一种基于三维信息的多相机协同的主动目标跟踪方法与流程
本发明属于计算机视觉、人工智能领域,涉及目标跟踪技术,尤其涉及一种基于三维信息的多相机协同的主动目标跟踪方法。
背景技术:
目标跟踪是计算机视觉中的一个重要而基础的问题,其目的是实时估计感兴趣目标在相机图像序列中的位置和尺度。到目前为止,视觉目标跟踪具有广泛的实际应用,如安全监控、视频监控、人机交互和自动驾驶。
传统的视觉目标跟踪工作主要集中于单相机的静态跟踪,相机不会根据跟踪情况反馈到自身的运动。单相机的静态跟踪主要包括基于相关滤波器的方法和基于深度学习的方法。基于相关滤波(correlationfilter)的跟踪方法因为速度快,效果好吸引了众多研究者的目光。相关滤波器通过将输入特征回归为目标高斯分布来训练滤波器。并在后续跟踪中寻找预测分布中的响应峰值来定位目标的位置。相关滤波器在运算中巧妙应用快速傅立叶变换获得了大幅度速度提升。目前基于相关滤波的拓展方法也有很多,包括kcf[1]、dsst[2]、长时目标跟踪[3]等。
然而,在大多数实际应用中,静态单相机跟踪方法的性能并不尽如人意。一方面受到遮挡、背景杂波和视距等诸多因素的影响,如果感兴趣的对象被长时间的遮挡,这些方法通常无法重新跟踪感兴趣的对象。另一方面由于相机的视野有限,静态跟踪无法处理感兴趣的物体移出相机视野的情况。为了解决这类问题,主动目标跟踪被广泛研究。例如[4],采用背景补偿和动态目标检测去实现主动目标跟踪。然而该方法主要针对的是动态的目标并不是一个固定的感兴趣目标。方法[5]通过估计目标的运动有目的的扩大搜索区域,实现稳定的主动目标跟踪,而该方法并无法解决运动模糊和遮挡等物体不在视野中的问题。
在这种情况下,利用多相机解决传统目标跟踪算法的缺陷成为研究人员重要的研究与探索方向。在多个相机的帮助下,跟踪器可以从不同的视角获取视觉信息,因为所有摄像机同时发生故障的概率很小,所以可以有效地处理遮挡、突然运动和目标出视野等问题。
[1]henriques,j.f.,caseiro,r.,martins,p.,batista,j.:high-speedtrackingwithkernelizedcorrelationfilters.ieeetrans.patternanal.mach.intell.37(3),583–596(2015)
[2]danelljanm,
[3]邓雪菲,彭先蓉,张建林,徐智勇.基于相关滤波的长时目标跟踪算法[j].半导体光电,,:1-7.
[4]murray,d.,basu,a.:motiontrackingwithanactivecamera.ieeetrans.patternanal.mach.intell.16(5),449–459(1994)
[5]ahmed,j.,ali,a.,khan,a.:stabilizedactivecameratrackingsystem.journalofreal-timeimageprocessing11(2),315–334(2016)
技术实现要素:
本发明提供了一种基于三维信息的多相机协同的主动目标跟踪方法,利用多相机以及三维信息有效减少了对单相机跟踪器跟踪精度的依赖,并且对遮挡、突然运动和背景杂波具有鲁棒性,最终大幅度延长了跟踪时间。本发明是通过以下技术方案实现的:
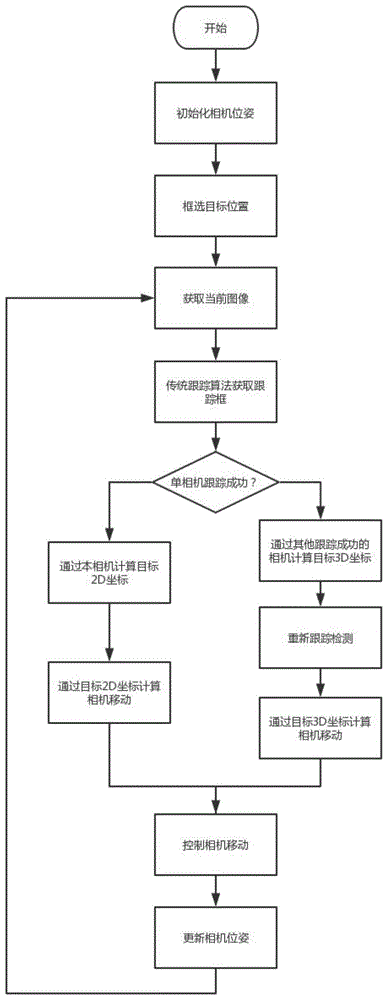
一种基于三维信息的多相机协同的主动目标跟踪方法,包括下列步骤:
步骤一,初始化各个相机k在三维空间中的位姿关系
步骤二,确定感兴趣的跟踪目标,并在各个相机k的视野图像
(1)对其中两个或三个相机,进行目标的人工框选,跟踪框表示为
(2)根据当前已成功框选的相机集合,三角化出目标中心的3d坐标p0,并投影到未进行框选相机集合
(3)纠正明显错误预测的相机,同时选择正确的相机加入成功框选的相机集合;
(4)重复(2)(3),直到目标位置在所有相机中初始化完毕
步骤三,对各个相机k及其捕获的当前时刻i的图像信息
步骤四,利用跟踪成功的相机计算目标中心的3d坐标pi,转换到跟踪失败的相机坐标系下
步骤五,对于失败相机的重跟踪,通过其他视角下的信息估计出的目标信息来进行快速有效的重跟踪;
步骤六,根据旋转矩阵控制相机移动,移动完成后,更新各相机的位姿信息。
优选地,
步骤一,通过sfm算法,计算各个相机k的初始位姿
步骤四的方法如下:
(1)通过其他跟踪成功相机中的当前位姿和目标中心在图像中的坐标三角化得到目标中心的3d坐标pi,转换为该失败相机坐标系下的3d坐标即
(2)对于一个跟踪失败的相机ck,根据上一步目标中心的3d坐标
进而计算出相机旋转矩阵
步骤五的方法如下:
在当前时刻i,通过目标中心的3d坐标
(1)响应峰值突然增大:yi>yi-1+δ,其中δ=0.2为阈值;
(2)响应峰值超过上次成功跟踪时刻j的响应峰值yj:yi>yj。
本发明能够在降低相机与运动控制平台间的累计误差的同时,减少运动恢复结构算法的计算量。本发明提供的技术方案的有益效果是:
1、本发明在跟踪过程中,可以利用不同视角下成功跟踪到目标的相机对物体中心的三维坐标进行估计,然后利用物体中心的三维坐标驱动当前时刻跟踪失败的相机持续跟踪物体。能够较好地解决传统跟踪器容易跟踪失效的情况,如严重遮挡、目标突然运动、目标移出相机视野等。减少了对单相机跟踪器跟踪精度的依赖,并且对遮挡、突然运动和背景杂波具有鲁棒性。
2、本发明在跟踪过程中,各相机可以通过与其他相机协作来执行有效的移动,一旦运动稳定或物体在视野中重新出现,相机就可以重新捕获物体。与静态跟踪器相比,本发明可以显著地延长物体在视野中的时间。
附图说明
图1为一种基于三维信息的多相机协同的主动目标跟踪方法的流程图;
图2为两个场景下不同时刻各个相机的跟踪情况,以及目标在空间中的运动轨迹示意图。
图3为目标中心与相机中心的距离随时间变化的曲线及在目标中心在图像中的分布。
图4为本发明提出的多相机协同的主动目标跟踪方法与传统目标跟踪算法的跟踪时间对比。
具体实施方式
(一)相机位姿初始化
在跟踪前,利用所有相机拍摄的不同视角的图像集合,通过多视图几何模型初始化相机之间的位姿关系。具体步骤如下:
(1)对于每个相机ck,固定相机坐标,在不同朝向下,拍摄多张各个视角下的图像,所有相机构成图像集合
(2)通过sfm算法及图像集合
算法1:sfm求解相机位姿:
第1步:特征提取。通过sift算法对每个图像提取特征点,并计算特征描述子。sift算法通过不同尺寸的dog得到图像的极值点,作为特征点。同时通过计算灰度直方图得到各个特征点f的特征描述子df。
第2步:特征匹配。对于一个图像对(i,j),其中
利用kd-tree加速匹配过程。利用对极几何,即i,j之间的基础矩阵f,或单应矩阵h做约束进行ransac进一步过滤错误匹配:
fff′t=0或f=hf′
第3步:增量重建。以下记k为相机内参。对于当前图像icur,根据与先前图像的特征匹配关系,通过3d-2d即pnp(一种常见的利用空间点和像素点的匹配关系求解位姿的算法)求解当前图像的初始位姿态tcur,优化重投影误差优化当前图像的位姿tcur:
将当前图像与先前图像成功匹配但未曾三角化的特征点对,三角化获得其3d坐标p,为后续图像计算位姿做准备。
第4步:整体优化。对所有图像的位姿以及三角化出的3d点,通过优化他们的重投影误差进行光束调整,:
对于相机ck,将其最后朝向所拍摄的图像位姿,作为初始位姿态
(二)目标位置初始化
确定感兴趣(即想要跟踪的目标),并在每个相机ck的视野图像
(5)对其中两个或三个相机,进行目标的人工框选,跟踪框表示为
(6)根据当前已成功框选的相机集合,三角化出目标中心的3d坐标p0,并投影到未进行框选相机集合
(7)纠正明显错误预测的相机,同时选择正确的相机加入成功框选的相机集合。
(8)重复(2)(3),直到目标位置在所有相机中初始化完毕。
(三)单相机目标跟踪
在跟踪过程中,对于每个相机,获取当前图像,通过传统跟踪模型获取目标在图像中的中心位置及跟踪框,并判断该相机是否成功跟踪到目标。具体步骤如下:
(1)通过传统跟踪算法kcf获取目标位置。
算法2:kcf获取跟踪框位置
第1步:起始帧采样。在起始帧中框选出待跟踪的目标,将矩形的选择框区域扩大2.5倍
第2步:计算特征。将矩形窗的样本进行余弦加权,然后计算hog特征,得到31维的hog特征图。特征的每个维度看成样本输入。
第3步:训练滤波器。构造回归模型,选取合适的核函数进一步简化到傅里叶域,训练得到一个初始滤波器,该回归器能够计算图像像素位置的响应值。
第4步:计算响应值。对于接下来的第i帧,在前一帧跟踪到的目标位置附近进行采样,用多尺度的滤波器与图像上的采样位置进行相关操作,得到每个采样点的响应值。
(2)判断检测目标位置成功性。
在第i帧中,我们记录此时响应峰值为yi,如果以下两点都满足,则认为跟踪失败:
1)响应峰值突然下降:yi<yi-1-δ,其中δ=0.2为阈值。
2)响应峰值低于阈值:yi<τ,其中τ=0.7为阈值。
该条件表明当响应峰值突然下降值且低于给定阈值为跟踪失败,否则为跟踪成功。若此次跟踪成功,则更新滤波器。
(3)更新滤波器。
以新找到的目标位置选取样本,计算用于当前帧的滤波器记为α,下一帧使用的滤波器αnew由当前计算滤波器与初始滤波器αold权重为m的线性插值得到:
αnew=mαold+(1-m)α
(四)多相机协同跟踪
由于运动过快、遮挡等原因,可能导致某些相机无法通过单相机成功跟踪到目标。所提方法对于成功跟踪的相机,使用反投影及相机旋转策略计算模型获得相机的旋转矩阵,并利用成功跟踪的相机集合获取目标的3d坐标,进而辅助失败的相机得到有效的旋转矩阵。具体步骤如下:
(1)对于跟踪成功的相机k,在第i帧中,通过kcf算法得到第i帧目标的跟踪框
其中fk,x,fk,y,ck,x,ck,y为相机内参。然后将坐标输入相机旋转策略计算模型,输出得到相机的旋转角度,即相机的俯仰角和偏航角的值。其中相机旋转策略计算模型如下:
算法3:相机旋转策略计算
第1步:通过偏移量及相机内参得到俯仰角
第2步:通过俯仰角
(2)通过其他跟踪成功相机中的当前位姿和目标中心在图像中的坐标三角化得到目标中心的3d坐标pi,转换为该失败相机坐标系下的3d坐标即
(3)对于跟踪失败的相机ck,通过目标中心的3d坐标
(五)失败相机重跟踪
在传统跟踪算法中,跟踪失败后的重跟踪由于搜索范围巨大,很难准确地进行重跟踪。本方法对于相机ck,通过目标中心的3d坐标
在当前时刻i,通过目标中心的3d坐标
(1)响应峰值突然增大:yi>yi-1+δ,其中δ=0.2为阈值。
(2)响应峰值超过上次成功跟踪时刻j的响应峰值yj:yi>yj。
其中响应值根据算法2计算得出。
(六)相机移动及位姿更新
本方法根据旋转矩阵控制相机移动,同时依据旋转矩阵更新相机的位姿,由于考虑到存在相机及控制元件手眼关系和误差累计的影响,以及sfm算法计算复杂度较高,因此本方法通过间歇式地进行sfm,提升相机位姿的准确度的同时保证算法的复杂度。(运动恢复结构算法sfm,常用的利用图像恢复相机位姿和场景结构的算法),具体方案如下:
(1)对于各个相机ck,通过算法三计算出的旋转矩阵
(2)各个相机ck执行完运动后,相机的位姿由
(3)若存在某个相机ce,总旋转量大于阈值
(4)当sfm返回该图像的位姿
下面结合具体的实例对以上方案进行可行性验证,详见下文描述:
实验用了3台可控相机实现了上述方法,为了证明上述方法的有效性,与传统静态目标跟踪器的方法(kcf)进行了比较。为了进行公平比较,在所有三个相机中都执行了传统静态跟踪算法。为了评估本发明所提出的方法,使用中心距误差(图像中目标中心位置到图像中心的欧式距离,用cde标记)来测量精度。此外,还利用可视时间、可跟踪时间和相机平均数量,与传统的静态跟踪器进行定量比较。
本发明方法的两个过程中一些代表性图像,包括目标运动轨迹和相机位姿,如图2所示。作为一个整体,对于每个相机,感兴趣目标的位置大致位于图像的中心。从场景1(c)、(f)、(g)等时刻,可以发现本发明方法可以准确地发现遮挡。此外,从一些目标长期被遮挡的场景1(c)(d)、场景2(c)(d)等过程中可以发现,通过多相机的协作,本发明方法可以准确估计遮挡期间对象的位置(蓝色边界框),并可以在遮挡后重新跟踪对象。
图3显示了本发明方法一个场景的cde曲线和物体中心的位置分布。在整个跟踪过程中,三个相机的cde保持一个较低的值(<300),这意味着物体始终保持在相机视野中心附近。当相机1中存在突然运动(21s、23s)和相机2中存在遮挡(36s、38s)时,可以通过与其他相机协作来执行有效的移动,一旦目标运动稳定或在视野中重新出现,相机就可以重新捕获物体。
为了进行比较,在不同的场景中进行了实验。图4将可视时间、可跟踪时间和相机平均数量与传统静态目标跟踪器的方法(kcf)进行比较。可视时间表示对象在至少一个相机的视野中的时间长度,可跟踪时间表示至少一个相机可跟踪对象的时间长度,相机平均数量表示每帧中成功跟踪的相机的平均数量。与传统静态跟踪器相比,本发明方法的跟踪器可以显著地延长物体在视野中的时间。此外,由于本发明方法在跟踪失败时仍能有效地移动并重新跟踪目标,因此可以清楚地看到,本发明方法比其他方法具有更多成功跟踪的相机,并且每个相机具有更长的跟踪时间。
- 还没有人留言评论。精彩留言会获得点赞!