一种基于鼠标交互序列区域行为联合建模的搜索引擎用户满意度评估方法与流程
本发明涉及互联网信息技术领域,尤其涉及一种基于鼠标交互序列区域行为联合建模的搜索引擎用户满意度评估方法。
背景技术:
搜索满意度是基于用户搜索体验来评估搜索引擎质量的重要指标之一,对用户搜索满意度的评估结果能为搜索引擎的商业运营带来最直观的性能描述,对搜索引擎改进排序算法、提高用户忠诚度、增加市场份额等方面都至关重要。
直接从用户收集对搜索满意度的显式反馈过于昂贵,且难以大规模实现,而鼠标交互日志中记录了大量的用户与搜索引擎结果页面的交互信息,如用户移动鼠标、滚动鼠标滚轮、点击结果等,并且这些交互信息与用户的搜索满意度有很强的关联。因此,研究人员提出利用鼠标交互日志来评估用户的搜索满意度。
现有的利用鼠标交互日志来评估用户搜索满意度的方法主要分为两类,即,基于非序列的方法和基于序列的方法。基于非序列的方法通常使用从鼠标交互日志中提取的特征来描述用户与搜索引擎结果页面之间的交互过程,并使用传统的机器学习方法来评估搜索满意度,然而此类方法可能会丢失隐含在序列中的与用户搜索满意度有关的信息。
基于序列的方法利用从鼠标交互日志中提取的鼠标交互序列来描述用户与搜索引擎结果页面的交互过程,并利用长短时记忆网络来学习鼠标交互序列的表示。然而在此类方法所提取的鼠标交互序列中,鼠标交互日志中鼠标光标移动轨迹的空间信息是由锚元素捕获到的,如果用户的鼠标光标没有触发任何锚元素,则所提取的鼠标交互序列中也不会包含鼠标光标移动轨迹的空间信息,因此会丢失一些有用的鼠标光标移动模式。
此外,深度学习方法需要大量的有标注数据,由于有标注数据的收集过程昂贵且耗时,有可能使训练出的模型因训练数据数量不足而出现过拟合。
技术实现要素:
本发明要解决的问题是如何在少量有标注数据的情况下通过鼠标交互日志更有效地学习用户通过鼠标与搜索引擎结果页面交互过程的特征表示,以用于评估搜索引擎用户满意度。
为了解决上述问题,本发明提供了一种基于鼠标交互序列区域行为联合建模的搜索引擎用户满意度评估方法,包括以下步骤:
鼠标交互序列提取,从鼠标交互日志中提取鼠标交互区域以及交互区域对应的行为类型,将区域标识与行为类型构成区域-行为对,区域-行为对以及连续的区域-行为对之间的时间间隔组成鼠标交互序列,采用基于多因子扰动的数据增强策略对鼠标交互序列进行数据增强,并将所有鼠标交互序列统一到固定长度;
分类器构建,构建由区域行为长短时记忆网络层、全连接层、sigmoid激活函数构成的满意度分类器,利用word2vec和skip-gram模型将鼠标交互序列中的行为类型和区域标识转化为向量,并将每个向量化后的鼠标交互序列及其对应的满意度标签作为训练样本,利用训练样本训练用户满意度分类器,得到训练好的满意度分类器;
满意度识别,从待识别样本获取鼠标交互序列再转化为向量表示后输入至训练好的满意度分类器,经计算输出满意度识别结果。
本发明通过区域和行为从鼠标交互日志中提取鼠标交互序列来表示用户与搜索引擎结果页面的交互过程,并引入基于多因子扰动的数据增强策略来缓解模型的过拟合问题。本发明的优点包括:
(1)利用区域来捕获鼠标交互日志中鼠标光标移动轨迹的空间信息,能够保留用户与搜索引擎结果页面交互过程的更多细节;
(2)引入区域行为长短时记忆网络,其能够在捕获鼠标交互序列中区域和行为之间交互关系的同时,避免使网络受到更高训练复杂度的影响;
(3)引入基于多因子扰动的数据增强策略,从而增加鼠标交互序列数据的模式变化,提高区域行为长短时记忆网络的泛化能力。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动前提下,还可以根据这些附图获得其他附图。
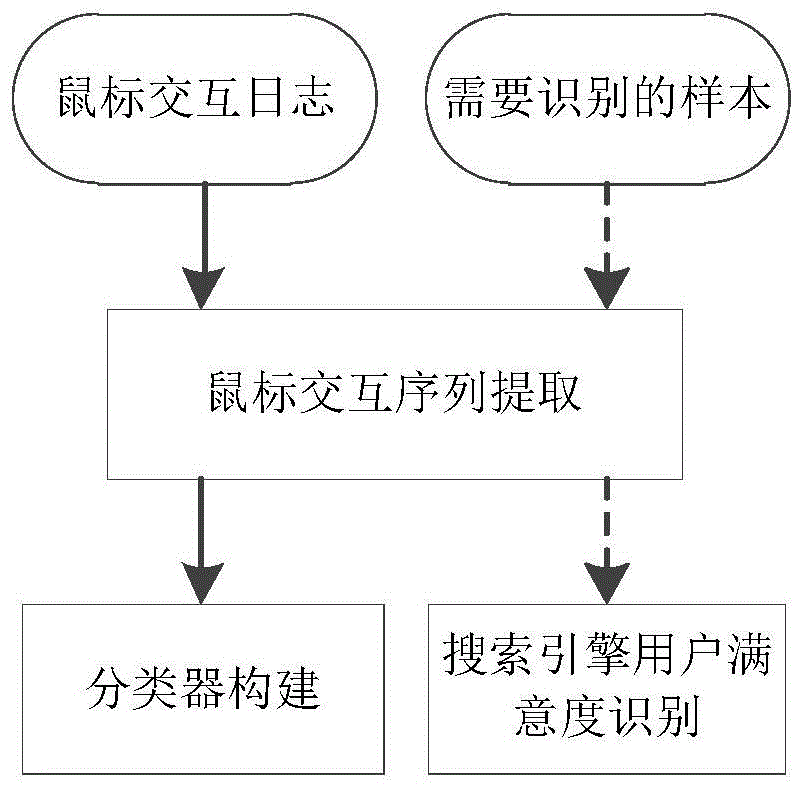
图1为基于鼠标交互序列区域行为联合建模的搜索引擎用户满意度评估方法的流程图。
图2为鼠标交互序列提取部分的流程图。
图3为分类器构建部分的流程图。
图4为区域行为长短时记忆网络的单元结构图。
图5为用户满意度分类器的网络架构图。
图6为搜索引擎用户满意度识别部分的流程图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。
本发明要解决的问题是如何在少量有标注数据的情况下通过鼠标交互日志更有效地学习用户通过鼠标与搜索引擎结果页面交互过程的特征表示,以用于评估搜索引擎用户满意度。
为了解决上述问题,本实施例提供了一种搜索引擎用户满意度评估方法,首先通过区域和行为从鼠标交互日志中提取鼠标交互序列来表示用户与搜索引擎结果页面的交互过程;其次,引入基于多因子扰动的数据增强策略来增加鼠标交互序列的数量;再次,引入区域行为长短时记忆网络学习鼠标交互序列的特征表示,并建立搜索引擎用户满意度分类器;最后,利用构建的用户满意度分类器识别给定样本的用户满意度标签。如图1所示,该搜索引擎用户满意度评估方法分为鼠标交互序列提取、分类器构建、搜索引擎用户满意度识别三个部分,具体实施过程如下:
如图2所示,鼠标交互序列提取主要包括:
步骤1-1,将鼠标交互日志以搜索引擎结果页面为单位进行划分,每个搜索引擎结果页面对应一段鼠标交互日志,将鼠标交互日志中的鼠标光标坐标转换成区域标识r。
此步骤中,将搜索引擎结果页面的空间划分成g个相同大小的正方形网格区域,每个区域用区域标识r来表示,并将落入同一区域的所有鼠标光标的坐标都映射成同样的区域标识。
步骤1-2,将鼠标交互日志中的每个区域标识r及其对应的行为类型a构成一个区域-行为对,记为(r,a),并从搜索引擎结果页面所对应的鼠标交互日志中提取出由n个区域-行为对和连续的区域-行为对之间的时间间隔t组成的鼠标交互序列s,其形式化表示为s=<(r1,a1),t1,(r2,a2),t2,...,(rn-1,an-1),tn-1,(rn,an)>。
在此步骤中,用户的行为a包括以下四种类型:
1)移动鼠标;
2)滚动鼠标滚轮;
3)鼠标点击返回的搜索引擎结果页面上的某个结果;
4)结束搜索。
如果鼠标交互日志中一个区域-行为对的区域标识与前一个区域-行为对中的区域标识不同,或鼠标交互日志中一个区域-行为对的行为类型与前一个区域-行为对中的行为类型不同,则将这个区域-行为对添加到鼠标交互序列s。
步骤1-3,引入基于多因子扰动的数据增强策略对鼠标交互序列进行数据增强。
具体地,引入偏移因子poff轻微扭曲鼠标交互序列所对应的鼠标交互日志中的鼠标光标坐标,将鼠标光标坐标转换成区域标识r后,通过步骤1-2重新提取鼠标交互序列;同时引入随机生成的扰动因子tflu轻微扰动重新提取的鼠标交互序列中连续区域-行为对之间的时间间隔,从而生成新的鼠标交互序列。
给定鼠标交互序列s=<(r1,a1),t1,(r2,a2),t2,...,(rn-1,an-1),tn-1,(rn,an)>,引入偏移因子poff轻微扭曲鼠标交互序列所对应的鼠标交互日志中的鼠标光标坐标,给定鼠标光标的坐标(px,py),扭曲坐标的方式如下:
其中,gaussian(0,1)表示期望为0,方差为1的高斯分布,poff的取值为30像素。
在扭曲鼠标光标坐标后,将鼠标光标坐标转换成区域标识r,并通过步骤1-2重新提取鼠标交互序列,其形式化表示为
步骤1-4,对所有提取出的鼠标交互序列重复执行m次步骤1-3。
步骤1-5,根据每个鼠标交互序列中连续区域-行为对之间的时间间隔引入相应数量的虚拟停留行为,引入虚拟停留行为的鼠标交互序列si可以表示成由k个区域-行为对组成的有序序列,其形式化表示为si=<(r1,a1),(r2,a2),...,(rk-1,ak-1),(rk,ak)>。
在此步骤中,虚拟停留行为包括基于搜索引擎结果页面的虚拟停留行为和基于点击结果页面的虚拟停留行为,其中基于搜索引擎结果页面的虚拟停留行为表示用户在搜索引擎结果页面的区域r执行了行为a,这个状态持续了一个固定的时长tactive;基于点击结果页面的虚拟停留行为表示用户在点击的结果页面停留了一个固定的时长tidle。
给定一个包含n个区域-行为对的鼠标交互序列,用来表示两个连续区域-行为对之间时间间隔的虚拟停留行为数量naction为:
其中,ti表示区域-行为对(ri,ai)和(ri+1,ai+1)之间的时间间隔。
步骤1-6,使用截断或填充的方式将所有鼠标交互序列的长度统一为l。
在此步骤中,如果一个鼠标交互序列的长度大于l,则截断其长度超出l的部分;如果一个鼠标交互序列的长度小于l,则在该序列的首端用占位符0来填充直至其长度等于l。
如图3所示,分类器构建部分主要包括:
步骤2-1,读取通过鼠标交互序列提取部分得到的所有鼠标交互序列,作为训练数据。
步骤2-2,使用word2vec学习所有鼠标交互序列中出现过的所有行为类型的向量表示,将每个鼠标交互序列中的行为a都转换成对应的向量va;使用基于采样分布的skip-gram模型学习所有鼠标交互序列中出现过的所有区域标识的向量表示,将每个鼠标交互序列中的区域标识r都转换成对应的向量vr。
具体地,把鼠标交互序列分解成只包含行为类型的行为序列和只包含区域标识的区域序列;
word2vec是google提出的词向量计算框架,把所有行为序列看作训练文本,行为序列中的行为看作词,可使用word2vec学习出行为序列中出现过的所有行为类型的向量表示;
对区域序列中的每个区域r,为了创建其上下文,通过以下区域采样分布来对其邻居r′∈n(r)进行随机采样:
其中,||r′-r||2表示区域r和区域r′质心坐标之间的欧几里得距离,θ>0是空间距离尺度参数,v∈n(r)表示区域r的邻居。给定一个区域,区域采样分布趋向于对那些在空间上与给定区域邻近的区域进行采样,将采样结果作为给定区域的上下文,再使用负采样(negativesampling)算法来学习区域序列中出现过的所有区域标识的向量表示。
每个行为类型和区域标识都由一个z维行向量来表示,z根据经验人为设定。
步骤2-3,将每个向量化后的鼠标交互序列及其对应的满意度标签作为一个训练样本来构建训练数据集。
一个训练样本可以表示为(x,y),其中y∈{0,1}表示用户满意度的标签,0表示不满意的类,1表示满意的类;
步骤2-4,构建由l个区域行为长短时记忆网络单元组成的区域行为长短时记忆网络。
具体地,区域行为长短时记忆网络单元包括区域门、行为门、遗忘门、输出门、细胞,其中区域门用来存储区域信息vr,行为门用来存储行为信息va,细胞保存了两部分信息,一部分是由遗忘门来决定的前一个区域行为长短时记忆网络单元的细胞能保留下来的信息,另一部分是由区域门和行为门共同决定的当前输入能保留下来的信息,输出门用来决定细胞中可以输出的信息。
在此步骤中,所构建的区域行为长短时记忆网络的单元结构图如图4所示,更新公式如下:
rt=σr(rtwrr+ht-1whr+wcr⊙ct-1+br)(5)
at=σa(atwaa+ht-1wha+wca⊙ct-1+ba)(6)
ft=σf(rtwrf+ht-1whf+wcf⊙ct-1+bf)(7)
ct=ft⊙ct-1+rt⊙at⊙σc(rtwrc+ht-1whc+bc)(8)
ot=σo(rtwro+atwao+ht-1who+wco⊙ct+bo)(9)
ht=ot⊙σh(ct)(10)
其中rt、at、ft、ot分别表示第t个对象的区域门、行为门、遗忘门、输出门;ct表示细胞激活向量;rt、at、ht分别表示区域特征向量、行为特征向量、隐藏输出向量;σr、σa、σf、σo是sigmoid函数;σc和σh是双曲正切函数;wrr、waa、wrf、wro、wao、who、whr、wha、whf权重参数将不同的输入和门与不同的记忆细胞和输出相连接;br、ba、bf、bo是相应的偏差;ct的更新公式有两部分:一部分是由ft控制的前一个细胞状态ct-1,另一部分是从rt、at、非线性σc的输出的点乘⊙创建出的新的输入状态;可选的窥视孔连接权重wcr、wca、wcf、wco会对区域门、行为门、遗忘门、输出门产生进一步的影响。
步骤5,利用训练数据集中的所有训练样本来训练由区域行为长短时记忆网络层、全连接层、sigmoid激活函数构成的用户满意度分类器,通过最小化交叉熵(crossentropy)的目标来调整网络参数。
在此步骤中,用户满意度分类器的网络架构图如图5所示,其中ralstm单元表示区域行为长短时记忆网络单元。满意的类概率y′的计算公式如下:
其中,e表示以自然对数为底的指数函数,α是前一层输出的向量,w是权重向量。
如图6所示,搜索引擎用户满意度识别部分包括以下过程:
步骤3-1,对于待识别搜索满意度的样本,通过鼠标交互序列提取部分获取鼠标交互序列集
步骤3-2,从分类器构建部分读取所有行为类型的向量表示以及所有区域标识的向量表示,将
步骤3-3,通过构建的用户满意度分类器获取
步骤3-4,利用
在此步骤中,通过对类概率求平均值的方式来组合
如果yt=0表示样本的最终分类结果为不满意,如果yt=1则表示样本的最终分类结果为满意。
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!