一种基于深度学习算法自动实现字段权重分配的科技项目查重方法与流程
本发明属于数据检索比对
技术领域:
,具体涉及一种基于深度学习算法自动实现字段权重分配的科技项目查重方法。
背景技术:
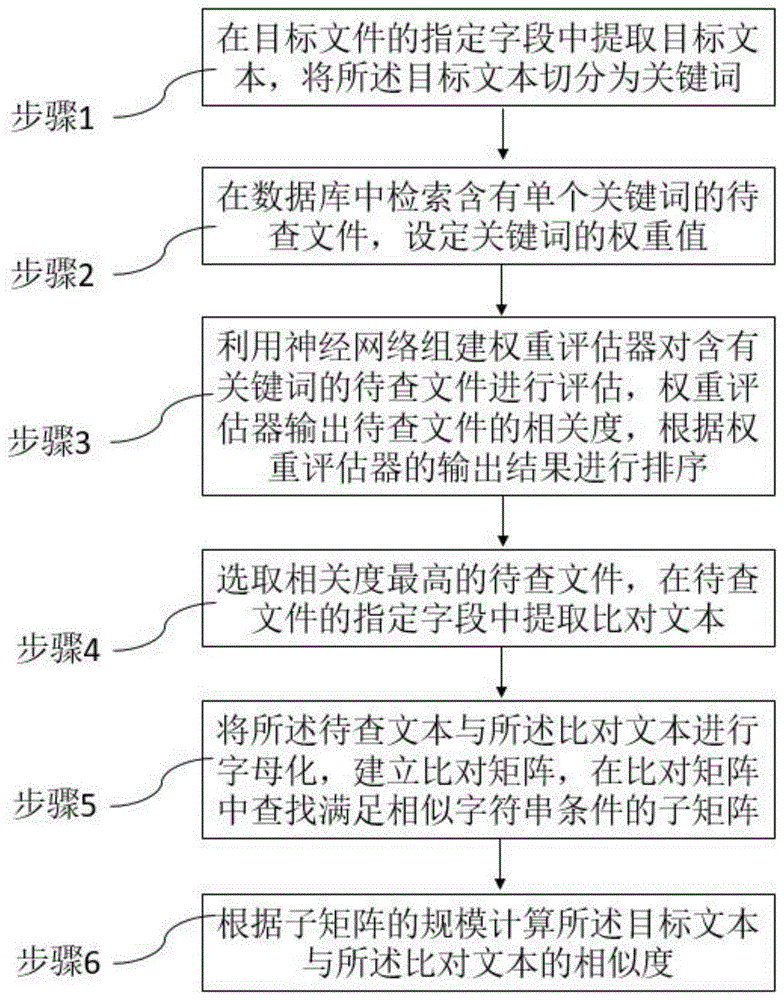
:目前,论文/项目的重复率检测主要是采用paperpass、万方、知网等检测系统,通过字符串匹配算法来计算待检测的文件相对于文件库中的目标文件的相似比。字符串匹配算法是以一段文字完全一致作为衡量论文重复的标准,然而,由于中文语言的复杂性和表达方式的多样性,对于实质内容相同的两段文字,往往会因为中间出现一些无意义的“停词”或虚词或者主谓宾顺序不一致等情况,而将其错误地判断为不属于重复内容,因此,采用现有技术中的字符串匹配算法可能会导致查全率和查准率不高。而且,字符串匹配算法对字符串的选取要求严格,算法本身复杂度较高,需要相对大的资源开销和较长的计算时间,因此,查重的效率也不高。此外,近年来,随着科技项目申报、学术论文和学位论文等的数量大幅增长,迫切需要支持大数据量下,查重结果准确、高效的文本数据查重的方法。中国发明专利cn106909609a;中国发明专利cn101609466a;中国发明专利cn105718506a。技术实现要素:本发明的目的在于提供一种基于深度学习算法自动实现字段权重分配的科技项目查重方法,旨在解决现有技术查重的效率低的问题。为实现上述技术目的,达到上述技术效果,本发明通过以下技术方案实现:本发明提供了一种基于深度学习算法自动实现字段权重分配的科技项目查重方法,包括如下步骤:步骤1:在目标文件的指定字段中提取目标文本,将所述目标文本切分为关键词;步骤2:在数据库中检索含有单个关键词的待查文件,设定关键词的权重值;步骤3:利用神经网络组建权重评估器对含有关键词的待查文件进行评估,权重评估器输出待查文件的相关度,根据权重评估器的输出结果进行排序;步骤4:选取相关度最高的待查文件,在待查文件的指定字段中提取比对文本;步骤5:将所述待查文本与所述比对文本进行字母化,建立比对矩阵,在比对矩阵中查找满足相似字符串条件的子矩阵;步骤6:根据子矩阵的规模计算所述目标文本与所述比对文本的相似度。优选地,步骤3中利用神经网络组建权重评估器的步骤包括:获取关键词的权重值,选取六篇待查文件作为训练样本,其中三篇待查文件与目标文件相关,其他三篇待查文件与目标文件不相关;获取六篇待查文件含有的关键词,根据相关性输入神经网络进行训练;待训练完成后,神经网络组建的权重评估器可以根据关键词及权重值输出该待查文件的相关度。优选地,所述的指定字段还包括标题。优选地,所述的指定字段还包括负责人。优选地,所述的指定字段还包括承担机构与合作机构。优选地,所述的指定字段还包括摘要。优选地,所述的指定字段还包括正文。优选地,步骤1中将所述目标文本按照动词、名词、形容词、副词、介词切分为关键词。本发明的优点:本发明提供的基于深度学习算法自动实现字段权重分配的科技项目查重方法,利用神经网络对相关样本进行学习训练,训练完成后能够高效、快速地完成文件相似性比对(查重)的任务。附图说明图1为本发明所述的基于深度学习算法自动实现字段权重分配的科技项目查重方法的流程框图。具体实施方式为了使本发明的目的,技术方案及优点更加清楚明白,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。本发明提供了一种基于深度学习算法自动实现字段权重分配的科技项目查重方法,包括如下步骤:步骤1:在目标文件的指定字段中提取目标文本,将所述目标文本切分为关键词;例如,选取目标文件,指定字段设置为“技术内容”,在目标文件的“技术内容”字段中提取了“应用游戏引擎udk技术将提取的特色元素虚拟化、数字化,利用三维建模blender技术将虚拟化信息应用于移动游戏端”的目标文本,将所述目标文本切分为“应用/游戏/引擎/udk/技术/将/提取/的/特色/元素/虚拟化/数字化/利用/三维/建模/blender/技术/将/虚拟化/信息/应用于/移动/游戏端/”多个关键词;在一个实施例中,所述的指定字段还可以包括“标题”、“负责人”、“承担机构”、“合作机构”、“摘要”以及“正文”;在一个实施例中,将所述目标文本切分为关键词时,可以按照动词、名词、形容词、副词、介词切分为关键词,省略其他类型的关键词;步骤2:在数据库中检索含有单个关键词的项目文件,设定关键词的权重值;例如,在12564个项目文件的数据库中检索后,含“应用”关键词的项目文件9472个,含“游戏”关键词的项目文件2761个,含“引擎”关键词的项目文件958个,含“udk”关键词的项目文件8个,对项目文件个数进行归一化处理y=x-8/(9472-8),结果得出:“应用”为“1”,“游戏”为“0.29089”,“引擎”为“0.10038”,“udk”为“0.00085”;步骤3:利用神经网络组建权重评估器对含有关键词的待查文件进行评估,权重评估器输出待查文件的相关度,根据权重评估器的输出结果进行排序;如:权重评估器的输出结果为:待查文件1的相关度为0.913,待查文件2的相关度为0.762,待查文件3的相关度为0.913,待查文件4的相关度为0.206,待查文件5的相关度为0.050,待查文件6的相关度为0;因此,排序为待查文件1>待查文件3>待查文件2>待查文件4>待查文件5>待查文件6。在一个实施例中,利用神经网络组建权重评估器的步骤如下:获取关键词的权重值,选取六篇待查文件作为训练样本,其中三篇待查文件与目标文件相关,其他三篇待查文件与目标文件不相关,将相关的待查文件赋值为1,不相关的待查文件赋值为0;获取六篇待查文件含有的关键词,根据相关性输入神经网络进行训练,如表1所示;表1神经网络样本训练表目标文件待查文件1待查文件2待查文件3待查文件4待查文件5待查文件6关键词1应用无无无应用应用无权重值1000110关键词2游戏游戏游戏无游戏无无权重值0.290890.290890.2908900.2908900关键词3引擎引擎引擎引擎无无无权重值0.100380.100380.100380.10038000关键词4udkudk无udk无无无权重值0.000850.0008500.00085000相关性-相关相关相关不相关不相关不相关赋值-111000从表1可以获得神经网络的训练集,输入为关键词权重值p=[0,0.29089,0.10038,0.00085;0,0.29089,0.10038,0;0,0,0.10038,0.00085;1,0.29089,0,0;0,0,0,0],输出为相关性s0=[1,1,1,0,0,0];将以上样本集代入式(1)的径向基神经网络进行拟合训练,拟合训练可获得具有关键词特性的权重评估器,如式(1)所示;式(1)中,||p-ci||为输入量p与神经网络权量ci的欧式距离,wi为神经网络隐层到输出层之间的权量,wi=[w1w2w3w4w5w6]t=[0.0500.3150.4650.5850.8350.975],ci=[c1c2c3c4c5c6]t=[0.30500.45280.62380.80290.9763]。待训练完成后,神经网络组建的权重评估器可以根据关键词的权重值p输出该待查文件的相关度s0的值,如表2所示;表2待查文件的相关度项目文件待查文件1待查文件3待查文件2待查文件4待查文件5待查文件6相关度s00.9130.8050.7620.2060.0500根据s0进行待查文件的相关度排序,如表2所示。步骤4:选取相关度最高的待查文件,在待查文件的指定字段中提取比对文本;如:选取待查文件1,提取比对文本如下:“利用udk虚幻引擎画刷制作游戏四面墙,然后利用udk虚幻引擎进行初始游戏的基础添加,通过四面墙的添加以及贴图的附加,场景的初步搭建。在其中添加一些隔断墙,并适当的添加一些灯光,给其符合场景的颜色,给一些比较暗的地方添加sportlight,场景中只有墙体闭塞,可以适当的创建天窗,并附上材质”;步骤5:将所述目标文本与所述比对文本进行字母化,建立比对矩阵,在比对矩阵中查找满足相似字符串条件的子矩阵;(请参考现有技术cn106909609a,在此不再赘述)步骤6:根据子矩阵的规模计算所述目标文本与所述比对文本的相似度,计算比对文本的相似度的公式如下:其中,bfb表示章节相似比,txtlen表示比对文本长度,n是比对文本中关键字的个数,keylen表示关键字的长度(即查找出的相似片度的长度)。由此描述了本发明的至少一个实施例的几个方面,可以理解,对本领域技术人员来说容易地进行各种改变、修改和改进。这种改变、修改和改进意于在本发明的精神和范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1