基于脉动阵列的长短期记忆神经网络前向加速系统及方法与流程
本发明属于人工智能算法硬件加速领域,尤其涉及了一种基于脉动阵列的长短期记忆神经网络前向加速系统。
背景技术:
随着神经网络算法在不同领域取得越来越多的成就,传统的深度神经网络(dnn)也暴露出了一些问题:只能处理当前输入的信息。为了解决这一问题,循环神经网络(rnn)应运而生,而长短期记忆(lstm)神经网络则是目前最主流的循环神经网络的变体,其引入了记忆单元以解决长期依赖性问题。长短期记忆神经网络已被广泛应用于语音识别、图像处理和机器翻译等领域。
由于引入了所谓的“门”单元,lstm网络包含了较多的矩阵-向量乘法运算,该系列算法属于计算密集型算法,通常需要采用硬件加速方式实现,目前较常用的加速手段包括cpu、gpu、asic等。其中cpu和gpu都属于通用处理器,需要进行取指令、指令译码、指令执行的操作,在面对计算密集型算法时无法达到更高的数据传输和计算效率,且能耗较大;asic是根据需求特定的专用处理芯片,具有低功耗、高性能、面积小等优点,不过其也存在设计灵活性不高且通常不可配置等问题,如何提高lstm的硬件加速性能、配置灵活性和可复用性成为了研究的热点。
技术实现要素:
本发明的目的是克服上述背景技术中的lstm前向运算硬件实现的不足,提出一种基于脉动阵列的多隐层可复用lstm前向硬件加速架构,支持网络大小,包括输入层节点数、隐藏层节点数、时间序列长度等可配置,提高了硬件加速效率,并实现了输入层-隐藏层前向运算的可复用,具体通过以下技术方案实现:
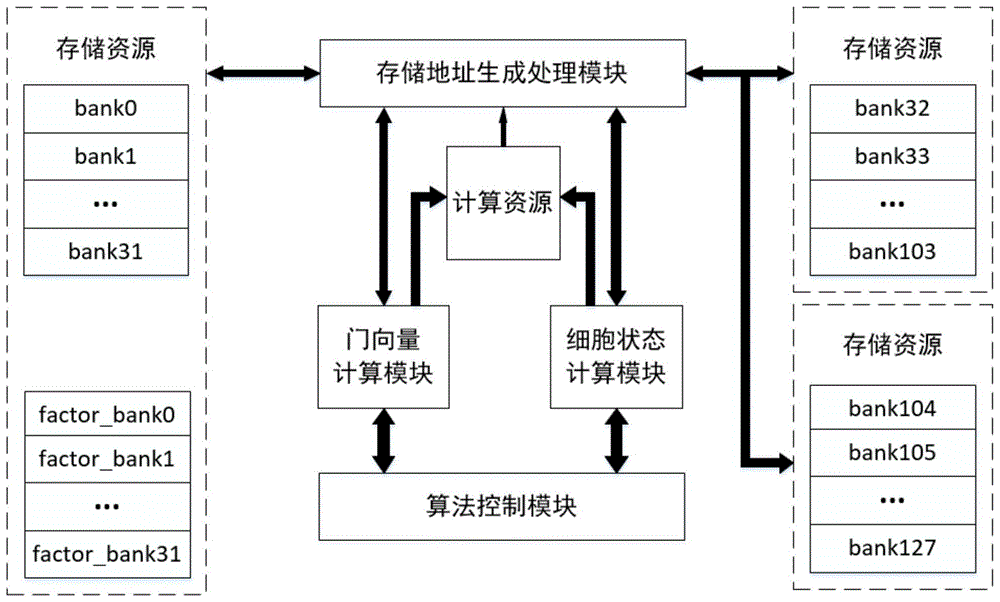
所述基于脉动阵列的长短期记忆神经网络前向加速系统,包括:
算法控制模块,控制计算流程,输出控制信号,控制门向量计算模块和细胞状态计算模块的交替运行;
门向量计算模块,接收源数据,根据所述控制信号将所述源数据传入脉动阵列,依次计算遗忘门向量ft,输入门向量it,候选门向量zt以及输出门向量ot,当同一个时间序列t中的ot计算完成后产生一个细胞状态计算模块的启动信号;所述源数据包括输入层输入数据、神经元权重项以及神经元偏置项;
细胞状态计算模块,接收所述启动信号后读入门向量数据,计算神经元状态值ct和隐藏层输出值ht;
存储模块,接收和输出存储门向量计算模块与细胞状态计算模块的计算结果。
所述基于脉动阵列的长短期记忆神经网络前向加速系统的进一步设计在于,所述长短期记忆神经网的输入层-隐藏层通过在系统配置阶段实施多条指令配置,将前一隐藏层的输出作为下一隐藏层的输入,实现隐藏层的多次调用,完成任意隐藏层层数的lstm前向计算。
所述基于脉动阵列的长短期记忆神经网络前向加速系统的进一步设计在于,所述门向量计算模块和细胞状态计算模块采用类脉动阵列,所述类脉动阵列中每个计算单元包含乘法器、加法器以及按位与和比较器。
所述基于脉动阵列的长短期记忆神经网络前向加速系统的进一步设计在于,所述类脉动阵列为32×32的类脉动阵列,最高支持32批次数据的并行处理。
所述基于脉动阵列的长短期记忆神经网络前向加速系统的进一步设计在于,所述存储模块包括数据存储器和系数存储器,数据存储器和系数存储器统一编址;门向量计算模块的源数据存储方式为:输入层的输入数据和隐藏层计算结果ht存入同一块bank区域,每个bank存放一个批次的输入数据和隐藏层计算结果;神经元权重存入同一块bank区域,其中一个隐藏层神经元的所有权重存放在同一个bank中;偏置项按地址递增的方式存入同一块bank区域。
所述基于脉动阵列的长短期记忆神经网络前向加速系统的进一步设计在于,所述门向量计算模块的计算结果存放方式为:四个门向量的计算结果分别存放在不同的bank区域,其中同一批次的计算结果以地址递增的方式存入各自对应的bank,一个bank存放四个批次的数据。
所述基于脉动阵列的长短期记忆神经网络前向加速系统的进一步设计在于,细胞状态计算模块的计算流程为:将四个门向量计算结果从存储模块中读出并进行重组,以乘累加的形式传入类脉动阵列进行计算,与门向量计算模块共用计算资源。
所述基于脉动阵列的长短期记忆神经网络前向加速系统的进一步设计在于,还包括存储地址生成模块,存储地址生成模块生成存储地址信号和控制信号,所述存储地址信号产生存储地址与物理存储模块地址的映射;所述控制信号控制存储模块进行源数据的读写。
采用所述基于脉动阵列的长短期记忆神经网络前向加速系统长短期记忆神经网络前向硬件加速方法,包括如下步骤:
步骤1)配置网络参数,所述参数包括:输入层节点数、隐藏层节点数、时间序列长度以及批处理批次;
步骤2)存储地址生成处理模块将源数据存入存储模块,所述源数据包括:输入层输入数据、神经元权重项以及神经元偏置项;
步骤3)算法控制模块接收到系统的启动信号后,启动门向量计算模块,将源数据传入脉动阵列,依次计算各门向量ft,it,zt,ot并存入存储模块,生成门向量计算模块的结束信号和细胞状态计算模块的启动信号;
步骤4)细胞状态计算模块接收到对应的启动信号后开始从存储模块中读出门向量数据,计算神经元状态值ct和隐藏层输出值ht,存入存储模块,并生成一个细胞状态计算模块的结束信号;
步骤5)算法控制模块接收到对应的结束信号后再次启动门向量计算模块,重复上述步骤3)和步骤4),直到完成所有时序的计算;
步骤6)在完成步骤5)的基础上,若配置阶段配置了多隐层的网络,则重复上述步骤2)直至步骤5),直到完成所有层数的运算;
所述基于脉动阵列的长短期记忆神经网络前向加速方法的进一步设计在于,所述步骤1)中若需要计算多隐层的网络则将包含上述参数的指令进行多次配置。
本发明的优点
本发明提供的基于脉动阵列的多隐层可复用的长短期记忆神经网络前向加速系统及方法,将算法按计算复杂度进行划分,采用脉动阵列,提高了计算效率;并支持网络节点数和时间序列长度可配,配置灵活;实现了输入-隐藏层的可复用,可扩展性较好。
附图说明
图1为本发明基于脉动阵列的长短期记忆神经网络前向加速系统的示意图。
图2是数据存储方式示意图。
图3是加速系统的逻辑串联示意图。
具体实施方式
下面结合附图对本发明方案进行详细说明。
如图1所示,本实施例的基于脉动阵列的多隐层可复用lstm前向硬件加速架构,主要由算法控制模块、门向量计算模块、细胞状态计算模块和存储地址生成处理模块组成。
存储地址生成处理模块,负责生成神经元操作数、系数和偏置项的地址并映射到存储模块的物理地址,生成存储模块的控制信号,进行源数据的读写。
算法控制模块,负责控制计算流程,在接收到系统启动信号后控制门向量计算模块和细胞状态计算模块的交替运行。
门向量计算模块,负责接收源数据并在控制模块控制下将源数据传入类脉动阵列,依次计算各门向量ft,it,zt,ot并存入存储模块;其中,阵列计算完ft后本模块产生一个结束信号,算法控制模块接收到该信号后拉低计算ft的使能信号并拉高it的使能信号,以此类推,直到完成所有门向量运算,算法控制模块产生一个细胞状态计算模块的启动信号。
细胞状态计算模块,接收到启动信号后开始从存储模块中读出门向量数据,对数据进行重组,使其以乘累加的形式传入阵列,计算神经元状态值ct和隐藏层输出值ht,存入存储模块,并生成一个结束信号,算法控制模块接收到该信号后再次启动门向量计算模块,重复上述过程。
存储模块,接收和输出存储门向量计算模块与细胞状态计算模块的计算结果。
如图2,存储资源共有128个数据存储器bank和32个系数存储器factorbank。源数据的存放方式为:输入层的输入数据存入bank0-31低位地址空间,每个bank存放一个批次的输入数据;神经元权重存入bank32-95,其中:bank32-63低位地址空间存放遗忘门权重矩阵wf,高位地址空间存放候选门权重矩阵wz,bank64-95低位地址空间存放输入门权重矩阵wi,高位地址空间存放输出门权重矩阵wo,所有权重按神经元进行存放,同一个神经元的权重存放在同一个bank中;偏置项存入bank96-103;计算得到的门向量数据:遗忘门计算结果ft存放在bank112-119,输入门计算结果it存放在bank120-127低位地址空间,候选门计算结果zt存放在bank104-111,输出门计算结果ot存放在bank120-127高位地址空间;其中同一批次的计算结果以地址递增的方式存入各自的存储模块,一个存储模块存放四个批次的数据;细胞状态值ct按t的奇偶性存入常数存储器factor_bank16-31,t为奇数时存入factor_bank24-31,t为偶数时存入factor_bank16-23,同一批次的计算结果以地址递增的方式存入各自的存储模块,一个存储模块存放四个批次的数据;隐藏层输出值ht存入bank0-31高位地址空间,每个bank存放一个批次的ht,每个时间序列里输出的ht不相互覆盖。
本实施例的基于脉动阵列的多隐层可复用的长短期记忆神经网络前向硬件加速架构实现了从输入层到隐藏层的前向运算,即如图3中所示的输入层1到隐藏层1的运算,若需要搭建具有更多隐藏层的网络,如双隐藏层lstm网络,则需要计算从隐藏层1到隐藏层2的前向运算。要实现这样的运算,只需要在架构的配置阶段将第一次的输出作为第二次的输入并改变相应的网络参数,即可实现本架构的复用,从而计算任意隐藏层层数的lstm前向推理运算。
本发明所述的基于脉动阵列的多隐层可复用的长短期记忆神经网络前向硬件加速架构实现一次完整的计算包括如下步骤:
步骤1)配置阶段,配置好网络各参数,包括:输入层节点数“input”、隐藏层节点数“hidden”、时间序列长度“time_step”、批处理批次“batch”等,若需要计算多隐层的网络则将包含上述参数的指令进行多次配置;
步骤2)存储地址生成处理模块将源数据存入对应的存储模块,包括:输入层输入数据input、所有神经元权重、所有偏置项,如图2所示;
步骤3)算法控制模块接收到系统的启动信号后,启动门向量计算模块,源数据传入脉动阵列,依次计算各门向量ft,it,zt,ot并存入存储模块,生成结束信号和细胞状态计算模块的启动信号;
步骤4)细胞状态计算模块接收到启动信号后开始从存储模块中读出门向量数据,计算神经元状态值ct和隐藏层输出值ht,存入存储模块,并生成一个结束信号;
步骤5)算法控制模块接收到结束信号后再次启动门向量计算模块,重复上述步骤3)和步骤4),直到完成所有时序的计算。
步骤6)在完成步骤5)的基础上,若配置阶段配置了多隐层的网络,则重复上述步骤2)、步骤3)、步骤4)、步骤5),直到完成所有层数的运算。
本发明介绍了基于脉动阵列的多隐层可复用的长短期记忆神经网络前向硬件加速架构,采用脉动阵列,提高了计算效率;支持网络节点数和时间序列长度可配,配置灵活;实现了输入-隐藏层的可复用,架构可扩展性较好。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或变换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!