一种新的动态反馈和改进型补丁评价的软件自动修复方法与流程
本发明属于软件工程的自动化软件修复领域,具体涉及运用云模型的对候选补丁建模,运用模型参数增强适应度评价函数对所生成补丁的表达能力,影响遗传算法对候选补丁筛选时的结果,指导下一代补丁生成。并运用动态反馈调整策略,根据父代与子代的所有补丁的适应度差异,调整云模型中的超熵与遗传算法中的变异率,从而提高软件缺陷修复成功率的修复方法。
背景技术:
软件缺陷修复是软件开发过程中最为耗时和繁琐的步骤。软件缺陷修复是一个不断重复修改,验证两个步骤的迭代过程,代码的修改可能引发新缺陷的产生。近些年研究者在软件自动化修复领域开展大量研究工作,希望在减少人工干预的前提下,通过高效的算法实现对缺陷代码的自动识别,针对缺陷程序生成相对应的补丁,从而实现软件缺陷的自动修复。
软件缺陷修复通常分为两个步骤:补丁生成和验证。首先使用缺陷定位技术,定位可能包含程序错误的潜在可疑语句,并对这些可疑语句进行排序;然后按照排序结果对可疑语句进行加工,例如通过语句删除,添加和替换等预先定义的操作来自动生成补丁;最后通过运行测试用例来检验每个生成的补丁,如果测试用例能全部通过,则表明修复成功,该补丁为有效补丁,否则如果运行测试用例过程超时或达到最大迭代次数,则代表修复失败。
云模型是处理定性概念与定量描述的不确定转换模型。其输入为表示定性概念的期望值ex、熵en和超熵he。期望是在数域空间中最能够代表这个定性概念的点,反映云的重心位置。熵作为统计热力学的概念,度量物理系统的无组织度。在云模型中,熵被用来衡量定性概念的模糊度与概率,揭示模糊性与随机性的关联性。熵一方面反映了在数域空间中可被语言值接受的范围,即模糊度,另一方面还反映了数域空间能够代表这个语言值的概率,表示云滴出现的随机性。超熵是熵的不确定性的度量,即熵的熵,反映了在数域空间代表该语言值的所有点的不确定度的凝聚性,即云滴的凝聚度。
技术实现要素:
本发明的目的在于克服现有适应度评价函数区分能力较弱,以及无法调整补丁质量的问题,提出一种新的动态反馈和改进型补丁评价的软件自动修复方法。
首先,本发明引入云模型增强对补丁的分析,提出使用云模型对生成的候选补丁建模,从而实现对常规补丁样本进行量化分析,将种群整体角度参数引进到适应度评价中,增强种群补丁的适应度评价函数,实现现有方法对相似适应度评的补丁做更为精细的评价。
其次,通过比较当前候选补丁集与上代在适应度上的变化,构建反馈链,调整云模型的超熵与遗传算法的变异率。通过调整云模型超熵,进而调整相似补丁适应度差异;通过调整遗传算法的变异率,调整生成补丁的多样性。根据反馈信息,设计了两种反馈策略:随机游走和一维更新。随机游走策略增大超熵与变异率,提高所产生补丁的多样性;一维更新策略减小超熵与变异率,减小所产生补丁的多样性,使进化趋势保持稳定,在当前探索方向下深入探索。发明规定,在当前补丁集较上一代补丁集在适应度上有提升时,维持当前已经采用的策略,反之,当前补丁集较上一代补丁集在适应度上有下降时,更换使用另一种策略。以上反馈策略是根据补丁集整体适应度做出的反应,适应度的提升表明当前策略下,得到的补丁质量有所提高,因此继续保持;适应度的下降表明,当前策略不适合该缺陷程序的探索模式,因此需要改变。本发明相对于现有技术具有的效果:
首先,现有技术着重通过不同操作,生成具有多样性的补丁,对变体属性的反馈信息的重视不足,过于朴素的评价函数在适应度评价结果上的区分能力较弱,本发明利用属性反馈,在补丁评价阶段引入云模型进行建模,利用云模型的确定度属性对现有方法的适应度评价函数进行增强,增大种群区分度,以分辨相似质量的补丁个体;其次,现有技术采用无反馈链干预的遗传算法在解空间探索过程中效率较低,影响修复准确性和效率,解空间探索方法朴素,探索效率不高,灵活性低。本发明增加外部反馈回路,根据改良的补丁适应度评价函数,控制补丁生成算法,调整补丁生成趋势,增加了探索的灵活性和稳定性。
附图说明
图1是本发明所述的软件自动缺陷修复方法的流程框图;
图2是本发明所提供的动态调整策略算法伪代码;
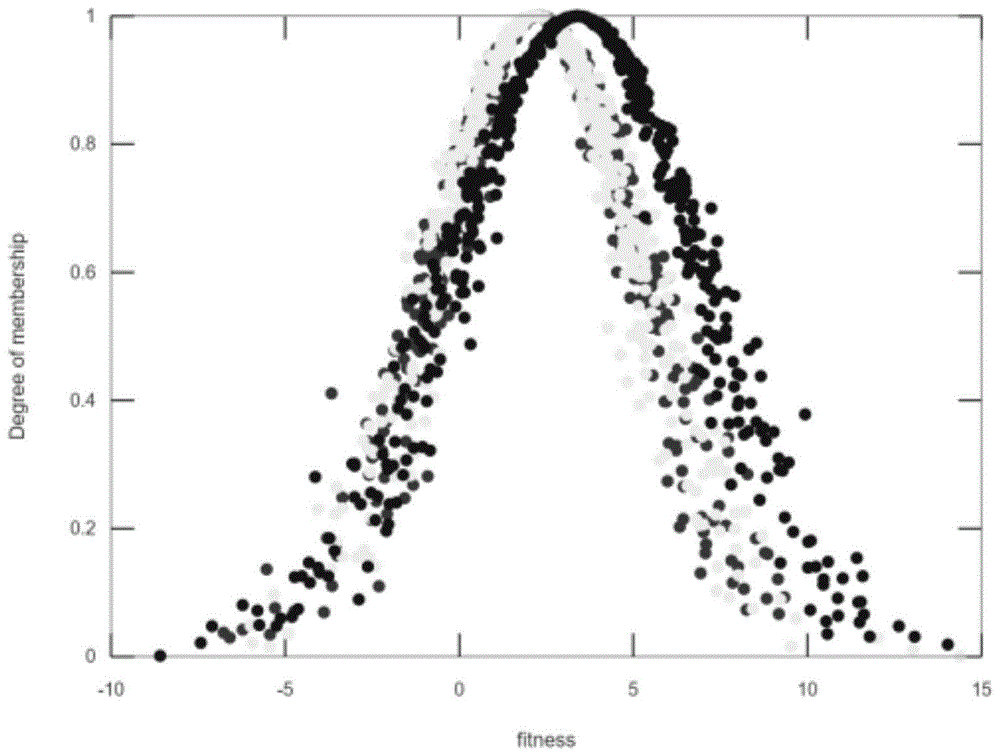
图3(a)是原始方法的种群云模型的分布图;
图3(b)是本发明实验过程中种群云模型的分布图;
图4-7是本发明方法和传统方法的实验结果对比图。
具体实施方式
如图1所示,一种新的动态反馈和改进型补丁评价的软件自动修复方法,该方法具体包括以下步骤:
步骤一:输入缺陷程序和测试用例,计算种群中所有个体适应度,将新生种群按平均适应度划分成三个子群:优秀种群,普通种群,不良种群;将缺陷程序表示为抽象语法树并将语法树中的语句对应一组实时维护的权值列表,所述的测试用例至少包含一个辨别程序缺陷的负向测试用例。
将新生种群按平均适应度划分成三个子群,具体为:根据区间理论建立一个评估规范,考虑云模型的双边约束[a,b],给出云参数方程计算方法:假设f(ti)是第t代中个体xi的适应值,则f(avg(t))表示整个群体的平均适应度,并且f(best(t))表示最佳适合度。对于比f(avg(t))更好的适应度的所有个体,获得平均值f(avg1(t))。对于比
f(avg(t))更差的适应度的所有个体,计算平均值f(avg2(t))。其中f(avg1(t))是区间的上边界,f(avg2(t))是区间的下边界。
如果f(ti)大于f(avg1(t)),则表明这些个体是优秀的,它们展现出最有希望的成果,为了最快得到最优解,应该在遗传算法中使其遗传到下一代。如果f(ti)小于f(avg2(t)),则这些个体是表现较差的个体,在遗传算法的的选择阶段优先给予删除。三个子群如下表所示:
步骤二:收集普通种群的期望,熵,以及前代反馈信息超熵,构建正态云分布模型。
设定普通个体集的期望ex和熵en如下:
ex=f(best(t))(1)
其中n表示普通个体集中个体的数量;
然后,公式(3)表示超熵he的第一代取值公式,随后he的取值会根据每代反馈情况给予变动。变动规则见图2中15-20行,具体为:
其中当前策略为随机游走策略或一维更新策略;如果当前策略计算的种群适应度总体较上代得到提高,保持现有策略,其中一维更新策略将超熵设定为0.2和0.5之间的随机值。随机游走策略将超熵设定为0.5到0.8之间的随机值,以此来变更云模型的混乱度,调整群体的差异性和稳定性。
将期望、熵、超熵作为参数生成云,正态云生成函数如公式4所示。
步骤三:对每一个普通个体集中个体计算与源程序的相似度,按照相似度从高向低赋予其云模型属性中的确定度,以此增强候选个体的适应度信息。
根据云模型概率分布,按照程序相似度顺序将适应度与调整因子进行相加,与源程序的相似度越大,表示对源程序的改动越小,那么程序语义改变的可能性就越小,在都被测试集验证通过的前提下,改动源程序幅度更小的修复方式拥有更高的修复质量。源程序相似度计算公式如(5)所示,k与k’代表源程序与普通个体集中个体程序的语句数量,其中e(i)代表普通个体集中个体程序语句中第i个元素,e’(i)代表源程序语句中第i个元素,用e(i)==e’(i)表示元素的一致性,如果相同语句则返回1,否则返回0。
对于公式(6)考虑如下:对于同一代的相似个体组成的种群,即除去最优和最差子群后的个体集组成的种群,使用云模型将这些无序同性质个体通过云分布概率模型重新调整适应值,以区分不同个体适应度。公式中n表示属于[a,b]范围的普通个体数目,由于调整后的适应度不能高于区间最大适应度,所以取最大适应度与最大区间b的差值作为调整范围,为了防止随机因素的干扰,取差值的一半,按照云概率分布图中的概念确定度更新适应度。
更新规则如公式(7)所示,其中个体角度的适应度计算部分:npost表示通过的正向测试用例个数,每个通过的正向测试用例用全局参数正向测试权重wpost更新权值,用以表明程序的功能正确性。nnegt表示通过的负向测试用例个数,每个通过的负向测试用例用更大负向测试权重wnegt更新权值,用来着重体现程序中修复的错误。最后加上整体角度根据云模型确定的调整因子,共同组成适应度计算公式。
f(t)=npost*wpost+nnegt*wnegt(7)
步骤四:合并三个子群,根据更新的适应度函数对所有补丁进行重排列,根据上代反馈信息调整遗传参数,用遗传算法对种群进行选择,交叉,变异,生成新一代种群。
遗传算法通过选择高适应度个体复制到下一代中来进行迭代,丢弃适应度为0,未编译或未通过测试用例的变体,将其余部分放在一起使用随机通用抽样选择新一代成员带入新的交配池。在遗传算法中,变异操作通常涉及单位翻转或简单的符号替换。因为基本单元是语句,所以变异运算由删除(删除整个语句),插入(在其后插入另一个语句)或与另一个语句交换组成。从这些选项中以同样的随机概率进行选择,在交换的情况下,可以从程序中的任何位置随机选择第二条语句。交叉将一个变体的“第一部分”与另一个变体的“第二部分”结合起来,创建后代变体,该后代变体结合了来自两个亲本的信息。
步骤五:收集新种群的反馈信息并与原始种群的适应度进行比较。在提高适应度的基础上,保持现有策略不变。假若种群质量下降,则更换另一种策略和参数。
将上一代的适合度与当前种群的适应度值进行遍历。在提高补丁解决方案质量的情况下,成功率增加1,用sr1和sr2分别记录随机游走和一维更新策略的成功率。如果sr1大于sr2,则表示使用随机游走的成功率高于使用一维更新规则的成功率。这时分两部分更新策略:
(1)在下一次迭代中,更多的个体应用随机游走的进化策略,增加变异率pm的值。
(2)同时更新he值。
步骤六:重复执行步骤二~步骤五,超过时限或最大遗传代数表示修复失败。否则直至找到通过所有测试用例的候选补丁,程序执行成功并报告给用户。
图3是用正态云模型建立两种方法修复过程中云模型演变过程。图3(a)是原始方法实验结果演变图,可以看出种群的适应度分布较为集中,相对于前代无明显分布规律,这种性质在多代对比时更为显著。而加了了更新适应度与反馈链的图3(b)可以看出明显的导向,并且正态云图更加规范,随着代数的增加,会偏向高适应度,种群的均值和期望表现出更有希望的成果。
图4显示了两种方法的修复成功平均时间对比情况,时间缩短在最大值在40%,并且效果会随着程序搜索空间的变大而更为明显
图5是中型测试程序的测试用例执行个数表型情况,对于中型程序效果提升最大值50%,说明无论程序大小与复杂性,现有都可以表现出积极的效果。
图6显示了两种测试用例在不同方法之下的测试用例执行个数方面的表现,可以看出新发明方法拥有更低的均值与最值,且整体数据大多稳定在原方法水平之下。
图7显示了两种方法的执行个数(ntce)详细情况。执行次数相比于原始方法降低一半以上。说明随着程序复杂性的增加以及配套测试集数目的增加,本文提出的策略是更加高效的。
- 还没有人留言评论。精彩留言会获得点赞!