一种基于DBN-RLSSVM的航煤闪点预测方法与流程
本发明涉及一种基于dbn-rlssvm的航煤闪点预测方法。
背景技术:
常压分馏塔是炼油企业生产煤油、柴油、汽油等的主要装置之一。航空煤油闪点是分馏塔塔顶产品的两个重要的规格分析指标,及时、准确地获取航煤闪点的测量值是进行分馏装置质量控制的关键[1]。然而,由于受到检测技术和工艺条件的限制,在实际生产中航煤闪点无法做到在线实时测量,只能通过定时抽取样本进行离线化验分析获得,存在较大的测量滞后,难以满足实时控制的要求。因此,采用软测量方法对航空煤油闪点进行预测和估计具有重要的意义。
由于分馏过程存在机理复杂,高度非线性、强耦合、大时滞等特点,传统的建模方法往往不能获得理想的效果。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于dbn-rlssvm的航煤闪点预测方法,解决常压分馏装置塔顶产品中航煤闪点不能在线测量的问题,提高模型训练速度,具有较高预测精度和泛化能力。
为实现上述目的,本发明采用如下技术方案:
一种基于dbn-rlssvm的航煤闪点预测方法,包括以下步骤:
步骤s1:采集航煤闪点的测量数据,并进行预处理得到训练样本;
步骤s2:对训练样本进行dbn特征提取,得到训练样本的特征向量;
步骤s3:构建rlssvm模型;
步骤s4:采用gwo算法优化参数摆动因子c和核参数σ,得到dbn-rlssvm软测量预测模型;
步骤s5:将待测分流装置的历史航煤闪点测量数据经过预处理和dbn特征提取后,输入dbn-rlssvm软测量预测模型,得到预测航煤闪点数据。
进一步的,所述dbn特征提取包括预训练和微调两个阶段:
1)预训练阶段,采用逐层无监督的方法来学习网络参数;
2)微调阶段,在dbn的最后一层设置bp网络,接收rbm的输出特征向量作为它的输入特征向量,采用梯度下降算法对整个网络权重进行微调。
进一步的,所述gwo算法具体为:
假定待求解优化问题的维数为d,算法的种群规模为np,第i只灰狼的位置表示为:
xi=(xi1,xi2,,…,xid)
在种群中适应度值最大的个体记为α,适应度值排列第2和3的个体分别记为β和δ,其余个体记为ω;在捕食过程中,狼群在α,β和δ狼的引导下,向食物位置即全局最优解逼近,引导模型如下:
dp=c·xp(t)-x(t)(1)
式中:dp为灰狼和猎物之间的距离;x(t)为第t代灰狼个体的位置;xp(t)为第t代猎物的位置;a为收敛因子,c为摆动因子,由式(3)和(4)确定:
c=2r1(3)
a=2ar2-a(4)
a=2(1-t/tmax)(5)
式中:r1r2为[0,1]之间的随机数;tmax为最大迭代次数;a为控制参数,取值随着算法迭代次数增加而线性递减,灰狼群体通过速度变化和位置更新策略,并借助a和c的随机变化,保障灰狼在全局范围内能够搜索到最优解。
进一步的,所述步骤s1数据预处理具体包括:
(1)数据异常值剔除;
数据异常值剔除主要采用拉伊达准则(3σ准则),即求出一组测量值的均值μ和标准差σ,剔除绝对值大于|μ+3σ|的测量值。
(2)数据归一化;
求出一组数据xi(i=1,2,…,n)中的最大值xmax和最小值xmin,则归一化的数据等于:
进一步的,所述步骤s3具体为:
给定训练集合{(xi,yi)|i=1,2,…,n},其中,xi∈rd为d维训练样本输入,yi∈r为训练样本输出,则输入与输出之间的关系可表示为:
式中,
所求取的f(·)需满足风险要求
rf=remp+rreg(8)
式中,rf为实际风险;remp为经验风险,表示偏离样本的程度;rreg为置信范围,表示模型复杂程度;其中经验风险remp由损失函数确定,损失函数采用如下:
式中,f(xi)为函数的输出值,yi为对应的训练样本值,ε为不敏感度;该损失函数分为3个区域,当偏差|f(xi)-yi|≤ε时,则损失为0,使学习机具有稀疏性;当偏差时,采用高斯损失函数,可以抑制符合高斯分布的观测噪音;当偏差ε≤|f(xi)-yi|≤ε+μ时,加大惩罚力度,可以较好地抑制幅值较大的噪音和异常点;
采用式(8)的损失函数,引入松弛变量ξi,ξi*,并把b2项加到调整项rreg中,根据结构风险最小化原则,将式(9)
系统辨识问题表示为:
式中,c是正则化参数,用于平衡模型复杂度与训练误差;i1表示松弛变量在
根据kkt条件,并引入核函数:
则上述优化问题变为:
式中,
本发明与现有技术相比具有以下有益效果:
本发明采用dbn网络,通过逐层特征变换和抽取,能够提取更深刻的特征信息,克服了pca和pls无法提取非线性特征信息的不足,从而使得dbn-rlssvm模型具有较高的预测精度,能够满足航煤闪点的软测量要求。
附图说明
图1是本发明方法流程图;
图2是本发明一实施例中rbm和dbn网络结构图;
图3是本发明一实施例中dbn特征提取过程。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
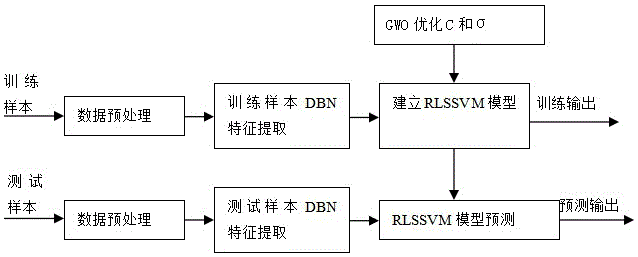
请参照图1,本发明提供一种基于dbn-rlssvm的航煤闪点预测方法,包括以下步骤:
步骤s1:采集航煤闪点的测量数据,并进行预处理得到训练样本,具体包括:
(1)数据异常值剔除;
数据异常值剔除主要采用拉伊达准则(3σ准则),即求出一组测量值的均值μ和标准差σ,剔除绝对值大于|μ+3σ|的测量值。
(2)数据归一化;
求出一组数据xi(i=1,2,…,n)中的最大值xmax和最小值xmin,则归一化的数据等于:
步骤s2:对训练样本进行dbn特征提取,得到训练样本的特征向量;
如图2和3所示,dbn网络的训练过程本质上就是dbn网络对输入数据实现的特征提取的过程,所述dbn特征提取包括预训练和微调两个阶段:
1)预训练阶段,采用逐层无监督的方法来学习网络参数;
2)微调阶段,在dbn的最后一层设置bp网络,接收rbm的输出特征向量作为它的输入特征向量,采用梯度下降算法对整个网络权重进行微调,从而协调和优化整体深度信念网络的参数。使得dbn的特征向量映射达到最优。
步骤s3:构建rlssvm模型;
给定训练集合{(xi,yi)|i=1,2,…,n},其中,xi∈rd为d维训练样本输入,yi∈r为训练样本输出,则输入与输出之间的关系可表示为:
式中,
所求取的f(·)需满足风险要求
rf=remp+rreg(8)
式中,rf为实际风险;remp为经验风险,表示偏离样本的程度;rreg为置信范围,表示模型复杂程度;其中经验风险remp由损失函数确定,损失函数采用如下:
式中,f(xi)为函数的输出值,yi为对应的训练样本值,ε为不敏感度;该损失函数分为3个区域,当偏差|f(xi)-yi|≤ε时,则损失为0,使学习机具有稀疏性;当偏差时,采用高斯损失函数,可以抑制符合高斯分布的观测噪音;当偏差ε≤|f(xi)-yi|≤ε+μ时,加大惩罚力度,可以较好地抑制幅值较大的噪音和异常点;
采用式(8)的损失函数,引入松弛变量ξi,ξi*,并把b2项加到调整项rreg中,根据结构风险最小化原则,将式(9)
系统辨识问题表示为:
式中,c是正则化参数,用于平衡模型复杂度与训练误差;i1表示松弛变量在
根据kkt条件,并引入核函数:
则上述优化问题变为:
式中,
步骤s4:采用gwo算法优化参数摆动因子c和σ,得到dbn-rlssvm软测量预测模型;
所述gwo算法具体为:
假定待求解优化问题的维数为d,算法的种群规模为np,第i只灰狼的位置表示为:
xi=(xi1,xi2,,...,xid)
在种群中适应度值最大的个体记为α,适应度值排列第2和3的个体分别记为β和δ,其余个体记为ω;在捕食过程中,狼群在α,β和δ狼的引导下,向食物位置即全局最优解逼近,引导模型如下:
dp=c·xp(t)-x(t)(1)
式中:dp为灰狼和猎物之间的距离;x(t)为第t代灰狼个体的位置;xp(t)为第t代猎物的位置;a为收敛因子,c为摆动因子,由式(3)和(4)确定
c=2r1(3)
a=2ar2-a(4)
a=2(1-t/tmax)(5)
式中:r1r2为[0,1]之间的随机数;tm閠x为最大迭代次数;a为控制参数,取值随着算法迭代次数增加而线性递减,灰狼群体通过速度变化和位置更新策略,并借助a和c的随机变化,保障灰狼在全局范围内能够搜索到最优解。
步骤s5:将待测分流装置的历史航煤闪点测量数据经过预处理和dbn特征提取后,输入dbn-rlssvm软测量预测模型,得到预测航煤闪点数据。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!