一种基于深度学习的争议焦点生成方法与流程
本发明涉及一种生成方法,具体涉及一种基于深度学习的争议焦点生成方法,属于文本生成技术领域。
背景技术:
随着自然语言处理技术和人工智能的发展,自助法律服务系统也渐渐建立并完善起来。譬如,可以根据法律文书中的事实描述来预测控诉罪名,实现辅助判决。可以通过查询寻找相关的法律文书;可以为控诉罪名的预测提供合理的法律条文证明。这些工作为法律从业者提供了很大的便利。争议焦点的生成对法官和律师来说具有重要意义。
争议焦点是法官归纳并经过当事人认可的关于证据、事实和法律适用争议的关键问题,既是庭审的主要内容,也是制作裁判文书的主线,方便组织证据认定、事实认定和说理部分的论述。争议焦点生成的意义如下所示:
(1)对法官的意义
·划清审判脉络,保障庭审高效有序。
·争议焦点的总结是裁判文书的“中心思想”。
·双方围绕争议焦点所作的陈述与辩论,加上法官依法作出的裁定,就是裁判文书的雏形。
·双方围绕争议焦点作出的举证质证和发表的辩论,构成了决定案件判决结果的基础。
(2)对律师的意义
·提前帮助律师预判庭审走向,准备证据,确定法律适用。
·一定程度上引导庭审方向。
·帮助预测对方的辩论思路,提前做好准备。
法律争议焦点生成工作属于法律服务系统的一部分,随着技术的发展,法律服务系统的功能越来越多样化。早期的法律工作主要应用的是机器学习的文本分类技术。boella等人在2011年实现了根据法律文书和它的领域标签之间的关系,来确定特定法律文本的相关领域。liu和chen在2017年使用了数据挖掘的方法从先例中提取特征,然后使用文本分类器自动对判决情况分类,以实现判决预测。
技术实现要素:
本发明正是针对现有技术中存在的问题,提供一种基于深度学习的争议焦点生成方法,该技术方案对于给定原告诉称和被告辩称,能够自动生成给定的原告诉称和被告辩称的双方的争议焦点的装置,同时,本发明从网络上爬取裁判文书,并对这些裁判文书抽取出原告诉称和被告辩称,抽取出所有的原告诉称和被告辩称,并标注相应的争议焦点,构建出相应的争议焦点生成装置。
为了实现上述目的,本发明的技术方案如下,一种基于深度学习的争议焦点生成方法,所述方法包括以下步骤:
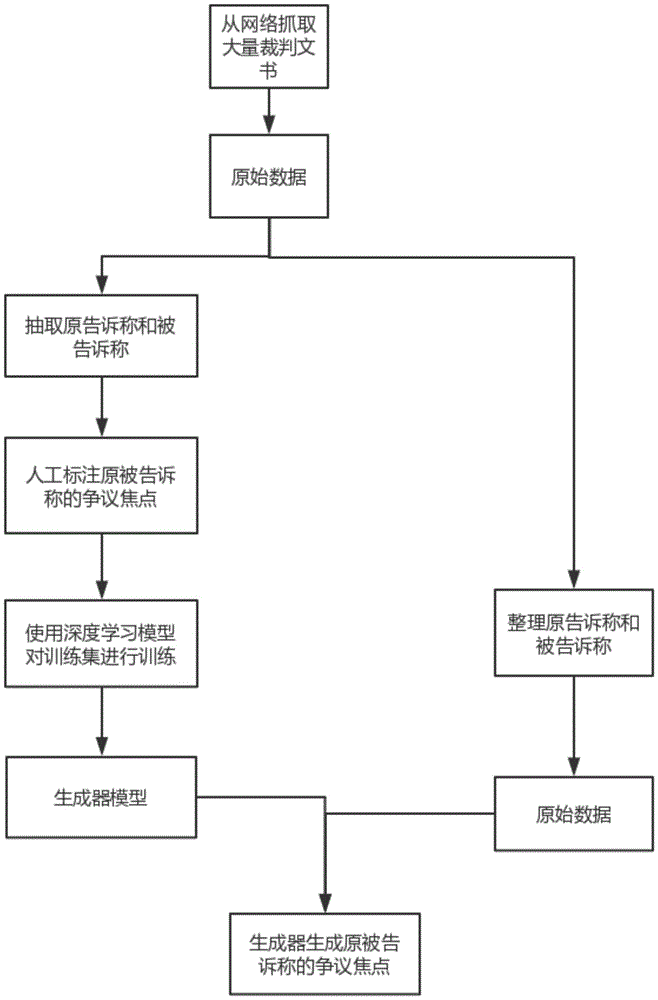
步骤1)从网络中爬取大量裁判文书;
步骤2)利用正则表达式方法对裁判文书进行初步的清洗和整理,抽取出裁判文书中的原告诉称和被告辩称,并对每一对原告诉称和被告辩称进行人工标注,将原告诉称和被告辩称以及人工标注的数据集,以1:1:1的比例构建成训练集;
步骤3)使用深度学习中的seq2seq文本生成模型和attention模型对所述步骤2)最终得到的训练数据集进行训练后,导出该训练数据集对应的生成器模型;
步骤4)对步骤3)中训练得到的文本生成器,利用训练完成的生成器从未标注的原告诉称和被告辩称中生成双方的争议焦点。
作为本发明的一种改进,所述步骤3)具体如下:
1)seq2seq的编码模型融合了上下文文本信息和文本主题信息,首先将原告诉称进行句子级的切分,对于每一个切分好的句子,进行分词,然后将句子放入gru模型,得到句子的最终表示;
hp,it=gru(xp,it,hp,it-1),t∈[1,r];
xp,it表示原告诉称的第i句第t个词的词向量,词向量通过word2vec训练得到,hp,it-1表示原告诉称第i句的t-1状态的隐状态,最终得到第r步的隐状态;
2)利用第r步的隐状态和每一步的隐状态计算attention值,并将attention计算得到的权重,乘以相应的隐状态向量,最终得到的计算向量即是句子的向量表示,计算公式如下所示:
up,it=tanh(wωhp,it+bω);
sp,i=∑tαp,ithp,it;
其中,hp,it表示gru中的原告诉称中第i个词的隐状态表示,wω和bω表示待调节的参数,最终得到sp,i,sp,i是原告诉称的第i个句子的嵌入表示,对于原告诉称,可以得到句子序列sp,1,sp,2……,sp,m。将句子序列输入到gru模型中,得到原告诉称的m个句子的总体表示;
hp,i=gru(sp,i,hp,i-1),i∈[1,m];
其中sp,i代表第i句子的原告诉称,hp,i-1代表上一步的输出的隐状态,m代表原告诉称的句子长度,最终得到最后的原告诉称表示,同理也可得到最终的被告辩称。
作为本发明的一种改进,所述步骤3)中,除了利用到了上下文的表示,对于双方表述不同,但是含义相同的情况,对于原告所述步骤3)中,除了利用到了上下文的表示,对于双方表述不同,但是含义相同的情况,对于原告诉称和被告辩称,引入了主题向量表示。对于原告诉称的主题分布为tp=(tp,1,tp,2,…,tp,m)。tp,q注意力权重可以通过以下的计算公式得到:
其中hp,m是输入文本的最后的隐状态,用于提高相关主题的权重,弱化不相干主题的权重。被告辩称也可通过相同的公式得到。本装置将原告诉称和被告辩称的attention的进行联合计算,得到统一的主题注意力权重,计算公式如下所示:
αjq=mp,jq·wq·md,jq
本方法联合上下文注意力机制和主题注意力机制联合计算得到cj。计算公式如下所示:
其中tp,j是tp主题中的一个主题的向量,td,j是td主题中的一个主题的向量。
得到原告诉称和被告辩称的融合向量以后,并以此向量作为解码器的输入,并生成争议焦点,生成的所有词的概率如下公式所示:
其中,yj-1是指上一个预测的词,
dj=gru(yj-1,dj-1,cj)
其中
其中,wt,
相对于现有技术,本发明具有如下优点,由于争议焦点生成存在两大难点:1、原被告双方描述相似但不是争议焦点。2、原被告双方描述不相似但是争议焦点。因此,单单从字面意思上得出争议焦点难以确保争议焦点的正确性和全面性。为了提高生成争议焦点的正确性和全面性,本装置从两个层面检测争议焦点,分别是字面意思层面和主题信息层面。
经过实验分析证明,利用本发明提出的争议焦点生成技术,可以实现根据原告诉称和被告辩称自动生成争议焦点任务。从字面意思和主题信息两个层面检测争议焦点能够很好的解决以往的模型无法处理原被告双方描述相似但不是争议焦点和原被告双方描述不相似但是争议焦点的两种情况。本发明中,争议焦点生成的效果在语言的自然性上,还有准确率,召回率,f1值,等指标上都充分表现了该技术的出色效果。本方法利用文本生成的技术,相比于抽取式的方法更加灵活,概括性更强,争议焦点生成的效果更好。
附图说明
图1是本发明的基本过程示意图;
图2是层次体系结构构建算法图。
具体实施方式:
为了加深对本发明的理解,下面结合附图对本实施例做详细的说明。
实施例1:参见图1,一种基于深度学习的争议焦点生成方法,所述方法包括以下步骤:
步骤1)从网络中爬取大量裁判文书;
步骤2)利用正则表达式方法对裁判文书进行初步的清洗和整理,抽取出裁判文书中的原告诉称和被告辩称,并对每一对原告诉称和被告辩称进行人工标注,将原告诉称和被告辩称以及人工标注的数据集,以1:1:1的比例构建成训练集;
步骤3)使用深度学习中的seq2seq文本生成模型和attention模型对所述步骤2)最终得到的训练数据集进行训练后,导出该训练数据集对应的生成器模型;
步骤4)对步骤3)中训练得到的文本生成器,利用训练完成的生成器从未标注的原告诉称和被告辩称中生成双方的争议焦点。
所述步骤3)具体如下:
1)seq2seq的编码模型融合了上下文文本信息和文本主题信息,首先将原告诉称进行句子级的切分,对于每一个切分好的句子,进行分词,然后将句子放入gru模型,得到句子的最终表示;
hp,it=gru(xp,it,hp,it-1),t∈[1,r];
xp,it表示原告诉称的第i句第t个词的词向量,词向量通过word2vec训练得到,hp,it-1表示原告诉称第i句的t-1状态的隐状态,最终得到第r步的隐状态;
2)利用第r步的隐状态和每一步的隐状态计算attention值,并将attention计算得到的权重,乘以相应的隐状态向量,最终得到的计算向量即是句子的向量表示,计算公式如下所示:
up,it=tanh(wωhp,it+bω);
sp,i=∑tαp,ithp,it;
其中,hp,it表示gru中的原告诉称中第i个词的隐状态表示,wω和bω表示待调节的参数,最终得到sp,i,sp,i是原告诉称的第i个句子的嵌入表示,对于原告诉称,可以得到句子序列sp,1,sp,2……,sp,m。将句子序列输入到gru模型中,得到原告诉称的m个句子的总体表示;
hp,i=gru(sp,i,hp,i-1),i∈[1,m];
其中sp,i代表第i句子的原告诉称,hp,i-1代表上一步的输出的隐状态,m代表原告诉称的句子长度,最终得到最后的原告诉称表示,同理也可得到最终的被告辩称。
所述步骤3)中,除了利用到了上下文的表示,对于双方表述不同,但是含义相同的情况,对于原告所述步骤3)中,除了利用到了上下文的表示,对于双方表述不同,但是含义相同的情况,对于原告诉称和被告辩称,引入了主题向量表示。对于原告诉称的主题分布为tp=(tp,1,tp,2,…,tp,m)。tp,q注意力权重可以通过以下的计算公式得到:
其中hp,m是输入文本的最后的隐状态,用于提高相关主题的权重,弱化不相干主题的权重。被告辩称也可通过相同的公式得到。本装置将原告诉称和被告辩称的attention的进行联合计算,得到统一的主题注意力权重,计算公式如下所示:
αjq=mp,jq·wq·md,jq
本方法联合上下文注意力机制和主题注意力机制联合计算得到cj。计算公式如下所示:
其中tp,j是tp主题中的一个主题的向量,td,j是td主题中的一个主题的向量。
得到原告诉称和被告辩称的融合向量以后,并以此向量作为解码器的输入,并生成争议焦点,生成的所有词的概率如下公式所示:
其中,yj-1是指上一个预测的词,
dj=gru(yj-1,dj-1,cj)
其中
其中,wt,
应用实施例:参见图1、图2,一种基于深度学习的争议焦点生成方法,包括以下几个步骤:
步骤1)利用爬虫技术,从网络中爬取裁判文书,从爬取到的裁判文书中,筛选出含有原告诉称和被告辩称的裁判文书,并撰写规则从中抽取出相应的原告诉称和被告辩称。
详细步骤如下:
(1)中国裁判文书网的法律文书覆盖面全,文书质量较高,本实施例中以它作为文书的来源。
(2)撰写规则对文书进行处理,并抽取出原告诉称和被告辩称。
抽取的原告诉称例如“原告蔡某甲诉称:被告蔡某乙、杨某某是被告蔡某丙的父母。被告蔡某丙的父母为推卸对患有精神病女儿应承担的监护义务,隐瞒其女病情,委托介绍女儿与原告订婚,并索要彩礼438000元(有证人证言和转账为证)。订婚当天,被告蔡某乙、杨某某就催促原告将蔡某丙带回家。蔡某丙在原告家不到一个月即言行反常,并于2013年8月15日住进了精神病院。现原告为了维护自身的合法权益,诉求人民法院依法判令被告返还原告彩礼438000元。”
抽取的被告辩称例如“被告蔡某乙、杨某某、蔡某丙辩称:原告恶意杜撰一些事实以达到诋毁被告的目的。被告蔡某丙在订婚前曾就读于长乐职业中专学校,毕业后在长乐市林光荣中医内科上班,是一个正常健康的人,其是在与原告生活的这五个月期间精神状态发生异常的。”
具体的规则如下所示:
a.裁判文书的某一行中以“原告”作为这一行的起始字符,并且该行中含有“诉称”,“提出诉讼请求”,“诉求”等关键词,该行字符串即为原告诉称。
b.裁判文书的某一行中以“被告”作为这一行的起始字符,并且该行中含有“辩称”,“答辩状”,“陈述”,“某辩称”等关键词,该行字符即为被告辩称。
步骤2)对于抽取好的原告诉称和被告辩称按照1:1整理成原始数据集,从原始数据集中抽取10%作为训练集,并对训练集进行人工标注争议焦点。
步骤3)首先将原告诉称进行句子级的切分,对于每一个切分好的句子,进行分词,然后将句子放入gru模型,得到句子的最终表示,融入了句子中不同词的权重。
对于分词,首先利用jieba分词将原告诉称和被告辩称进行分词切分。例如将“被告蔡某的父母为推卸对患有精神病女儿应承担的监护义务”切分为“被告/蔡某/的/父母/为/推卸/对/患有/精神病/女儿/应/承担/的/监护/义务”,然后对其去停用词,得到词的序列为“被告/蔡某/父母/推卸/患有/精神病/女儿/承担/监护/义务”。将词序列输入到gru模型中,初试的hidden初始化为(0,0…….,0),维度为词向量的维度。公式如下所示:
hp,it=gru(xp,it,hp,it-1),t∈[1,r]
xp,it表示原告诉称的第i句第t个词的词向量,hp,it-1表示原告诉称第i句的t-1状态的隐状态,最终得到第r步的隐状态。利用第r步的隐状态和每一步的隐状态计算attention值,并将attention计算得到的权重,乘以相应的隐状态向量。
例如原告诉称“原告蔡某甲诉称:被告蔡某乙、杨某某是被告蔡某丙的父母。被告蔡某丙的父母为推卸对患有精神病女儿应承担的监护义务,隐瞒其女病情,委托介绍女儿与原告订婚,并索要彩礼438000元(有证人证言和转账为证)。订婚当天,被告蔡某乙、杨某某就催促原告将蔡某丙带回家。蔡某丙在原告家不到一个月即言行反常,并于2013年8月15日住进了精神病院。现原告为了维护自身的合法权益,诉求人民法院依法判令被告返还原告彩礼438000元。”得到的最终表示向量为(0.5478,…….,0.8254),维度为256维。
被告辩称“被告蔡某乙、杨某某、蔡某丙辩称:原告恶意杜撰一些事实以达到诋毁被告的目的。被告蔡某丙在订婚前曾就读于长乐职业中专学校,毕业后在长乐市林光荣中医内科上班,是一个正常健康的人,其是在与原告生活的这五个月期间精神状态发生异常的。”得到最终向量为(-0.1906,……,0.3269),维度为256维。
同时利用编码时每一句原告诉称句子和被告辩称句子的隐状态和解码时每一步的隐状态计算得到权重。并计算上下文联合权重。得到上下文联合权重为(0.0234,……,0.0592)。
计算主题权重,并计算联合主题权重,维度为(0.0189,……,0,0962)。
计算得到最终的原告诉称和被告辩称的整体表示为(-0.2348,……,0.4297)
步骤4)对于原告诉称“原告蔡某甲诉称:被告蔡某乙、杨某某是被告蔡某丙的父母。被告蔡某丙的父母为推卸对患有精神病女儿应承担的监护义务,隐瞒其女病情,委托介绍女儿与原告订婚,并索要彩礼438000元(有证人证言和转账为证)。订婚当天,被告蔡某乙、杨某某就催促原告将蔡某丙带回家。蔡某丙在原告家不到一个月即言行反常,并于2013年8月15日住进了精神病院。现原告为了维护自身的合法权益,诉求人民法院依法判令被告返还原告彩礼438000元。”和被告辩称“被告蔡某乙、杨某某、蔡某丙辩称:原告恶意杜撰一些事实以达到诋毁被告的目的。被告蔡某丙在订婚前曾就读于长乐职业中专学校,毕业后在长乐市林光荣中医内科上班,是一个正常健康的人,其是在与原告生活的这五个月期间精神状态发生异常的。”解码得到争议焦点为“婚前彩礼是否退还,是否婚姻期间伤害女方”。
5)上述原告诉称和被告辩称人工标注的争议焦点是“彩礼归属,婚姻期间是否对女方造成伤害”,使用交叉熵损失函数计算生成器生成的争议焦点和人工标注的争议焦点的损失函数,并且利用梯度下降的方式,调节生成器的参数,最终得到生成器模型;
6)利用训练得到的生成器对未标注的原告诉称和被告辩称进行争议焦点的自动生成。
需要说明的是上述实施例,并非用来限定本发明的保护范围,在上述技术方案的基础上所作出的等同变换或替代均落入本发明权利要求所保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!