恶意软件的检测方法及装置与流程
本发明涉及网络安全和软件检测技术领域,尤其涉及一种恶意软件的检测方法及装置。
背景技术:
近年来随着互联网的快速发展,依靠网络传播的恶意软件呈现爆炸式增长趋势。恶意挂马网站可以通过欺骗强制下载等手段诱骗用户将恶意软件下载至客户端,因此在网络流量监控系统中及时筛查有危害的恶意软件极为重要。
传统的恶意软件检测技术依靠人工生成的病毒特征码或规则库,对检测样本文件进行全文匹配,如果与特征库中的特征码相匹配,则报出恶意软件。该方法准确率高,误报率低,但依赖人工生成特征库或专家知识库,且检测效率低下。随着大数据时代的到来,对于大容量高速主干网络和需要进行海量文件交互的大型云平台,开发对恶意软件进行高效且准确度高的检测方法成为必然的发展趋势。
技术实现要素:
本发明要解决的技术问题是如何提高恶意软件检测效率和检测的准确性,本发明提出了一种恶意软件的检测方法及装置。
根据本发明实施例的恶意软件的检测方法,包括:
获取待检测软件的特征组合向量;
基于调整信息,从预先训练的模型簇中选择预定模型;
将所述特征组合向量输入所述预定模型中进行计算;
输出所述待检测软件的检测结果。
根据本发明实施例的恶意软件的检测方法,可以通过调整信息从模型簇中选择对应的预定模型,对待检测软件进行计算检测。调整信息的引入可以更好的根据待检测软件的实际情况调整检测模型和参数,而不仅仅依赖预设参数,从而能够更好的应对实际生产环境的变化。而且,利用机器学习模型簇取代单一机器学习模型进行检测可以更灵活的兼顾检测速率和检测精度,能应付复杂生产环境需求;自动调整检测效率和检测的准确性,使恶意软件的检测操作更具有针对性,提高了恶意软件的检测的自适应性。
根据本发明的一些实施例,所述特征组合向量的生成方法包括:
对所述待检测软件进行分段解析,提取所述待检测软件的分段特征;
由所述分段特征生成对应的分段特征向量;
将所述分段特征向量按预设规则组合,生成所述特征组合向量。
在本发明的一些实施例中,所述调整信息包括:前馈信息和反馈信息,
所述前馈信息包括安全威胁等级和性能要求指标;
所述反馈信息包括对所述检测结果的抽样检测的反馈量。
根据本发明的一些实施例,所述反馈信息包括:误报率和漏报率,
所述误报率为从所述检测结果抽样的恶意软件中的正常软件占比;
所述漏报率为从所述检测结果抽样的正常软件中的恶意软件占比。
在本发明的一些实施例中,所述模型簇的训练方法,包括:
从训练集中对样本软件进行分段特征提取,以获得多个训练分段特征;
基于多个所述训练分段特征生成对应的多个训练特征向量;
将多个所述训练特征向量进行组合,生成多个特征向量组合;
对每个所述特征向量组合进行模型训练,生成对应的训练模型,多个所述训练模型构成所述模型簇。
根据本发明实施例的恶意软件的检测装置,包括:
获取模块,用于获取待检测软件的特征组合向量;
模型选择模块,用于基于调整信息,从预先训练的模型簇中选择预定模型;
计算模块,用于将所述特征组合向量输入所述预定模型中进行计算;
输出模块,用于输出所述待检测软件的检测结果。
根据本发明实施例的恶意软件的检测装置,模型选择模块可以通过调整信息从模型簇中选择对应的预定模型,对待检测软件进行计算检测。调整信息的引入可以更好的根据待检测软件的实际情况调整检测模型和参数,而不仅仅依赖预设参数,从而能够更好的应对实际生产环境的变化。而且,利用机器学习模型簇取代单一机器学习模型,进行检测可以更灵活的兼顾检测速率和检测精度,能应付复杂生产环境需求;自动调整检测效率和检测的准确性,使恶意软件的检测操作更具有针对性,提高了恶意软件的检测的自适应性。
根据本发明的一些实施例,所述获取模块,包括:
分段提取模块,用于对所述待检测软件进行分段解析,提取所述待检测软件的分段特征;
向量生成模块,用于由所述分段特征生成对应的分段特征向量;
向量组合模块,用于将所述分段特征向量按预设规则组合,生成所述特征组合向量。
在本发明的一些实施例中,所述调整信息包括:前馈信息和反馈信息,
所述前馈信息包括安全威胁等级和性能要求指标;
所述反馈信息包括对所述检测结果的抽样检测的反馈量。
根据本发明的一些实施例,所述装置还包括模型簇训练模块,所述模型簇训练模块包括:
训练特征提取模块,用于从训练集中对样本软件进行分段特征提取,以获得多个训练分段特征;
训练特征生成模块,用于基于多个所述训练分段特征生成对应的多个训练特征向量;
训练特征向量组合模块,将多个所述训练特征向量进行组合,生成多个训练特征向量组合;
模型训练模块,用于对每个所述训练特征向量组合进行模型训练,生成对应的训练模型,多个所述训练模型构成所述模型簇。
根据本发明实施例的计算机存储介质,所述计算机存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上述所述的恶意软件的检测方法的步骤。
根据本发明实施例的计算机存储介质,通过执行本发明的恶意软件的检测方法,可以通过调整信息从模型簇中选择对应的预定模型,对待检测软件进行计算检测。调整信息的引入可以更好的根据待检测软件的实际情况调整检测模型和参数,而不仅仅依赖预设参数,从而能够更好的应对实际生产环境的变化。而且,利用机器学习模型簇取代单一机器学习模型,进行检测可以更灵活的兼顾检测速率和检测精度,能应付复杂生产环境需求;自动调整检测效率和检测的准确性,使恶意软件的检测操作更具有针对性,提高了恶意软件的检测的自适应性。
附图说明
图1为根据本发明实施例的恶意软件的检测方法流程图;
图2为根据本发明实施例的特征组合向量生成的方法流程图;
图3为根据本发明实施例的模型簇的训练方法流程图;
图4为根据本发明实施例的恶意软件的检测装置的结构示意图;
图5为根据本发明实施例的获取模块的结构示意图;
图6为根据本发明实施例的模型簇的结构示意图;
图7为根据本发明实施例的恶意软件的检测方法示意图;
图8为根据本发明实施例的特征组合向量及模型簇的生成示意图。
附图标记:
检测装置100,
获取模块10,
分段提取模块110,向量生成模块120,向量组合模块130,
模型选择模块20,
计算模块30,
输出模块40,
模型簇训练模块50,训练特征提取模块510,训练特征生成模块520,训练特征向量组合模块530,模型训练模块540。
具体实施方式
为更进一步阐述本发明为达成预定目的所采取的技术手段及功效,以下结合附图及较佳实施例,对本发明进行详细说明如后。
相关技术中,如公开号为:cn102779249b,名称为:《恶意程序检测方法及扫描引擎》的专利申请,利用机器学习方法进行恶意软件检测。该方法从恶意程序和正常程序样本中获取文件信息并提取特征,利用机器学习算法生成特征模型,再利用生成的模型对软件样本进行检测,最后通过给定阈值判定所提供的样本是恶意软件还是正常软件。
另如公开号为:cn107341401a,名称为《一种基于机器学习的恶意应用监测方法和设备》的专利申请,该专利同样使用机器学习方法用于检测移动端恶意软件,使用的机器学习模型为随机森林模型,提取样本中应用程序的应用特征和恶意标记,并映射至高维向量空间,再进行训练得到可用于检测的随机森林模型,最后利用该模型检测判断是否为恶意软件。
上述技术方案中,均存在如下技术缺陷:
上述检测方法需要对恶意样本整体提取特征,速度较慢。其机器学习判定阈值需要在模型验证和测试中进行确定,一旦实际生产中上线实施,其阈值和模型通常立即固化,不会频繁改变。因此当外界网络威胁环境或者待检测样本发生性质变化时,需要采集训练样本进行重新训练,得出新的机器学习模型,这个过程较为缓慢,实时性较差,不能应对快速变化的外界网络威胁等级改变。
为了解决在大容量主干网络或云平台海量数据情况下对恶意软件进行高速实时检测的问题,避免对每一个疑似恶意软件做整体解析和扫描带来的巨量时间消耗,本发明提出了一种恶意软件的检测方法及装置。
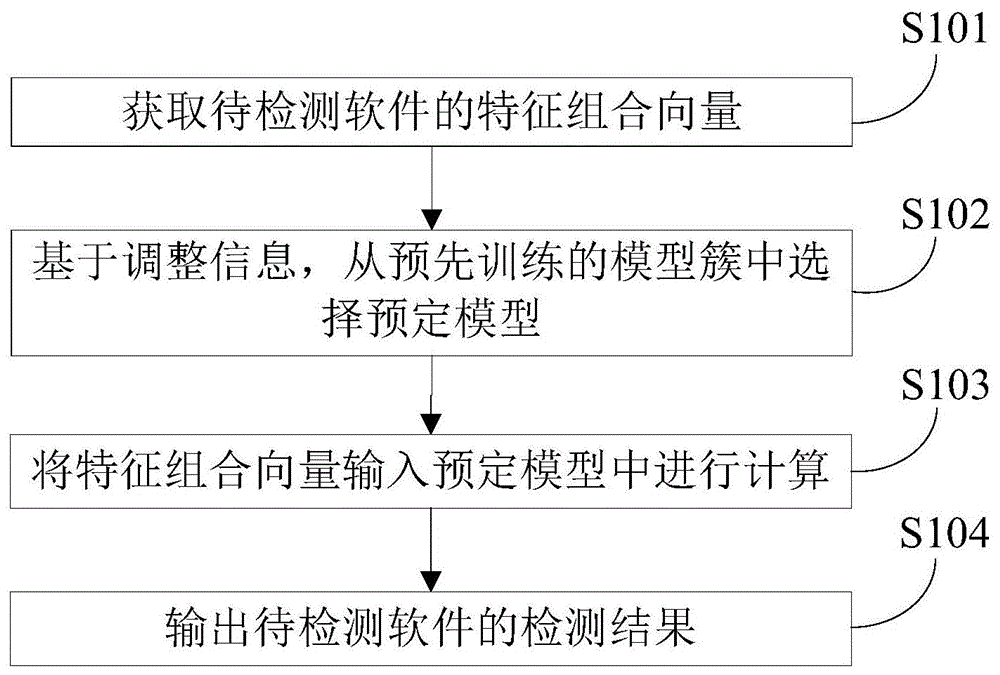
如图1所示,根据本发明实施例的恶意软件的检测方法,根据本发明实施例的恶意软件的检测方法,包括:
s101:获取待检测软件的特征组合向量;
需要说明的是,可以通过提取待检测软件的多个特征,构成多个特征向量,通过多个特征向量组合可以形成特征组合向量。
s102:基于调整信息,从预先训练的模型簇中选择预定模型;
也就是说,可以预先训练形成多个模型,多个模型构成模型簇。在对待检测软件进行检测时,可以根据调整信息从模型簇中选择预定模型。
s103:将特征组合向量输入预定模型中进行计算;
s104:输出待检测软件的检测结果。
根据本发明实施例的恶意软件的检测方法,可以通过调整信息从模型簇中选择对应的预定模型,对待检测软件进行计算检测。调整信息的引入可以更好的根据待检测软件的实际情况调整检测模型和参数,而不仅仅依赖预设参数,从而能够更好的应对实际生产环境的变化。而且,利用机器学习模型簇取代单一机器学习模型,进行检测可以更灵活的兼顾检测速率和检测精度,能应付复杂生产环境需求;自动调整检测效率和检测的准确性,使恶意软件的检测操作更具有针对性,提高了恶意软件的检测的自适应性。
根据本发明的一些实施例,如图2所示,特征组合向量的生成方法包括:
s201:对待检测软件进行分段解析,提取待检测软件的分段特征;
s202:由分段特征生成对应的分段特征向量;
s203:将分段特征向量按预设规则组合,生成特征组合向量。
在本发明的一些实施例中,如图7所示,调整信息可以包括:前馈信息和反馈信息。
其中,前馈信息可以包括安全威胁等级和性能要求指标;反馈信息可以包括对检测结果的抽样检测的反馈量。由此,利用前馈信息和反馈信息共同确定机器学习模型簇的选择和其中判定阈值的确定,在恶意软件检测时,可以实现实时自适应调整机器学习模型的模型选择和相关参数。需要说明的是,上述前馈信息和反馈信息所包括的内容仅是对本发明的举例说明,不应理解为对本发明的限制。本发明中的前馈信息和反馈信息还可以为其他调整参数,只要可以实现实时自适应调整机器学习模型的模型选择和相关参数的功能即可。
根据本发明的一些实施例,反馈信息包括:误报率和漏报率,
误报率为从检测结果抽样的恶意软件中的正常软件占比;
漏报率为从检测结果抽样的正常软件中的恶意软件占比。
在本发明的一些实施例中,如图3所示,模型簇的训练方法,包括:
s301:从训练集中对样本软件进行分段特征提取,以获得多个训练分段特征;
在进行模型训练时,可以利用分段解析待检测恶意样本和正常样本的代码,以获得多个训练分段特征。
s302:基于多个训练分段特征生成对应的多个训练特征向量;
s303:将多个训练特征向量进行组合,生成多个特征向量组合;
s304:对每个特征向量组合进行模型训练,生成对应的训练模型,从而生成包含多个机器学习模型的模型簇;
在进行模型训练时,可以采用gbdt(gradientboostingdecisiontree)方法训练机器学习模型,也可以采用其他机器学习方法训练模型。
如图4所示,根据本发明实施例的恶意软件的检测装置100,检测装置100可以包括:获取模块10、模型选择模块20、计算模块30和输出模块40。
获取模块10可以用于获取待检测软件的特征组合向量;
需要说明的是,可以通过提取待检测软件的多个特征,构成多个特征向量,通过多个特征向量组合可以形成特征组合向量。
模型选择模块20可以用于基于调整信息,从预先训练的模型簇中选择预定模型;
也就是说,可以预先训练形成多个模型,多个模型构成模型簇。在对待检测软件进行检测时,模型选择模块20可以根据调整信息从模型簇中选择预定模型。
计算模块30,用于将特征组合向量输入预定模型中进行计算;
输出模块40,用于输出待检测软件的检测结果。
根据本发明实施例的恶意软件的检测装置100,模型选择模块20可以通过调整信息从模型簇中选择对应的预定模型,对待检测软件进行计算检测。调整信息的引入可以更好的根据待检测软件的实际情况调整检测模型和参数,而不仅仅依赖预设参数,从而能够更好的应对实际生产环境的变化。而且,利用机器学习模型簇取代单一机器学习模型,进行检测可以更灵活的兼顾检测速率和检测精度,能应付复杂生产环境需求;自动调整检测效率和检测的准确性,使恶意软件的检测操作更具有针对性,提高了恶意软件的检测的自适应性。
根据本发明的一些实施例,如图5所示,获取模块10可以包括:分段提取模块110、向量生成模块120和向量组合模块130。
其中,分段提取模块110可以用于对待检测软件进行分段解析,提取待检测软件的分段特征;
向量生成模块120可以用于由分段特征生成对应的分段特征向量;
向量组合模块130可以用于将分段特征向量按预设规则组合,生成特征组合向量。
在本发明的一些实施例中,如图7所示,调整信息可以包括:前馈信息和反馈信息,
其中,前馈信息包括安全威胁等级和性能要求指标;反馈信息包括对检测结果的抽样检测的反馈量。由此,利用前馈信息和反馈信息共同确定机器学习模型簇的选择和其中判定阈值的确定,在恶意软件检测时,可以实现实时自适应调整机器学习模型的模型选择和相关参数。
根据本发明的一些实施例,如图4所示,检测装置100还可以包括模型簇训练模块50。如图6所示,模型簇训练模块50包括:训练特征提取模块510、训练特征生成模块520、训练特征向量组合模块530和模型训练模块540。
训练特征提取模块510可以用于从训练集中对样本软件进行分段特征提取,以获得多个训练分段特征;在进行模型训练时,可以通过训练特征提取模块510分段解析待检测恶意样本和正常样本的代码,以获得多个训练分段特征。
训练特征生成模块520可以用于基于多个训练分段特征生成对应的多个训练特征向量;
训练特征向量组合模块530可以将多个训练特征向量进行组合,生成多个训练特征向量组合;
模型训练模块540可以用于对每个训练特征向量组合进行模型训练,生成对应的训练模型,多个训练模型构成模型簇。
根据本发明实施例的计算机存储介质,计算机存储介质上存储有计算机程序,计算机程序被处理器执行时实现如上述的恶意软件的检测方法的步骤。
根据本发明实施例的计算机存储介质,通过执行本发明的恶意软件的检测方法,可以通过调整信息从模型簇中选择对应的预定模型,对待检测软件进行计算检测。调整信息的引入可以更好的根据待检测软件的实际情况调整检测模型和参数,而不仅仅依赖预设参数,从而能够更好的应对实际生产环境的变化。而且,利用机器学习模型簇取代单一机器学习模型,进行检测可以更灵活的兼顾检测速率和检测精度,能应付复杂生产环境需求;自动调整检测效率和检测的准确性,使恶意软件的检测操作更具有针对性,提高了恶意软件的检测的自适应性。
下面以最常见且危害最大的pe型恶意软件为例描述本发明的恶意软件的检测方法。需要说明的是,本申请并非仅局限用于对pe型恶意软件检测,还可以用于其他类型恶意软件,例如恶意androidapk文件,恶意html文件,恶意doc和pdf文件等也可采用本发明的恶意软件的检测方法进行检测。
如图7所示,待检测样本分段解析模块的作用是解析获得的pe文件内容,并分段提取特征。在高速主干网络对包含pe文件的报文进行分段解析可以有效的提高检测速率。分段的规则可以依据逻辑或功能划分。
如图8所示,对于pe文件可以划分为dosmz头,pe头,节表,各不同节段,附加内容等。不同编译器产生的pe文件的节名也不完全相同,例如经过vc++编译后运行代码会存储于.text节而经过borlandc++编译后运行代码存储于.icode节。这些不同节名称的区别并不影响本发明实施时依靠功能或逻辑来分节的方法。
图7中机器学习模型簇的生成方式可由图8展示。对于某一pe类型程序代码,其二进制代码组成可分为dosmz头,pe头,节表,.text节,.data节,.rsrc节,.reloc节等,以及附加数据(overlay),以上各节除dosmz头,pe头,节表以外,其余各节根据编译器和代码不同能够以不同名称或形式存在,也可以不存在,但在本实施例中假设其全部存在,如果在其他实施例中不存在或者以其他形式存在时,仅需在划分组合时做细微调整,并不影响本方法的实施。
在本实施例中,pe文件可以如图8划分为1,2,…,n组,根据其中每一组的组成方式,可以提取机器学习训练集的恶意pe代码和正常代码相应的特征进行训练,生成对应的机器学习模型1,模型2,…模型n。
图7中的前馈(feedforward)模块接收外部提供的网络安全威胁等级数据,并向机器学习模型簇传输数值化的安全威胁等级,在本实施例中将安全威胁等级划分为0,1,2…p级,0级为正常,p级为网络安全威胁最大。如何将外界网络威胁情报转化为量化的安全威胁等级,已有很多具体实施例,因此不再赘述。前馈模块中的另一项性能要求指标信息决定机器学习检测模块的运行时间效率,通常对pe文件解析的分段不同,解析所需要的速率也不相同。此情形在高速主干网络抓取报文,并解析检测恶意pe文件中比较突出。对于所需的检测时间,通常有:t(组合1)<t(组合2)<……<t(组合n)。
而根据实际检测环境的需求,在本实施例中,检测速率可划分为0,1,2,…q级,0级为正常检测速率指标,q级为要求检测速率最快的指标。
图7中的反馈(feedback)模块对经过机器学习检测模块已检测完成的样本进行抽样再检测。
在本实施例中,对检测结果判明为恶意软件的样本抽取m1数量进行再检测,对判明为正常软件的检测后样本抽取m2数量进行再检测,检测手段可以采用业界公认精准度较高但时间效率较低的沙箱动态行为检测。在m1数量样本中若检测出正常软件n1个则可以计算误报率σ,在m2数量样本中若检测出恶意软件n2个则可以计算漏报率ω,具体计算方法如下:
本实施例中提出的反馈模块输出给机器学习模型簇的反馈量f计算方法如下:
f=σ+ω
通过前馈模块和反馈模块传输给机器学习模型簇的数据可以用来确定选取第l个机器学习模型,并确定其判定阈值为δ。其中1≤l≤n,0≤δ≤1。
进一步具体的,在本实施例中,可以通过检测速率指标(0,1,2,…q)确定选取哪一种机器学习模型。检测速率要求快的需要选择包含分段数量少的模型,例如模型1;检测速率不做特殊要求但对精度有较高要求的可以选择模型n。通过网络安全威胁等级(0,1,2,…,p)和反馈模块的反馈量f可以确定对应的机器学习判定阈值δ,一般的安全威胁等级越高,f越大,则说明原模型判定结果实际中检测较差,阈值需要增加,反之则需要减少。具体取值则可以在实际生产环境中根据经验建立映射对照表获取。
进一步具体的,在图8中依靠分段解析的pe文件生成机器学习模型簇,可以提取以下分组特征:
组合1包含的机器学习特征:pe头时间戳,pe头中可识别字符串序列,pe头coff段中各种信息,例如timestamp,machine,characteristics。pe头optional字段中各种信息,例如:subsystem,dll_characteristics,sizeof_code,sizeof_headers,sizeof_heap_commit等。
组合2包含的机器学习特征:组合1的特征,节表中{section_name:section_size,section_virtualsize}键值对,{section_name:section_characteristics}键值对。
依靠不同组合可以逐一添加的特征还包括各节的具体特征数据,例如节名,节的字节数,节字节熵,包含的可识别字符串,特定字符串数量等,以及可能包含的导入函数列表和导出函数列表。
组合n包含的机器学习特征:组合1,2,…n-1的特征,另外还包括pe文件可能含有的附加数据(overlay),由于附加数据可以是打开pe文件所需的文档,图片,音频,视频等二进制代码,一般仅提取其中二进制或十六进制代码的统计信息特征。
可以理解的是,以上仅为本发明的特征提取方法的举例,在具体实施中,还可以有类似但不完全相同的特征提取方法。
综上所述,本发明提出的恶意软件的检测方法具有如下特点和有益效果:
利用分段解析待检测软件样本并提取部分特征可以节约报文解析的时间,提高检测效率和速度;
利用机器学习模型簇取代单一机器学习模型进行检测可以更灵活的兼顾检测速率和检测精度,能应付复杂生产环境需求;
前馈信息和反馈信息的引入可以更好的根据外部网络安全威胁环境的变化调整检测模型和参数,并能根据实际测试样本的结果调整检测阈值参数,而不仅仅依赖研发环境中的预设参数,能够更好的应对实际生产环境的变化。
通过具体实施方式的说明,应当可对本发明为达成预定目的所采取的技术手段及功效得以更加深入且具体的了解,然而所附图示仅是提供参考与说明之用,并非用来对本发明加以限制。
- 还没有人留言评论。精彩留言会获得点赞!