出拼接起来的结果为1024维向量。全连接层f3的输入输出维度与seqb的维度相同,本实施例中,均为1024,即seq″b为1024维向量。分别计算p=[p1,p2,…,p28]对其每个元素的注意力,得到图像上下文关系序列p″=[p1″,p″2,…,p″28];分别计算a=[a1,a2,…,a22]其每个元素的注意力,得到属性上下文关系序列a″=[a″1,a″2,…,a″22],其中p″m和a″n均为1024维向量。步骤4、建立类间注意力模型4,所述类间注意力模型计算图像上下文关系序列p″与属性上下文关系序列a″中每个元素的注意力,构成关系序列pa″=[pa″1,pa″2,…,pa″n];pa″n表示图像上下文关系序列p″对属性上下文关系序列a″中第n个元素a″n的注意力;类间注意力模型计算序列seq=[seq1,seq2,…,seqb]对序列req=[req1,req2,…,reql]中的元素reql的注意力sreq″l,l=1,2,…,l;所述类间注意力模型包括并行的u个子类间注意力模型4-1和一个全连接层f6,每个子类间注意力模型的结构相同,参数不同,在不同的映射子空间计算seq对reql的注意力sreq′l;f6的参数为wfa;将不同映射子空间seq对reql的注意力sreq′l合并到同一空间,经过全连接层f6得到seq对reql的最终注意力sreq″l;所述第u个子类间注意力模型,u=1,2,…,u,包括:两个全连接层和其中的参数为输入为seq中的每个元素seqj,j=1,2,…,b;的参数为输入为reql;和输出数据的维度为输入数据维度的矩阵计算模块4-1a,根据和的输出计算当前子空间中seq对reql的注意力sreql′u:其中sjl为seq第j个元素seqj与reql在当前子空间的归一化相似度,本实施例中同样采用softmax函数来进行相似度归一化的计算:其中为seqj与reql在当前子空间的相似度,fl为的输出维度;u个子类间注意力模型的输出拼接起来经过全连接层f6,得到sreq″l:本实施例中,同样采用8个并行的子类间注意力模型,seq为p″=[p1″,p2″,…,p″28],reql为a″=[a″1,a″2,…,a″22]中的元素。如图4和图5所示,为类间注意力模块4的示意图,其中图4为子类间注意力模型的结构图,图5为类间注意力模型的结构图。其结构与类内注意力模块3的结构相同,但参数不同。同样地,全连接层f6的输入输出维度与reql的维度相同,本实施例中,均为1024,即sreq″l为1024维向量。最终得到的关系序列为pa″=[pa″1,pa″2,…,pa″22]。步骤5、构建训练样本集,所述训练样本集中的图像为行人全身图像,并对图像中的行人标定每个属性标签gn、类别标签w,并标定属性标识串,所述属性标识串为图像中行人所具备的属性在属性映射表中序号所组成的数字串;将样本集中的图像随机选择64张作为一组输入图像竖直方向编码网络,并将样本图像中的行人属性序列中的元素初始化为1024维的随机值;通过最小化损失函数的值,得到训练好的图像竖直方向编码网络、类内注意力模型和类间注意力模型;损失函数包括属性损失、行人识别损失和ctc损失;行人属性识别系统的训练由模型训练模块5来实现,其包括训练样本输入模块5-1和损失计算模块5-2,损失计算模块包括属性损失计算模块5-2a、行人识别损失计算模块5-2b和ctc损失计算模块5-2c。训练样本输入模块5-1用于将标定好的训练样本输入图像竖直方向编码网络;所述属性损失计算模块5-2a用于计算属性损失,属性损失为:其中lan为第n个属性的损失,kn为第n个属性的类别数,pa(k)为第n个属性为第k类的概率;当k=gn时,qa(k)=1,否则qa(k)=0;gn为训练样本中行人第n个属性的真实标签;本实施例中,将类间注意力模型4的输出pa″=[pa1″,pa″2,…,pa″n]后面接n个全连接层,pa″的第n个元素pa″n输入到第第n个全连接层fan中,fan的输入维度为pa″n的维度,本实施例中为1024;fan的输出维度是第n个属性的类别数kn,本实施例中kn=2;记fan的输出为在fan后接softmax层,得到第n个属性为第k类的概率pa(k):行人识别损失计算模块5-2b用于计算行人识别损失,所述行人识别损失为:其中pid(c)为样本行人属于第c类的概率;c为行人类别总数;当c=w时,qid(c)=1,否则qid(c)=0;w为训练样本中行人的真实类别标签;本发明采用reshape网络计算图像中行人属于第c类的概率pid(c),具体步骤为:构建reshape网络,所述reshape网络包括依次连接的第一卷积层rconv_1、第一最大池化层rmaxpool_1、第二卷积层rconv_2、第二最大池化层rmaxpool_2和全连接层rfc_1;reshape网络的参数如表3。表3将样本图像经过图像竖直方向编码网络编码后的图像序列ps输入reshape网络,得到样本图像的特征fid∈r1×1×c,将fid输入softmax层,得到图像中行人属于第c类的概率pid(c):其中fid(i)为fid第i个元素的值。为了增加行人属性识别方法的鲁棒性,本实施例的损失函数还包括ctc损失函数,采用ctc损失计算模块5-2c来计算ctc损失lctc:lctc=-ln(pctc(y|ps))其中ps为样本图像经过图像竖直方向编码网络编码后的图像序列;y为样本图像中行人的属性标识串;以本实施例中表2所定义的属性映射表,如图像中行人为不戴帽子,穿黑上衣,背包,灰裤子,低帮鞋子的男性,则其属性标识串y为:[2,11,17,21,22];如果图像中行人为戴帽子,穿黑上衣,背包,灰裤子,高帮鞋子的女性,则其属性标识串y为:[1,2,11,17]。pctc(y|ps)为根据样本图像的图像序列将样本图像中行人属性标识串识别为其真实属性标识串y的概率;本发明中pctc(y|ps)的计算步骤为:(7.1)将样本图像经过图像竖直方向编码网络编码的图像序列ps输入循环神经网络rnn1中得到样本图像中行人所具有的属性的概率和属性的组合;所述rnn1包含两层双向rnn层,每层双向rnn层的节点数与ps中每个元素的维数相同;rnn1的输出单元个数为m,第m个输出单元的输出frm为根据图像序列ps第m个元素psm将样本图像中的行人识别为具有属性πm的概率p(πm|psm);πm∈[1,2,…,n]∪[ε],ε表示无法识别的属性;πm构成属性组合π=(π1,π2,…,πm);如果rnn1不同的输出单元识别出的属性有重复或为ε,根据文献:gravesa,fernándezs,gomezf,etal.connectionisttemporalclassification:labellingunsegmentedsequencedatawithrecurrentneuralnetworks[c]//proceedingsofthe23rdinternationalconferenceonmachinelearning.acm,2006:369-376.对π进行删减,删除重复的属性和ε;如果删减后的属性集合π′等于y,则将当前样本的属性集合π作为一个元素加入到样本属性集合所构成的集合中;(7.3)对样本集中的每个样本图像执行步骤(7.1)-(7.2),得到样本属性集合所构成的集合则pc′tc(y|ps)为将样本图像中的行人识别具有属性y的概率:损失计算模块的输出为总的损失函数:lfinal=la+lid+lctc。所述识别阶段的步骤为:步骤6、将待识别图像中行人的属性序列初始化为随机值,且p≠q时待识别图像输入到图像竖直方向编码网络中,得到图像序列at和pt经过类内注意力模型,得到属性上下文关系序列a″t和图像上下文关系序列pt″;a″t和pt″经过类间注意力模型得到图像与属性之间的关系序列pa″t;pa″t经过softmax层,得到待识别图像中行人每个属性属于该属性每个类别的概率,选择概率值最大的类别作为该属性的类别。由pa″t得到最终属性识别结果的过程由属性识别结果输出模块6来完成。本实施例在duke属性数据集上进行测试,并与几种现有行人属性识别方法进行了对比,测试结果如表4所示,其中ma是22类属性的平均正确率。表4:实验结果methodsma(%)apr86.6sunetal.[4]88.3mlfn[5]87.5ourw/octc88.2our89.3表4中apr为采用文献:liny,zhengl,zhengz,etal.improvingpersonre-identificationbyattributeandidentitylearning[j].patternrecognition,2019中的方法的结果;sunetal.[4]为采用文献:sunc,jiangn,zhangl,etal.unifiedframeworkforjointattributeclassificationandpersonre-identification[c]//internationalconferenceonartificialneuralnetworks.springer,cham,2018:637-647.中的方法的结果;mlfn为采用文献:changx,hospedalestm,xiangt.multi-levelfactorisationnetforpersonre-identification[c]//proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2018:2109-2118.中的方法的结果;ourw/octc为采用本发明公开的行人属性识别方法,总的损失函数为:lfinal=la+lid情况下的结果;our为采用本发明公开的行人属性识别方法,总的损失函数为:lfinal=la+lid+lctc情况下的结果;从表4可以看出,本发明公开的方法识别平均准确率是优于现有的行人属性识别方法。并且,通过没有ctc损失函数的实验结果可以看出,本发明中加入ctc损失函数可以提高识别的平均正确率。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1