一种钢包分级管理分析方法及系统与流程
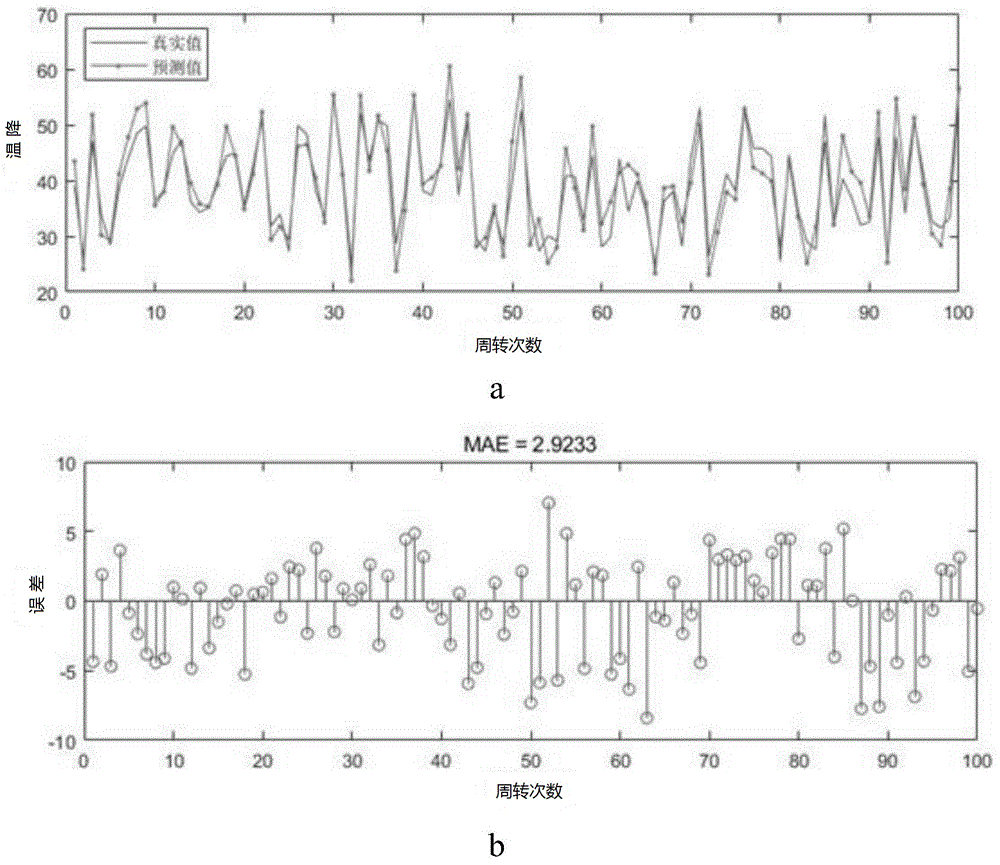
本发明属于炼钢厂的钢包检测
技术领域:
,尤其涉及一种钢包分级管理分析方法及系统。
背景技术:
:目前,最接近的现有技术:目前,对于转炉出钢温度的设定,除了钢种液相线温度和运输过程温降补偿外,重要的一项就是针对钢包的钢水温度补偿。大部分炼钢厂对钢包热状态的管理停留在考察钢包包龄、简单的红外测温或凭借经验看包等手段,仅仅根据空包时间等因素进行经验优化操作,将钢包包况分为a、b、c、d等级别,这些对钢包简单判断的方式,不但由于人为因素的加入而导致准确性难以保证,而且对不同钢包缺乏精细化的区分和区别,存在较大随机性和偶然性,不利于钢包管理和合理的出钢温度补偿。同时,目前炼钢生产中,由于无法精准的了解待用钢包的热状态,以及相应的合理的钢水温度补偿,使得转炉出钢温度不得不按温度制度上限操作以满足钢包导致钢水温降的要求,保证中间包钢水温度,导致转炉出钢温度补偿值过高,这种操作模式不但造成转炉工序能源上的浪费,而且会造成钢水温度控制的波动,不利于生产顺行和产品质量的提高,根本原因是现场无法掌握钢包热状态对钢水温降的影响规律。现场温度实测可以定性分析钢包与钢水温度的关系,但由于无法剥离其他非钢包因素的影响,同时由于影响因素复杂多样,无法获得精确的规律。使用在包衬内埋设热电偶的方法,可以确定包衬的传热规律,但是由于现场条件的限制,包衬温度实测只能进行少数特定条件下的钢包传热分析,钢包内温度较高,电子元件使用寿命较短,无法实现包衬内部实时接触式测温。单纯利用数值模拟研究钢包传热,由于部分边界条件如热流密度难以精确确定,物性参数和假设太多,模型的准确性受到影响。钢包当前热状态(主要影响因素包括烘烤时间、待用时间和钢包包龄等)不是独立的,还与之前循环热状态相关数据有关。循环神经网络(rnn)作为深度学习模型之一,它是通过隐层的自连接,实现对时间的显性建模,同时对于隐层节点进行改进实现长时间信息的记录,在自然语言处理和音频分析问题上都取得的优异的效果。不同于前馈神经网络,循环神经网络的优势在于能够利用历史信息来辅助当前的决策。它的主要思想是通过使用带自反馈的神经元对前面的信息进行记忆并应用于当前输出的计算中,隐藏层的输入不仅包括当前时刻输入层的输入还包括上一时刻隐藏层的输出,即一个序列当前时刻的输出与前面时刻的输出有关。传统rnn利用隐藏层作为记忆单元实现对历史信息的使用,源源不断的新的输入数据会“冲淡”有用的历史信息对输出结果的影响,层数过多时则容易出现梯度“消失”的问题。针对传统rnn的不足,提出的解决方案中,其中应用最广泛的就是长短时记忆网络(lstm)。lstm神经网络通过设计新的记忆单元并加入调节门来控制信息在序列中的传递,实现对历史数据有区别的遗忘和记忆以及对当前输入数据不同程度的利用。综上所述,现有技术存在的问题是:现有技术中,大部分炼钢厂对钢包热状态的管理仅仅根据空包时间等因素进行经验优化操作,由于人为因素的加入而导致准确性难以保证,而且对不同钢包缺乏精细化的区分和区别,存在较大随机性和偶然性,不利于钢包管理和合理的出钢温度补偿。同时,现有技术易造成转炉工序能源上的浪费,而且会造成钢水温度控制的波动,不利于生产顺行和产品质量的提高。并且,现有技术现场温度实测中无法剥离其他非钢包因素的影响,无法获得精确的规律。再者,现有技术使用在包衬内埋设热电偶的方法中,由于现场条件的限制,包衬温度实测只能进行少数特定条件下的钢包传热分析,钢包内温度较高,电子元件使用寿命较短,无法长时间现场使用。单纯利用数值模拟研究钢包传热,由于部分边界条件如热流密度难以精确确定,物性参数和假设太多,模型的准确性受到影响。解决上述技术问题的难度:由于钢包内部温度较高,生产场地布局复杂,上述研究方法均无法实现包衬内部实时接触式测温,难以准确分析钢包热状态与钢水温降的关系。解决上述技术问题的意义:意义就是为钢铁厂操作人员提供一种简单易行,准确可靠的对待用钢包热状态的判定方法,用来确定合理的转炉出钢温度,指导生产,降低能源消耗。技术实现要素:针对现有技术存在的问题,本发明提供了一种种钢包分级管理分析方法及系统。本发明的目的在于突破原有对钢包分级管理的不足,提供一种基于lstm神经网络来快速分析钢包热状态对钢水温降影响,从而制定钢包分级管理的方法,通过建立lstm神经网络,输入训练样本,让网络自学习出一个能有效预测钢包热状态对钢水温降影响的网络模型。本发明是这样实现的,一种钢包分级管理分析方法,步骤包括:步骤1、获取炼钢-连铸流程中相关的历史数据;步骤2、历史炼钢数据的预处理;步骤3、剥离其他非钢包影响的因素;步骤4、构造lstm神经网络;步骤5、将处理完成的数据集按照比例分为训练数据和测试数据;步骤6、使用训练数据集训练lstm神经网络;步骤7、使用训练完成的lstm神经网络预测钢水温降;步骤8、根据钢水温降将钢包分级。进一步,步骤1中,炼钢历史数据包括钢水流程数据:日期,炉号,钢种,出钢量,出钢温度,出钢开始时间点,出钢结束时间点,合金添加,到氩站时间点,离开氩站时间点,氩前温度,氩后温度,lf进站时间点,lf进站温度,lf出站时间点,lf出站温度,rh到站时间点,rh到站温度,rh开始时间点,rh开始温度,rh结束时间点,rh结束温度,rh离站时间点,rh离站温度,上平台时间点,平台温度,开浇时间点,停浇时间点。以及钢包相关数据:包号,包龄,滑板次数,上水口次数,透气砖次数,烘烤时长,烘烤强度(烘烤火焰长度)。进一步,所述步骤2包含:步骤2.1、将数据进行清洗,缺失的数据和明显错误的数据按经验和规律进行补充或修正。进一步,所述步骤3包含:步骤3.1、非钢包影响因素主要包括:1出钢量2出钢温度3出钢时长4合金影响5吹氩影响6测温时间点的选取将钢包每次循环每炉钢的出钢量、出钢时长、出钢温度统一,制定基准出钢量、出钢时长、出钢温度(根据已有数据剔除偏差数据后再取平均值得到),选定测温时间点(保证添加合金全部融化)步骤3.2、根据基准量计算修正后的数值,出钢过程影响计算:出钢时长影响=(实际出钢时长-基准出钢时长)×出钢时长影响系数;出钢温度影响=(实际出钢温度-基准出钢温度)×出钢温度影响系数;出钢量影响=(实际出钢量-基准出钢量)×出钢量影响系数;合金影响=不同合金加入1kg/t的热效应×合金重量/出钢量;吹氩影响:氩气带走的热量对钢水温度几乎没有影响,主要热损失是吹氩造成钢水表面裸露散热。基准值条件下,钢包影响温降=(出钢温度-测温点温度)-出钢过程影响-合金的影响-吹氩影响。进一步,所述步骤4构造lstm神经网络包括:一个输入层、一个lstm记忆单元层、一个输出层;所述lstm细胞层的内部设置有若干门限,包含遗忘门ft、输入门it、输出门ot;并且lstm循环神经网络的前向传播函数为:it=σ(wiixt+whiht-1+bi)ft=σ(wifxt+whfht-1+bf)ct=it☉tanh(wicxt+whcht-1+bc)+ft☉ct-1ot=σ(wioxt+whoht-1+bo)ht=ot☉tanh(ct)其中,wii为输入层到输入门之间的权重;whi为上一时刻隐藏层与输入门之间的权重;wif为输入层到遗忘门之间的权重;whf为上一时刻隐藏层与遗忘门之间的权重;wic为输入层到记忆单元之间的权重;whc为上一时刻隐藏层与记忆单元之间的权重;wio为输入层到输出门之间的权重;who为上一时刻隐藏层与输出门之间的权重;σ表示sigmoid函数;xt表示输入;ht-1表示上一时刻隐藏层的输出;bi表示输入门偏置;bf表示遗忘门偏置;ct表示状态细胞输出;bc表示记忆单元偏置;bo表示输出门偏置;ht表示隐藏层的输出。进一步,所述步骤5包含:步骤5.1、按比列把样本集分为训练样本集和测试样本集;步骤5.2、采用min-max标准化法对数据进行归一化处理,即xnorm=(x-xmin)/(xmax-xmin),将所有数据归一化到0~1之间;xnorm为数据标准化后对应的值;xmax为数据集中的最大值;xmin为数据集中的最小值。进一步,所述门限数值0表示禁止所有信息通过,数值1表示允许所有信息通过。进一步,参数的选择包括学习速率、训练次数、神经元个数;其中,学习速率选择为0~1之间;训练次数选择为任意正整数;神经元个数选择为任意正整数。目前尚未统一可遵循的方法。在此,采用试凑法结合多次试验结果,探寻效果最好、最合适的参数。进一步,模型中使用平均绝对误差(mae)损失函数来更新模型参数,表示式如下所示其中,n表示预测数据点个数;d表示训练数据真实值;y表示训练数据预测值。进一步,采用adam梯度下降算法更新lstm模型中的权重和偏置。进一步,所述神经网络输入层的输入数据为归一化之后的包龄,滑板次数,透气砖次数,烘烤时长,烘烤强度(烘烤火焰长度),空包时长,受热情况(钢包上炉循环的出钢温度及出钢开始至停浇时长),神经网络输出层的输出数据为归一化之后的基准值条件下钢包影响钢水温降值本发明的另一目的在于提供一种钢包分级管理系统。本发明的另一目的在于提供一种实现所述钢包分级管理分析方法的信息数据处理终端。本发明的另一目的在于提供一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行所述的钢包分级管理分析方法。综上所述,本发明的优点及积极效果为:lstm通过设计新的记忆单元并加入调节门来控制信息在序列中的传递。在lstm神经元模型中,输入门用于决定有多少信息可以被加入神经节点中,输出门决定模型处理后的信息将有多少可以作为输出,遗忘门将用于决定上一时刻的输出将有多少会保留用于下一时刻的计算。通过其独特的节点结构,在序列数据建模上,lstm能比传统的循环神经网络捕获到中长期的数据,而不会发生时间尺度上的梯度消失问题。本发明可以实现对待用钢包热状态的及时准确的判定,实现对钢水温度补偿的精细化管理,制定合理的转炉出钢温度,从而降低转炉工序能耗,对于节约耐材,提高钢水温度控制水平都有积极意义。附图说明图1是本发明实施例提供的钢包分级管理分析方法流程图。图2是本发明实施例提供的lstm神经网络模型图。图3是本发明实施例提供的5#钢包某次测试结果图。图中:a、周转次数与温降关系图;b、周转次数与误差关系图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。现有技术中,大部分炼钢厂对钢包热状态的管理仅仅根据空包时间等因素进行经验优化操作,由于人为因素的加入而导致准确性难以保证,而且对不同钢包缺乏精细化的区分和区别,存在较大随机性和偶然性,不利于钢包管理和合理的出钢温度补偿。同时,现有技术易造成转炉工序能源上的浪费,而且会造成钢水温度控制的波动,不利于生产顺行和产品质量的提高。并且,现有技术现场温度实测中无法剥离其他非钢包因素的影响,无法获得精确的规律。再者,现有技术使用在包衬内埋设热电偶的方法中,由于现场条件的限制,包衬温度实测只能进行少数特定条件下的钢包传热分析,钢包内温度较高,电子元件使用寿命较短,无法实现包衬内部实时接触式测温。单纯利用数值模拟研究钢包传热,由于部分边界条件如热流密度难以精确确定,物性参数和假设太多,模型的准确性受到影响。针对现有技术存在的问题,本发明提供了一种钢包分级管理分析方法及系统,下面结合附图对本发明作详细的描述。如图1所示,本发明实施例提供的钢包分级管理分析方法,包括以下步骤:s101、获取炼钢-连铸流程中相关的历史数据。s102,将数据清洗,修正,得到18个钢包共计14467炉冶炼数据,保证了lstm网络所需数据量。s103,剥离其他非钢包影响的因素,得到钢包本身数据及对应温降的样本集。s104,构建lstm神经网络,网络模型主要包括:一个输入层、一个lstm单元层、一个输出层。s105,按比例把样本集分为训练样本集和测试样本集。s106,采用min-max标准化法对数据进行归一化处理。s107中,参选数择时将学习速率选择为0.01,训练次数选择为500,神经元个数选择为100;并且采用adam梯度下降算法更新lstm模型中的权重和偏置。s108,使用训练数据集训练lstm神经网络,并将训练好的模型进行保存。s109,使用保存好的模型,对测试数据集进行预测。将模型预测结果进行反归一化得到预测值。s110,根据反归一化之后的钢水温降将钢包分级。步骤s101中,获取了某钢厂2018年5月-12月炼钢-连铸流程中相关的历史数据,数据包括钢水流程数据:日期,炉号,钢种,出钢量,出钢温度,出钢开始时间点,出钢结束时间点,合金添加,到氩站时间点,离开氩站时间点,氩前温度,氩后温度,lf进站时间点,lf进站温度,lf出站时间点,lf出站温度,rh到站时间点,rh到站温度,rh开始时间点,rh开始温度,rh结束时间点,rh结束温度,rh离站时间点,rh离站温度,上平台时间点,平台温度,开浇时间点,停浇时间点。以及钢包相关数据:包号,包龄,滑板次数,上水口次数,透气砖次数(南),透气砖次数(北),烘烤时长,烘烤强度(烘烤火焰长度)。步骤s103中,基准出钢时间:5分30秒基准出钢温度:1620度基准出钢量:155吨(根据已有数据剔除偏差数据后再取平均值得到),测温时间点(为保证添加合金全部融化,出钢开始后15min)出钢时长影响系数:3度/分,出钢温度影响系数:0.3度/度,出钢量影响系数-0.2:度/吨。出钢时长影响=(实际出钢时长-基准出钢时长)×出钢时长影响系数。出钢温度影响=(实际出钢温度-基准出钢温度)×出钢温度影响系数。出钢量影响=(实际出钢量-基准出钢量)×出钢量影响系数。合金影响=不同合金加入1kg/t的热效应×合金重量/出钢量。吹氩影响:氩气带走的热量对钢水温度几乎没有影响,主要热损失是吹氩造成钢水表面裸露散热。估算为0.1度/分。(从出钢开始吹氩,统一吹氩10分钟)。基准值条件下,钢包影响温降=(出钢温度-测温点温度)-出钢过程影响-合金的影响-吹氩影响。步骤s104中,所述lstm层的内部设置有三个门限,包含遗忘门ft、输入门it、输出门ot;这三个门限描述了每个信息通过各个门限的程度,0表示禁止所有信息通过,1表示允许所有信息通过;并且lstm递归循环神经网络的前向传播函数由这三个门限组成。it=σ(wiixt+whiht-1+bi)ft=σ(wifxt+whfht-1+bf)ct=it☉tanh(wicxt+whcht-1+bc)+ft☉ct-1ot=σ(wioxt+whoht-1+bo)ht=ot☉tanh(ct)其中,wii为输入层到输入门之间的权重;whi为上一时刻隐藏层与输入门之间的权重;wif为输入层到遗忘门之间的权重;whf为上一时刻隐藏层与遗忘门之间的权重;wic为输入层到记忆单元之间的权重;whc为上一时刻隐藏层与记忆单元之间的权重;wio为输入层到输出门之间的权重;who为上一时刻隐藏层与输出门之间的权重;σ表示sigmoid函数;xt表示输入;ht-1表示上一时刻隐藏层的输出;bi表示输入门偏置;bf表示遗忘门偏置;ct表示状态细胞输出;bc表示记忆单元偏置;bo表示输出门偏置;ht表示隐藏层的输出。步骤s105中,新钢包上线第一次使用至下线大修为一次寿命周期,同一钢包内的周期划分(如第1次,第2次,第3次寿命周期训练,第4次寿命周期测试)。步骤s106中,采用min-max标准化法对数据进行归一化处理,即xnorm=(x-xmin)/(xmax-xmin),将所有数据归一化到0~1之间。xnorm为数据标准化后对应的值;xmax为数据集中的最大值;xmin为数据集中的最小值。步骤s107中,模型中使用平均绝对误差(mae)损失函数来更新模型参数,表示式如下所示其中,n表示预测数据点个数;d表示训练数据真实值;y表示训练数据预测值。神经网络输入层的输入数据为归一化之后的包龄,滑板次数,透气砖次数,烘烤时长,烘烤强度(烘烤火焰长度),空包时长,受热情况(钢包上炉循环的出钢温度及出钢开始至停浇时长),神经网络输出层的输出数据为归一化之后的基准值条件下钢包影响钢水温降值。步骤s110中,根据反归一化之后的钢水温降将钢包分级。a级钢包:钢水温降<t。b级钢包:t≤钢水温降<t+x1。c级钢包:t+x1≤钢水温降<t+x2。d级钢包:钢水温降≥t+x2。如图2,lstm神经元模型中,xt为t时刻的输入数据,ht为t时刻隐藏层的输出,ct为t时刻记忆单元的状态。计算输入门的值it,其中,wii为输入层到输入门之间的连接权值矩阵,whi为隐藏层到输入门之间的连接权值矩阵,bi为相应的偏置向量。it=σ(wiixt+whiht-1+bi);计算遗忘门的值ft,ft=σ(wifxt+whfht-1+bf),遗忘门以一定的概率来控制遗忘上一层的记忆单元状态,通常采用激活函数来对遗忘门输出值进行控制,使其输出值在0到1之间,0表示完全舍弃,1表示全部保留。计算记忆单元的状态值ct,☉代表两个矩阵或向量进行哈达玛乘积计算。ct=it☉tanh(wicxt+whcht-1+bc)+ft☉ct-1。计算输出门的值ot,ot=σ(wioxt+whoht-1+bo);计算隐藏层的输出ht=ot☉tanh(ct);上式中σ()表示sigmoid激活函数。所收集整理数据中,5#钢包部分样本点如下表所示:样本点温降真实值温降预测值误差139.1143.46-4.35225.9524.041.91347.1051.79-4.69433.8030.173.63528.4429.31-0.87638.8341.19-2.36743.9547.77-3.82849.9046.113.79941.9741.050.921027.3429.73-2.395#钢包某次测试结果如下图。图中:a、周转次数与温降关系图;b、周转次数与误差关系图。其中平均绝对值误差mae=2.92。预测结果良好。在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用全部或部分地以计算机程序产品的形式实现,所述计算机程序产品包括一个或多个计算机指令。在计算机上加载或执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(dsl)或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输)。所述计算机可读取存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,dvd)、或者半导体介质(例如固态硬盘solidstatedisk(ssd))等。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1