一种基于逻辑回归的OFFSET方法与流程
本发明是基于消费分期用户产生的数据信息,结合机器学习、特征工程等相关技术,提供一种基于逻辑回归的offset方法。本发明在逻辑回归中采用offset方法预测违约概率。
背景技术:
现有消费分期用户产生的数据信息,存在某时间段部分数据源存在批量特征数据缺失的问题,例如,从某一中间时点才开始接入一个第三方数据(以x1表示此特征组),导致接入时点前的用户(以c1表示此用户群)该数据源全部缺失。这种数据系统性缺失的情况下,将该数据源的特征直接处理成缺失值或空值是不合理的,因为该数据源的缺失并非随机缺失,传统的数据补齐或填充方法会造成严重的数据偏离。另外,如果仅用特征x1未缺失的样本建模,则会损失该数据源接入前用户c1样本所包含的信息,模型的准确性将受影响。
技术实现要素:
本发明的目的是提供一种基于逻辑回归的offset方法。
本发明解决其技术问题所采用的技术方案包括如下步骤:
步骤1、确认影响客户的违约因素,包括运营商数据、消费行为数据、借贷申请信息、终端设备信息、活跃地理位置信息和信用评分等;
步骤2、相关数据的采集、转化、量化和衍生;
步骤3、构建模型进行迭代及运算;
步骤4、效果验证;
步骤1所述的影响客户违约因素的确认,具体实现如下:
所述的运营商数据包括申请客户的通话详单、短信详单和充值记录;
所述的消费行为数据主要指线上消费数据,包括了每个月购物类消费金额、消费的商品种类;通过线上消费数据提取出反映客户的收入水平、消费习惯的特征;
所述的借贷申请信息是指客户在其它借贷平台的申请信息,目前在多个平台申请笔数、历史借贷情况;
所述的终端设备信息包括设备类型、app列表、各类app活跃度;
所述的客户的各类信用评分,包括线上线下消费分期、芝麻信用分、融资租赁信用情况;
步骤2所述的相关数据的采集、转化、量化和衍生,是指在步骤1中确立可能影响客户违约的各个维度后,将相应数据进行转化和量化,并衍生加工生成所需的变量。
2.根据权利要求1所述的一种基于逻辑回归的offset方法,其特征在于步骤3所述的构建模型进行迭代及运算,具体实现如下:
3.1特征工程包括对特征的异常值和缺失值的处理、数据变换及特征选择;
①剔除交易平台基础特征项异常值的样本,对于部分特征项缺失的情况进行填充;
②对于第三方多头特征项未匹配到的记录,不做任何填充,后续采用的算法本身已考虑空值问题;
③运营商数据提供了相关通话详单、短信详单和充值记录,用户在不同时间段的通话情况、短信互通情况,在不同时间段的通话频率、短信互通频率;围绕通话时长,通话时间,主被叫情况,生成新的衍生变量;围绕短信数量、接收发送情况生成新的衍生变量;同时根据充值方式、金额以及频率生成新的衍生变量,从而获得衍生特征;
3.2构建模型
3.2.1模型训练说明:
1.基于原始特征和特征工程步骤生成的衍生特征,采用多种特征组合构建多个模型,通过多个评估指标最终选择最优模型;
2.将所有样本的65%作为模型的训练集,用于模型训练;将剩余的35%作为模型的测试集,用于评估模型的训练结果;
3.模型训练分三个阶段;
阶段一:利用逻辑回归模型对样本进行训练,使用训练集全量样本,即包括c1,但不包含用户群c1系统性缺失的特征x1;
阶段二:获取每个样本的回归模型分数值;
阶段三:以阶段二的模型分数值为offset项,基于含特征x1除c1外的用户样本,使用offset方法来进一步优化模型效果;
此三阶段充分考虑了特征x1缺失的用户群c1以及特征x1未缺失的用户群所包含的信息;
3.2.2offset算法
offset方法源于泊松回归模型的应用,在泊松回归中,“曝光量”可被视为偏移量放在等式右边,即offset项;
log(e(y|x))=log(exposure)+θ’x
其中,e(y|x)表示各解释变量x固定时被解释变量y的平均值;exposure表示偏移量;θ'表示待估计的参数,为向量形式;x表示各解释变量,为向量形式;
将上式左右两边同时减去log(exposure),即得到下列式子:
其中,e(y|x)表示各解释变量x固定时被解释变量y的平均值;exposure表示偏移量;θ'表示待估计的参数,为向量形式;x表示各解释变量,为向量形式;
在实际应用中,可用offset()来指定表示“exposure”的变量,代码如下:
glm(y~offset(log(exposure))+x,family=poisson(link=log))
logistic回归是一种广义线性回归,即y=wtx+b,其中w和b是待求参数,逻辑回归基础公式如下:
其中,y表示被解释变量;w表示待估计的偏回归系数;b为待估计的常数项系数;
上述公式经变换后,得到:
再结合offset方法,logistic回归模型最终变为:
其中,w0表示offset变量;λ为相应的系数,取值为1;
在运行逻辑回归模型时,用offset()来指定表示“exposure”的变量,此时代码如下:
glm(y~offset(logit(exposure))+x,family=binomial(link=“logit”))
exposure即基于全量样本除缺失特征x1外的信息得出的模型结果,而特征x1未缺失的用户样本在exposure基础上能够提升模型效果。
本发明有益效果如下:
本发明结合逻辑回归和offset方法来解决某时间段部分数据源存在系统性特征数据缺失的问题,分步骤构建违约模型并进行实例验证。从结果的对比来看,在应用offset方法后,模型的稳定性和准确性都有了明显提升。
附图说明
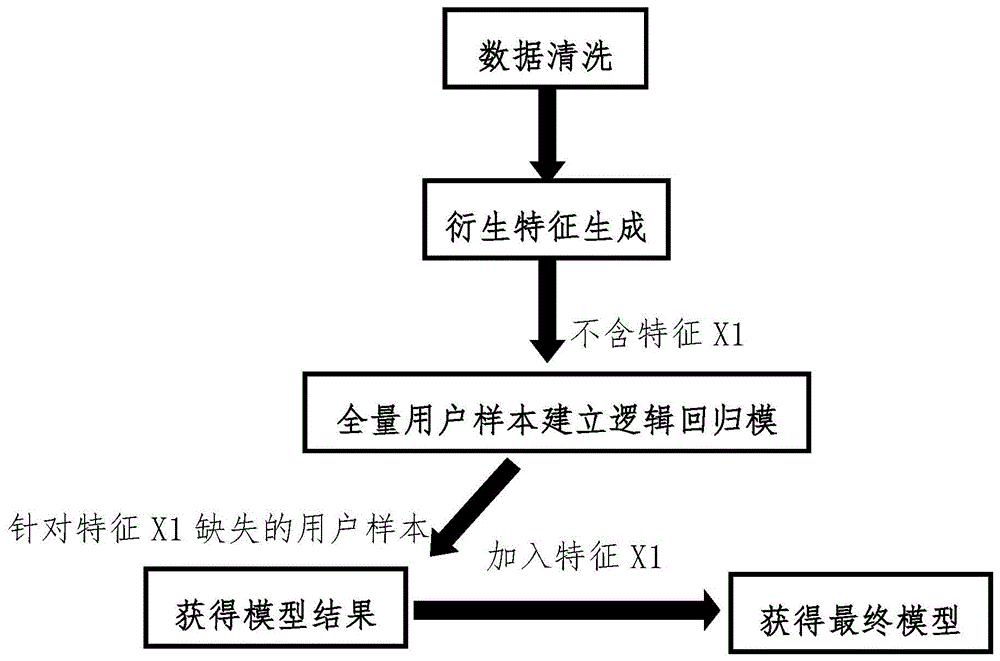
图1为本发明模型构建的流程图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明。
如图1所示,本发明实现步骤如下:
步骤1、确认影响客户的违约因素,包括运营商数据、消费行为数据、借贷申请信息、终端设备信息、活跃地理位置信息和信用评分等。
步骤2、相关数据的采集、转化、量化和衍生;
步骤3、构建模型进行迭代及运算;
步骤4、效果验证。
步骤1所述的影响客户违约因素的确认,具体实现如下:
所述的运营商数据包括申请客户的通话详单、短信详单和充值记录等,由于运营商数据的记录多而杂乱无章,需要进一步整合,提炼出相应字段,例如,近x个月通话次数、时长、夜间通话次数占比等等。在风控模型建立过程中,需要充分挖掘相关数据,以提高模型的准确性。
所述的消费行为数据主要指线上消费数据,包括了每个月购物类消费金额、消费的商品种类等。通过这些数据能够提取出反映客户的收入水平、消费习惯的特征。
所述的借贷申请信息是指客户在其它借贷平台的申请信息,如目前在多个平台申请笔数、历史借贷情况。
所述的终端设备信息包括设备类型、app列表、各类app活跃度等。
所述的客户的各类信用评分,包括线上线下消费分期、芝麻信用分、融资租赁信用情况等。
步骤2所述的相关数据的采集、转化、量化和衍生,具体实现如下:
在步骤1中确立可能影响客户违约的各个维度后,将相应数据进行转化和量化,并衍生加工生成可帮助解释模型及具有商业意义的变量。
步骤3所述的构建模型进行迭代及运算,具体实现如下:
3.1特征工程包括对特征的异常值和缺失值的处理、数据变换及特征选择。
①剔除交易平台基础特征项异常值的样本,对于部分特征项缺失的情况进行填充。
②对于第三方多头特征项未匹配到的记录,不做任何填充,后续采用的算法本身已考虑空值问题。
③运营商数据提供了相关通话详单、短信详单和充值记录,用户在不同时间段的通话情况、短信互通情况,在不同时间段的通话频率、短信互通频率;围绕通话时长,通话时间,主被叫情况,生成新的衍生变量;围绕短信数量、接收发送情况生成新的衍生变量;同时根据充值方式、金额以及频率生成新的衍生变量。
3.2构建模型
3.2.1本项目模型训练说明:
1.基于原始特征和特征工程步骤生成的衍生特征,本项目采用多种特征组合构建多个模型,通过多个评估指标最终选择最优模型。
2.将所有样本的65%作为模型的训练集,用于模型训练;将剩余的35%作为模型的测试集,用于评估模型的训练结果。
3.模型训练分三个阶段。
阶段一:利用逻辑回归模型对样本进行训练(使用训练集全量样本,即包括c1,但不包含用户群c1系统性缺失的特征x1);
阶段二:获取每个样本的回归模型分数值;
阶段三:以阶段二的模型分数值为offset项,基于含特征x1除c1外的用户样本,使用offset方法来进一步优化模型效果。
此三阶段充分考虑了特征x1缺失的用户群c1以及特征x1未缺失的用户群所包含的信息;
3.2.2offset算法原理
offset方法源于泊松回归模型的应用。
泊松回归模型(poissonregressionmodel)是广义线性模型(generalizedlinearmodel)的一种,以对数变化作为连接函数(canonicalfunction),该模型的假设之一是其被解释变量服从泊松分布。
泊松分布也可以适用于比率数据,即事件发生次数与其测量时间或测量范围的比值。比如生物学家测量某森林中树木种类的数目,比率变量即为每平方千米的树木种类数。人口学家关注的是每个人口年(person-year)的人口死亡数。通常来说,比率变量表达的是单位时间内该事件发生的次数。在这些例子中,“平方米”,“人口年”这些变量就是所谓的“曝光量”(exposure)。
在泊松回归中,“曝光量”可被视为偏移量放在等式右边,即offset项。
log(e(y|x))=log(exposure)+θ'x
其中,e(y|x)表示各解释变量x固定时被解释变量y的平均值;exposure表示偏移量;θ'表示待估计的参数,为向量形式;x表示各解释变量,为向量形式。
将上式左右两边同时减去log(exposure),即得到下列式子:
其中,e(y|x)表示各解释变量x固定时被解释变量y的平均值;exposure表示偏移量;θ'表示待估计的参数,为向量形式;x表示各解释变量,为向量形式。
在实际应用中,例如在r软件里运行广义线性模型时,可用offset()来指定表示“exposure”的变量,代码如下:
glm(y~offset(log(exposure))+x,family=poisson(link=log))
logistic回归也是一种广义线性回归(generalizedlinearmodel)即y=wtx+b,其中w和b是待求参数。logistic回归对被解释变量进行转换,即将发生概率除以没有发生概率再取对数。这个变换改变了等式左右取值区间的矛盾以及因变量和自变量间的曲线关系。究其原因,是发生和未发生的概率成为了比值,这个比值就是一个缓冲,将取值范围扩大,再进行对数变换,整个因变量改变。
逻辑回归基础公式如下:
其中,y表示被解释变量;w表示待估计的偏回归系数;b为待估计的常数项系数。
上述公式经变换后,得到:
再结合offset方法,logistic回归模型最终变为:
其中,w0表示offset变量;λ为相应的系数,一般为1。
在r中运行逻辑回归模型时,可用offset()来指定表示“exposure”的变量,此时代码如下:
glm(y~offset(logit(exposure))+x,family=binomial(link=“logit”))
在本发明中,exposure即基于全量样本除缺失特征x1外的信息得出的模型结果,而特征x1未缺失的用户样本在exposure基础上进一步提升了模型效果。
3.2.3本项目模型采用的评估指标
本项目的模型效果评估基于offset方法应用前后模型的auc和ks。
3.2.4offset算法提升效果
在阶段一中,基于逻辑回归算法的模型效果如下:
在逻辑回归的基础上,加入特征变量x,应用offset方法所得模型表现如下:
从结果的对比来看,在应用offset方法后,模型的稳定性和准确性都有了明显提升。
- 还没有人留言评论。精彩留言会获得点赞!