一种汉字词语频度存储方法与流程
本发明属于汉字存储
技术领域:
,涉及一种汉字词语频度存储方法。
背景技术:
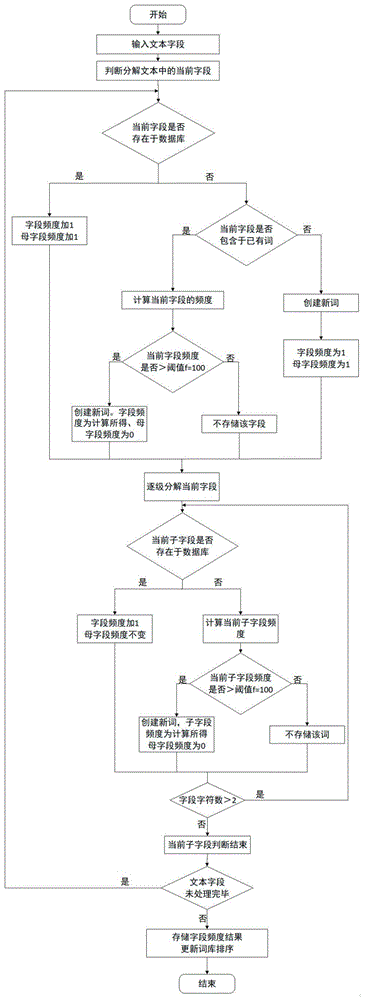
:现有字段频度存储主要是用于分析语料特征即指词语及句子的特点、意义,重点关注每个语料之间的差异;现有字段频度统计主要统计词本身频度,不考虑其当前字段是否包含于某一个已有字段中,从而造成大量重复存储。现有字段频度存储主要是存储该字段与其频度,存储次数多,存储空间大;现有词频统计存储、词库都是针对大众的,专业领域要形成专用词库,需要花费一定金额定制,且后期更新词库又会遇到新的费用增加问题。现有词频存储只针对可以称之为词的词,例如“专利”、“申请”,但不针对语义连贯、使用频度高但不是汉语词汇的词进行存储处理,例如“已提交”、“严格实施流量控制”、“我的工作”,想要对这样的非词语但具备连贯语义的汉语熟语与其频度的统计存储比较困难。技术实现要素:本发明的目的是提供一种汉字词语频度存储方法,解决了现有词频度存储技术中存在的占用存储空间大的问题。本发明采用的技术方案是,一种汉字词语频度存储方法,具体步骤如下:步骤1,输入当前文本字符至数据库,将当前文本字符分为若干个当前字段;步骤2,判断当前字段和当前字段的各级子字段是否为数据库中的已有字段以及判断当前字段是否为已有字段的子字段,基于判断结果存储当前字段及当前字段的各级子字段的字段频度。本发明的特点还在于,按照字段频度结果将全部当前字段及各级子字段进行词频升序排列。将当前文本字符分为若干个当前字段是通过非词字符、词字符、可忽略字符来划分。步骤2具体按照如下步骤实施:步骤2.1,判断当前字段是否为数据库中的已有字段:若当前字段为数据库中的已有字段,则将已有字段频度加一存储,并将已有字段的母字段频度加一存储,并转入步骤2.4;否则转入步骤2.2;步骤2.2,判断当前字段是否为数据库中的已有字段的子字段:若当前字段不是数据库中的已有字段的子字段,则存储当前字段,其中当前字段的频度为一,当前字段的母字段的频度为一,并转入步骤2.4;否则转入步骤2.3;步骤2.3,计算当前字段频度,若当前字段频度大于阈值f,则存储当前字段,其中当前字段的频度为计算所得值,当前字段的母字段频度为0,并转入步骤2.4;否则转入步骤2.4;步骤2.4,将当前字段分解为两个下一级字段,判断每个下一级字段是否为数据库中的已有字段,并根据判定结果存储下一级字段。步骤2.1中判断当前字段是否为数据库中的已有字段时,先将当前字段与所述数据库中大于等于当前字段字符数的已有字段进行比对。步骤2.4判断每个下一级字段是否为数据库中的已有字段,并给予判定结果存储下一级字段具体按照如下步骤实施:步骤2.4.1,判断下一级字段是否为数据库中的已有字段:若下一级字段为数据库中的已有字段,则将已有字段频度加一进行存储;否则转入步骤2.4.2;步骤2.4.2,计算下一级字段的字段频度,若下一级字段的字段频度大于阈值f,则存储下一级字段;否则转入步骤2.4.3;步骤2.4.3,将下一级字段再分解为所述下一级字段的下一级字段,分解所得的下一级字段的下一级字段数量为两个;步骤2.4.4,重复步骤2.4.1-步骤2.4.3直到分解所得的下一级字段的字符数为二时则完成当前字段的各级子字段的存储。步骤2.3及步骤2.4.2中计算字段频度具体为:p=∑(pa×pb),p表示待计算字段的频度,a表示待计算字段的母字段,b表示a的母字段,pa表示a的频度,pb表示b的频度。将字段分解为下一级字段的方法是:去掉字段的第一个汉字,形成下一级字段;再去掉字段的最后一个汉字,形成下一级字段。步骤2.2、步骤2.3、步骤2.4.1、步骤2.4.2中存储字段方式具体为:按照字段序号,字段名称,字段字符数,字段频度,字段的母字段频度进行存储。步骤2.4.2中,存储下一级字段,其中的下一级字段频度为计算所得值,下一级字段的母字段频度为0。本发明一种汉字词语频度存储方法具有至少以下有益效果,一、可以将输入的当前文本字符进行快速识别非词字符、词字符、可忽略字符进行识别,以便快速的识别最长的当前字段;二、能够判断若当前字段是否包含于某一个已有字段中,能够完全统计输入的当前字段出现的完整次数,利用权重占比排序,使得当前字段与已有字段存在包含关系时,能够优先识别调用;三、实际上,数据库中可以只存储首次出现的当前字段,就能计算出所有词的准确词频。只有数据库中没有出现该当前字段,或者当前字段的各级子字段的频度超过某个阈值时基于加快运算速度的需要,才会对该当前字段及当前字段的各级子字段创建新词后存储;对于绝大多数不是数据库中已有字段的当前字段及频度低的当前字段的各级子字段,根本不需要存储就能准确掌握其频度信息,进而节省了存储空间;四、当前字段和数据库中所有已有字段比对,按照频度结果将所有字段进行词频升序、词频降序排列,词语频度大的排序靠前,方便后续调用;五、以汉字词语频度存储方法形成自己的词库,使用人员在输入词语时按照词库内词语权重进行重要词语推荐,我们可以将其定义为每个专业或领域的专用词库,进而为每个专业领域的人员提高文字工作效率打下基础。附图说明图1是本发明一种汉字词语频度存储方法的处理流程图;图2是本发明一种汉字词语频度存储方法的各级子字段比对的树的前序遍历的示意图;图3是本发明一种汉字词语频度存储方法的当前字段及当前字段的各级子字段的比对顺序的示意图。具体实施方式下面结合附图和具体实施方式对本发明进行详细说明。本发明所采用的技术方案是一种汉字词语频度存储方法,如图1所示,具体按照如下步骤实施:步骤1,输入当前文本字符至数据库,将当前文本字符通过非词字符、词字符、可忽略字符来划分为若干个当前字段,其中的文本字符可以是一长篇文章,也可以是一段话,其中的当前字段具体为当前词;步骤2,判断当前字段及当前字段的各级子字段是否为数据库中的已有字段及判断当前字段是否为已有字段的子字段,基于判断结果存储当前字段及当前字段的各级子字段的字段频度,具体按照如下步骤实施:步骤2.1,判断当前字段是否为数据库中的已有字段先将字符最长的当前字段与所述数据库中大于等于当前字段字符数的已有字段进行比对:若当前字段为数据库中的已有字段,则将已有字段频度加一存储,并将已有字段的母字段频度加一存储,并转入步骤2.4;否则转入步骤2.2;步骤2.2,判断当前字段是否为数据库中的已有字段的子字段:若当前字段不是数据库中的已有字段的子字段,则存储当前字段,其中当前字段的频度为一,当前字段的母字段的频度为一,并转入步骤2.4;否则转入步骤2.3;步骤2.3,计算当前字段频度,计算字段频度具体为:p=∑(pa×pb),p表示当前字段的频度,a表示当前字段的母字段,b表示a的母字段,pa表示a的频度,pb表示b的频度,若当前字段频度大于阈值f,则存储当前字段,其中当前字段的频度为计算所得值,当前字段的母字段频度为0,并转入步骤2.4;否则转入步骤2.4;步骤2.4,将当前字段分解为两个下一级字段,判断每个下一级字段是否为数据库中的已有字段,并根据判定结果存储下一级字段,具体按照如下步骤实施:步骤2.4.1,判断下一级字段是否为数据库中的已有字段:若下一级字段为数据库中的已有字段,则将已有字段频度加一进行存储;否则转入步骤2.4.2;步骤2.4.2,计算下一级字段的字段频度,计算字段频度具体为:p=∑(pa×pb),p表示待计算字段的频度,a表示待计算字段的母字段,b表示a的母字段,pa表示a的频度,pb表示b的频度,若下一级字段的字段频度大于阈值f,其中阈值f=100,则存储下一级字段,其中的下一级字段频度为计算所得值,下一级字段的母字段频度为0;否则转入步骤2.4.3;步骤2.4.3,将下一级字段分解为下一级字段的下一级字段,下一级字段的下一级字段为两个,即将当前字段的一级子字段分解为当前字段的两级子字段,通过去掉字段的第一个汉字,形成下一级字段;再去掉字段的最后一个汉字,形成下一级字段;步骤2.4.4,重复步骤2.4.1-步骤2.4.3直到分解所得的下一级字段的字符数为一时则完成当前字段的各级子字段的存储。步骤2.2、步骤2.3、步骤2.4.1、步骤2.4.2中存储字段方式具体为:按照字段序号,字段名称,字段字符数,字段频度,字段的母字段频度进行存储。最后,按照字段频度结果将全部当前字段及各级子字段进行词频升序排列。本发明中,非词字符:不可能包括在词中的字符,例如“、”“。”“,”“......”等符号;词字符:包含于两个非词字符中间的正常的汉语词语;可忽略字符:在词字符中存在,但不影响词语连贯意义的字符。例如:“——”;一级子字段:将当前字段去掉第一个汉字形成的当前字段的下一级字段;或是将当前字段去掉最后一个汉字形成的当前字段的下一级字段。二级子字段:将一级子字段去掉第一个汉字形成的一级子字段的下一级字段;或是将一级子字段去掉最后一个汉字形成的一级子字段的下一级字段;三级子字段、四级子字段等依次类推。母字段:已知有字段“m”及字段“n”,字段“m”包含字段“n”,则字段“m”为字段“n”的母字段。子字段:已知有字段“m”及字段“n”,字段“n”被字段“m”包含,则字段“n”为字段“m”的子字段。本发明关于对文本字符中当前字段的子字段与数据库的已有字段比对顺序采用树的前序遍历,如图2所示,处理顺序为:o→p→r→u→v→q→s→w→t。实施例1设定数据库存储的已有字段如表1所示,其中,每个字母均代表一个汉字。表1数据库中存储的已有字段序号字段名称字符数字段频度母字段频度1abcde5522bcd3323abc3214cde3115ab211第一步,输入数据库的文本字符为:“abcde,abcd,ab,cde,ef。”;第二步,识别判断文本字符内的当前字段为:“abcde”、“abcd”、“ab”、“cde”、“ef”;表2文本字符的当前字段序号字段名称字符数1abcde52abcd43ab24cde35ef2第三步,对划分的若干个当前字段进行存储处理;(1)在数据库中查询当前字段,若在数据库中能找到当前字段,则当前字段频度加1,其母字段频度也加1,存储至数据库;(2)若在数据库中不能找到当前字段,则判断当前字段是否包含于已有字段中,若包含于已有字段进行下一步操作,若不包含则存储当前字段,其中当前字段的频度为1,其母字段频度也为1,存储至数据库;(3)若在数据库中找到包含有当前字段的已有字段,则计算当前字段频度,计算当前字段频度具体为:p=∑(pa×pb),p表示当前字段的频度,a表示当前字段的母字段,b表示a的母字段,pa表示a的频度,pb表示b的频度,若当前字段频度大于阈值f(阈值为100),则存储当前字段,其中当前字段的频度为计算所得值,当前字段的母字段频度为0;若当前字段频度小于f,则本步骤不对数据库进行修改。将当前字段“abcde”、“abcd”、“ab”、“cde”、“ef”出现的当前字段与数据库中已有字段比对,具体按照如下步骤实施:(1)“abcde”字符数为5,优先匹配数据库中字符数为5的已有字段;则将当前字段“abcde”的第一个字符与数据库中已有字段“abcde”的第一个字符进行比对,“a”与“a”匹配;则将当前字段“abcde”的第二个字符“b”与数据库中已有字段“abcde”的第二个字符“b”进行比对,“ab”与“ab”匹配;则将当前字段“abcde”的第三个字符“c”与数据库中已有字段“abcde”的第三个字符“c”进行比对,“abc”与“abc”匹配;则将当前字段“abcde”的第四个字符“d”与数据库中已有字段“abcde”的第四个字符“d”进行比对,“abcd”与“abcd”匹配;则将当前字段“abcde”的第五个字符“e”与数据库中已有字段“abcde”的第五个字符“e”进行比对,“abcde”与“abcde”匹配;则数据库中找到当前字段,则当前字段频度加1,其母字段频度也加1,存储至数据库。则当前字段“abcde”在数据库中的存储信息如表3所示:表3当前字段“abcde”在数据库中的存储信息序号字段名称字符数字段频度母字段频度1abcde5632bcd3323abc3214cde3115ab211(2)“abcd”字符数为4,优先匹配数据库中字符数为4的已有字段,若匹配不到则匹配字符数大于等于5的字段;则将当前字段“abcd”未能匹配到字符数为4的已有字段,则为当前字段匹配数据库中大于等于5的已有字段;则将当前字段“abcd”的第一个字符与数据库中已有字段“abcde”的第一个字符进行比对,“a”与“a”匹配;则将当前字段“abcd”的第二个字符“b”与数据库中已有字段“abcde”的第二个字符“b”进行比对,“ab”与“ab”匹配;则将当前字段“abcd”的第三个字符“c”与数据库中已有字段“abcde”的第三个字符“c”进行比对,“abc”与“abc”匹配;则将当前字段“abcd”的第四个字符“d”与数据库中已有字段“abcde”的第四个字符“d”进行比对,“abcd”与“abcd”匹配;在数据库中找到包含于其母字段的当前字段,则当前字段“abcd”的字段频度为:6*3=18,(设定阈值为100),当前字段“abcd”的字段频度小于100,则本步骤不对数据库进行修改。(3)“ab”字符数为2,优先匹配数据库中字符数为2的已有字段;将当前字段“ab”的第一个字符与数据库中已有字段“ab”的第一个字符进行比对,“a”与“a”匹配;则将当前字段“ab”的第二个字符“b”与数据库中已有字段“ab”的第二个字符“b”进行比对,“ab”与“ab”匹配比对结束;则数据库中找到当前字段,则当前字段频度加1,其母字段频度也加1,存储至数据库。则当前字段“ab”在数据库中的存储信息如表4所示:表4当前字段“ab”在数据库中的存储信息(4)“cde”字符数为3,优先匹配数据库中字符数为3的已有字段;将当前字段“cde”的第一个字符与数据库中已有字段“cde”的第一个字符进行比对,“c”与“c”匹配;则将当前字段“cde”的第二个字符“d”与数据库中已有字段“cde”的第二个字符“d”进行比对,“cd与“cd”匹配;则将当前字词“cde”的第三个字符“e”与数据库中已有字段“cde”的第三个字符“e”进行比对,“cde”与“cde”匹配,比对结束;则数据库中找到当前字段,则当前字段频度加1,其母字段频度也加1,存储至数据库。则当前字段“cde”在数据库中的存储信息如下表5所示:表5当前字段“cde”在数据库中的存储信息序号字段名称字符数字段频度母字段频度1abcde5632bcd3323abc3214cde3225ab222(5)“ef”字符数为2,优先匹配数据库中字符数为2的已有字段;若匹配不到则匹配字符数大于等于3的已有字段;将当前字段“ef”的第一个字符与数据库中已有字段“cde”的第一个字符进行比对,“e”与“c”不匹配,进行下一项比对;将当前字段“ef”的第一个字符与数据库中已有字段“abc”的第一个字符进行比对,“e”与“a”不匹配,进行下一项比对;将当前字段“ef”的第一个字符与数据库中已有字段“bcd”的第一个字符进行比对,“e”与“b”不匹配,进行下一项比对;将当前字段“ef”的第一个字符与数据库中已有字段“abcde”的第一个字符进行比对,“e”与“a”不匹配,则数据库中不存在当前字段;对于该字段创建独立新词“ef”,字段频度为1,母字段频度也为1。则数据库中所有当前字段的存储信息如6所示:表6文本字符中所有当前字段的存储信息序号字段名称字符数字段频度母字段频度1abcde5632bcd3323cde3224ab2225abc3216ef211第四步,将当前字段逐级分解,一直到最小子字段(只包含两个汉字的词)。每一级的分解方法都是,去掉该字段的第一个汉字,形成该字段的下一级字段;去掉该字段的最后一个汉字,也形成该字段的下一级字段。将当前字段分解为两个下一级字段,判断每个下一级字段是否为数据库中的已有字段,并根据判定结果存储下一级字段。各级子字段的处理顺序实际上是树的前序遍历。(1)当前字段“abcde”的各级子字段如表7所示:(2)当前字段“abcd”的各级子字段为如表8:(3)当前字段“ab”的字符数为2,无下一级字段,即无子字段;(4)当前字段“cde”的各级子字段如表9:(5)当前字段“ef”的字符数为2,无下一级字段,即无子字段。表7当前字段“abcde”的各级子字段表8当前字段“abcde”的各级子字段表9当前字段“abcde”的各级子字段第五步,本步骤处理当前字段分解产生的各级子字段。(1)查询数据库,若在数据库中能找到当前字段的子字段,则子字段频度加1,母字段频度不变,存储至数据库;(2)若在数据库中不能找到当前字段的子字段,则找到数据库中所有包含该子字段的其他字段,计算当前字段的子字段频度具体为:p=∑(pa×pb),p表示当前字段的子字段频度,a表示数据库中该子字段的母字段,b表示a的母字段,pa表示a的频度,pb表示b的频度,。若子字段频度大于等于某个阈值f(比如f=100),则对该子字段创建新词强制存储,其频度为本步骤计算出来的频度,母字段频度为0。如果当前字段频度小于f,则本步骤不对数据库进行修改。第五步中当前字段的各级子字段按以下顺序与数据库中已有字段进行比对。例如:当前字段“abcde”的各级子字段与数据库的比对顺序如下图3所示为:第六步,对第一步中获取的文本,按第二步分解出的每个当前字段重复第三步、第四步、第五步的全部过程,直至文本处理完毕;然后再按第一步输入新的文本,继续处理。第七步,在按上述步骤处理完所有文本后,将词频超过一定阈值的所有词提取出来,按一定顺序排序后输出,更新目标数据库。第八步,上述步骤中的存储是按照按照序号、当前字段名称、字符数、当前字段频度、当前字段对应的母字段频度进行存储;存储完的当前字段按照权重进行词频升序、词频降序排列。按照以上步骤将对文本字符处理后,数据库中的存储信息如表10所示:表10数据库中文本字符的存储结果序号字段名称字符数字段频度母字段频度1abcde5632bcd3623ab2424abc3415cde3326ef211当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1