基于深度学习图像识别的套筒灌浆密实度判别方法与流程
本发明涉及套筒灌浆密实度判别技术领域,具体涉及基于深度学习图像识别的套筒灌浆密实度判别方法。
背景技术:
预制装配式混凝土结构(简称pc,prefabricatedconcrete),是以预制混凝土构件为主要构件,经装配、连接,结合部分现浇而形成的混凝土结构。pc工程在当今世界建筑领域中,作为新兴的绿色环保节能型建筑在海外得到较普遍运用。我国在近年来也得到了长足的进展,特别是住建部于2014年颁布了《装配式混凝土结构技术规程》(jgj1-2014),标志着该领域在我国已进入快速发展期。
其中,其中的钢筋套筒连接,以及套筒连接的灌浆密实度也直接影响到结构的承载力,是最为关键的质量要点之一。在jgj1-2014中,要求对其进行全数检测。
但是,套筒灌浆料饱满度检测是非常困难的,尽管业内提出了x射线工业ct法、预埋传感器法、预埋钢丝拉拔法、x射线胶片成像法等方法,但其各有适用范围和特点,检测成本较高,还无法实际应用。传统方法主要是基于冲击弹性波测点的波形图人工判断套筒灌浆密实度,人工判断取决于很多因素包括工程师的经验、工程的地区差异等等,很难将这一标准复制、延续。
套筒的类型各种各样,使用传统机器学习方法用于套筒灌浆料饱满度检测时,往往需要采用手工设计特征,基于好的特征可以极大提高识别的性能,现有技术主要依靠设计者的先验知识,很难利用大数据的优势,由于依赖手工调参数,特征的设计中只允许出现少量的参数;另外,手工设计出有效的特征是一个相当漫长的过程,而回顾计算机视觉发展的历史,往往需要五到十年才能出现一个受到广泛认可的好的特征;并且在传统机器学习过程中特征和分类是分开的。然而,在套筒灌浆料饱满度检测时靠手动完成设计特征,且需要大量领域专业知识,耗时费力,成本较高,并且最终的判别效率并不高。因此,需要一种简单高效的套筒灌浆密实度判别方法。
技术实现要素:
本发明所要解决的技术问题是:现有的套筒灌浆密实度判别方法检测耗时费力,检测成本较高而识别率不高,本发明提供了解决上述问题的基于深度学习图像识别的套筒灌浆密实度判别方法,利用大数据把深度学习思想应用到套筒灌浆密实度判别上,通过深度学习方法从大数据中自动学习特征,而非采用手工设计的特征,把特征和分类结合在一起,获取足够的训练样本以及合适的分类器就能达到相当的精度,极大的提高了套筒灌浆密实度的判断精度,同时有效的排除了人为因素,降低了成本,是一种非常有前途的判断方法;本发明给套筒灌浆密实度的判别提供了一种新思路。
本发明通过下述技术方案实现:
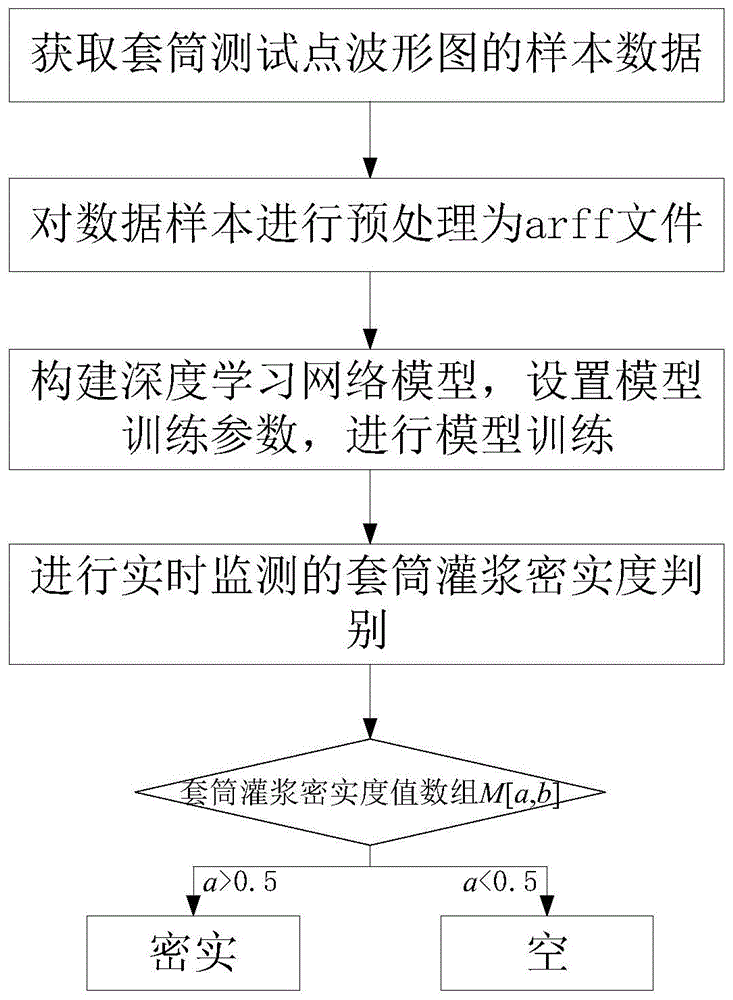
基于深度学习图像识别的套筒灌浆密实度判别方法,该方法包括以下步骤:
s1:通过敲击方式获取套筒各个测试点的波形图作为样本数据,共采集套筒灌浆密实度数据信息得到1200个样本,并将这1200个样本作为训练样本,其中密实样本和空样本各600个;
s2:对套筒灌浆密实度数据样本进行预处理,形成weka支持的arff文件,arff文件格式如下:
@relationimage
@attributefilenamestring
@attributeclass{sound,void}
@data
sound121.png,sound
sound122.png,sound
void121.png,void
void122.png,void
其中,arff文件属性有2个,arff文件属性包括filename和class;filename文件名类型为字符型;class为分类属性,包括密和空,sound代表密实,void代表空;
s3:构建套筒灌浆密实度深度学习网络模型,设置该深度学习网络模型的训练参数,根据步骤s2预处理后的arff文件输入到该深度学习网络模型的输入层进行模型训练,从而获得训练好的套筒灌浆密实度深度学习网络模型;其中,深度学习网络模型包括输入层、第一隐藏网络层、第二隐藏网络层、全连接层和输出层,第一隐藏网络层包括第一卷积层和第一池化层,第二隐藏网络层包括第二卷积层和第二池化层;输入层输入步骤s2预处理后的arff文件,输入层输出给第一卷积层,第一卷积层输出给第一池化层,第一池化层输出给第二卷积层,第二卷积层输出给第二池化层,第二池化层输出给全连接层,全连接层输出给输出层;
s4:将待监测的套筒灌浆密实度数据信息预处理为arff文件并实时输入到步骤s3训练好的套筒灌浆密实度深度学习网络模型中,输出套筒灌浆密实度数组m[a,b],该数组m由2个双精度型数值a、b表示,a、b这两个数值的总和为1,a、b分别代表类别标签sound(密实),void(空);当a大于0.5时,认为该套筒灌浆密实度为密实的;反之当a小于0.5时亦即b大于0.5时,认为该套筒灌浆密实度为空的。
进一步地,步骤s1中通过敲击方式获取套筒各个测试点的波形图,针对套筒各个测试点的波形图,首先,通过混凝土多功能无损测试一次解析软件自动截取测试点波形图并保存为jpg或者png图片格式,图片尺寸1387×551像素,此时图片颜色为彩色三通道;其次,通过图片处理软件将以上图片缩小到414×186像素,颜色设置为单通道的黑白两色。
进一步地,步骤s3中设置该深度学习网络模型的训练参数,训练参数包括:第一卷积层的卷积核大小为5×5,卷积核步长为1×1,扩充边缘为2,卷积模式为same模式,卷积核个数为20;第二卷积层的卷积核大小为5×5,卷积核步长为1×1,扩充边缘为2,卷积模式为same模式,卷积核个数为50;第一池化层的池化方法为最大池化法,卷积核大小为2×2,卷积核步长为2×2;第二池化层的池化方法为最大池化法,卷积核大小为2×2,卷积核步长为2×2;全连接层的卷积核个数为500;输出层的损失函数为多类交叉熵函数,卷积核个数为2;模型迭代次数为5;随机种子为1;图片高度为186,图片宽度为414,通道数为黑白2种颜色,训练批处理样本为2。
进一步地,所述第一卷积层、所述第二卷积层和所述输出层的激活函数均采用relu函数,relu函数的表达式如下:
式中,x为所在层的输入信号,relu(x)为所在层的输出信号,当所在层输入信号x≤0时,输出信号relu(x)都是0;当所在层输入信号x>0的情况下,输出信号relu(x)都是x。
进一步地,所述全连接层的激活函数采用softmax函数,softmax函数的表达式如下:
式中,zk为深度学习网络模型的神经网络第二池化层输出的第k个向量分量;zj为深度学习网络模型的神经网络第二池化层输出的第j个向量分量;σ(z)j为向量分量zj通过softmax激活函数变换得到的对应值;j=1,2,3...k。
softmax函数又称归一化指数函数,是逻辑函数的一种推广。它能将一个含任意实数的k维向量z“压缩”到另一个k维实向量σ(z)中,使得每一个元素的范围都在(0,1)之间,并且所有元素的和为1。
进一步地,步骤s3中的全连接层为3层全连接网络。
本发明具有如下的优点和有益效果:
1、本发明借助深度学习从大数据中自动学习特征,其中可以包含成千上万的参数,而非采用手工耗时设计的特征,从训练数据中很快学习得到新的有效的特征表示,不需要人为参与,节约了人力物力成本,且能达到好的效果;
2、本发明利用大数据把深度学习思想应用到套筒灌浆密实度判别上,通过深度学习方法从大数据中快速自动学习有效的特征,把特征和分类结合在一起,获取足够的训练样本以及合适的分类器就能达到相当的精度,极大的提高了套筒灌浆密实度的判断精度,同时有效的排除了人为因素,降低了成本,是一种非常有前途的判断方法;本发明给套筒灌浆密实度的判别提供了一种新思路。
附图说明
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定。在附图中:
图1为本发明的基于深度学习图像识别的套筒灌浆密实度判别方法流程图。
图2为本发明的套筒灌浆密实度深度学习网络模型图。
图3为本发明的解析软件自动截取测试点波形图。
图4为本发明的步骤s12中对图片处理后的波形图。
图5为本发明的最大池化法图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
实施例
如图1至图5所示,基于深度学习图像识别的套筒灌浆密实度判别方法,该方法包括以下步骤:
步骤s1:通过敲击方式获取套筒各个测试点的波形图作为样本数据,共采集套筒灌浆密实度数据信息得到1200个样本,并将这1200个样本作为训练样本,其中密实样本和空样本各600个;
其中,针对套筒各个测试点的波形图需做如下处理后作为样本数据:
s11,如图3所示,通过混凝土多功能无损测试一次解析软件自动截取测试点波形图并保存为jpg或者png图片格式,图片尺寸1387×551像素,此时图片颜色为彩色三通道;
s12,考虑到该类型上述图片尺寸较大且为彩色三通道,而彩色对于混凝土缺陷分类几乎无帮助,因此,如图4所示,通过图片处理软件将以上图片缩小到414×186像素,颜色设置为单通道即黑白两色。这样保证大量样本数据占用空间小,同时,提高后续模型训练的速度。
步骤s2:对套筒灌浆密实度数据样本进行预处理,形成weka支持的arff文件,arff文件格式如下:
@relationimage
@attributefilenamestring
@attributeclass{sound,void}
@data
sound121.png,sound
sound122.png,sound
void121.png,void
void122.png,void
其中,arff文件属性有2个,arff文件属性包括filename和class;filename文件名类型为字符型;class为分类属性,包括密和空,sound代表密实,void代表空;本发明中filename实则是个可以把样本图片存储在计算机中的一个路径,通过该路径调取样本图片数据,供后续模型训练使用。
步骤s3:构建套筒灌浆密实度深度学习网络模型,设置该深度学习网络模型的训练参数,根据步骤s2预处理后的arff文件输入到该深度学习网络模型的输入层进行模型训练,从而获得训练好的套筒灌浆密实度深度学习网络模型;输入层输入步骤s2预处理后的arff文件,从输入层进入第一隐藏网络层的第一卷积层,经过第一卷积层执行卷积操作提取套筒灌浆密实度图片的底层到高层的特征,发掘出套筒灌浆密实度图片局部关联性质和空间不变性质,然后进入第一池化层执行降采样操作,过滤掉一些不重要的高频信息;从第一隐藏网络层输出后进入第二隐藏网络层进行深层特征的学习,在此过程中,采用随机梯度下降方法,对深度学习网络参数进行迭代更新,得到训练好的深度学习网络模型。
具体地,步骤s3包括如下:
s31,构建套筒灌浆密实度深度学习网络模型,深度学习网络模型包括输入层、第一隐藏网络层、第二隐藏网络层、全连接层和输出层,第一隐藏网络层包括第一卷积层和第一池化层,第二隐藏网络层包括第二卷积层和第二池化层;输入层输入步骤s2预处理后的arff文件,输入层输出给第一卷积层,第一卷积层输出给第一池化层,第一池化层输出给第二卷积层,第二卷积层输出给第二池化层,第二池化层输出给全连接层,全连接层输出给输出层;如图2所示,输入层input,第一卷积层conv1,第一池化层pooing1,第二卷积层conv2,第二池化层pooing2,全连接层dense,输出层output。
s32,设置该深度学习网络模型的训练参数,训练参数包括:
第一卷积层的卷积核大小为5×5,卷积核步长为1×1,扩充边缘为2,激活函数为relu函数,卷积模式为same模式,卷积核个数为20;
第一池化层的池化方法为最大池化法,卷积核大小为2×2,卷积核步长为2×2;
第二卷积层的卷积核大小为5×5,卷积核步长为1×1,扩充边缘为2,激活函数为relu函数,卷积模式为same模式,卷积核个数为50;
第二池化层的池化方法为最大池化法,卷积核大小为2×2,卷积核步长为2×2;
全连接层的激活函数为softmax函数,卷积核个数为500;
输出层的激活函数为relu函数,损失函数为多类交叉熵函数,卷积核个数为2;
其它参数还有,模型迭代次数为5;随机种子为1;图像迭代器为imageinstanceiterator,图片高度为186,图片宽度为414,通道数为黑白2种颜色,训练批处理样本为2。
其中,第一卷积层和第二卷积层的卷积核的大小为5*5,扩充边缘均设置为2,则扩充的时候是左右、上下对称的四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图featuremap就不会变小,保证特征图的后续识别准确率。
其中,第一卷积层和第二卷积层的卷积模式均设置为same,卷积之后输出的特征图featuremap,相对于输入图片尺寸保持不变,这样保证整体上从输入到输出的过程中,图片的精准度,不会因为处理过程的形变而影响结果的判别。
其中,第一池化层和第二池化层的池化方法为最大池化法,以图5为例,最大池化法把4*4的图像分割成4个不同的区域,然后输出每个区域的最大值,其实这里选择了2*2的过滤器,步长为2。
其中,所述第一卷积层、所述第二卷积层和所述输出层的激活函数均采用relu函数,relu函数的表达式如下:
式中,x为所在层的输入信号,relu(x)为所在层的输出信号,当所在层输入信号x≤0时,输出信号relu(x)都是0;当所在层输入信号x>0的情况下,输出信号relu(x)都是x。
其中,所述全连接层的激活函数采用softmax函数,它能将一个含任意实数的k维向量z“压缩”到另一个k维实向量σ(z)中,使得每一个元素的范围都在之间,并且所有元素的和为1。softmax函数的表达式如下:
式中,zk为深度学习网络模型的神经网络第二池化层输出的第k个向量分量;zj为深度学习网络模型的神经网络第二池化层输出的第j个向量分量;σ(z)j为向量分量zj通过softmax激活函数变换得到的对应值;j=1,2,3...k。
例:输入向量[1,2,3,4,1,2,3]对应的softmax函数的值为[0.024,0.064,0.175,0.475,0.024,0.064,0.175]。输出向量中拥有最大权重的项对应着输入向量中的最大值“4”。对向量进行归一化,凸显其中最大的值并抑制远低于最大值的其他分量。
其中,全连接层为3层全连接网络。
s33,根据步骤s2预处理后的arff文件输入到该深度学习网络模型的输入层进行模型训练,从而获得训练好的套筒灌浆密实度深度学习网络模型,最终得到序列化模型dl4j.model。
步骤s4:将待监测的套筒灌浆密实度数据信息预处理为arff文件并实时输入到步骤s3训练好的套筒灌浆密实度深度学习网络模型dl4j.model中,输出套筒灌浆密实度数组m[a,b],该数组m由2个双精度型数值a、b表示,a、b这两个数值的总和为1,a、b分别代表类别标签sound(密实),void(空);当a大于0.5时,认为该套筒灌浆密实度为密实的;反之当a小于0.5时亦即b大于0.5时,认为该套筒灌浆密实度为空的;通过套筒灌浆密实度深度学习网络模型dl4j.model对需实时监测的套筒灌浆密实度给出判别。
本发明基于深度学习图像识别的套筒灌浆密实度判别方法,利用大数据把深度学习思想应用到套筒灌浆密实度判别上,通过深度学习方法从大数据中快速自动学习有效的特征,其中可以包含成千上万的参数,而非采用手工耗时设计的特征,把特征和分类结合在一起,获取足够的训练样本以及合适的分类器就能达到相当的精度,极大的提高了套筒灌浆密实度的判断精度,同时有效的排除了人为因素,降低了成本,是一种非常有前途的判断方法;本发明给套筒灌浆密实度的判别提供了一种新思路。
实例1套筒灌浆密实度深度学习网络模型中针对密实和缺陷各20个样本的实验结果如表1所示:
表1密实和缺陷各20个样本判断结果
实例2套筒灌浆密实度深度学习网络模型中针对中间部位密实和缺陷各15个样本的实验结果如表2所示:
表2中间部位密实和缺陷各15个样本判断结果
实例3套筒灌浆密实度深度学习网络模型中针对边界部位密实50个样本的实验结果如表3所示:
表3边界部位密实50个样本判断结果
综合以上实验数据,通过本发明的套筒灌浆密实度深度学习网络模型在不同情况下的套筒灌浆密实度识别的真正率(tp)、假正率(fp),精度(precision)、召回率(recall)和f值(f-measure),准确率、最小置信度和最大置信度可以明确看出,本发明方法针对套筒灌浆密实度判别达到了较高的识别率,且节约了大量人力物力,方便使用。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!