基于货柜场景下的实时存取行为检测方法和系统与流程
本发明涉及深度学习中人体关键点识别技术领域、图像分类识别技术领域和一套行为检测规则方法和系统。
背景技术:
目前,在视频行为理解的技术条件下,人体行为检测技术可用于货柜场景下存取行为检测技术方案主要如下几种:
(1)基于双流的方法,单帧rgb作为输入的cnn(卷积神经网络)来处理空间维度的信息,使用以多帧密度光流场作为输入的cnn来处理时间维度的信息,最后通过空间维度信息和光流信息来进行行为识别。
(2)基于c3d(三维卷积)的方法,采用3d卷积深度网络对整段视频进行时空建模,直接进行行为识别。
(3)基于cnn-lstm(卷积神经网络-长短时记忆神经网络)的方法,使用cnn提取视频中每帧的特征信息,将每帧的特征信息使用lstm进行处理,最终识别出行为。
(4)基于目标检测-跟踪-识别方法,使用目标检测来对每一帧中的roi进行跟踪,然后对检测到的动作进行行为识别。
(5)基于关键点技术的lstm或者gcn(图卷积神经网络)方法,使用关键点检测网络提取关键点坐标,然后使用lstm或者gcn对关键点坐标进行时空建模,最终检测出行为。
但是,现有的人体动作识别技术,存在着以下的缺点:
(1)以上所述的(1)、(2)、(3)、(4)的方法虽然在不同程度上提高了人体行为检测/识别的准确率,但由于算法时空复杂度高,所以很难达到实时检测,货柜场景下需要检测人的存取行为需要一定的实时性。
(2)以上所述的方法(5)在实时性和准确性方面都有很好的提升,但是有俯视场景下并不能完整的检测人体的所有关节点,能够鲁棒检测的只有手腕关键点和手掌关键点,而(5)通常需要较多的关键点来,所以在应用上存在一定的困难。
(3)以上所述的算法模型相对复杂,在普通pc设备上部署困难。
技术实现要素:
本发明提供一种可以在货柜平台俯视角度的场景下检测人体存取行为的方法和系统,该方法具有成本低、高鲁棒、高实时等优点,很容易部署到pc设备中。
本发明使用关键点检测网络、手部物体有无分类网络。关键点检测网络接收视频图像,检测手掌关键点和手腕关键点信息。分类网络接收手部roi区域(感兴趣区域regionofinteresting),检测手部物体有无信息。使用存取行为规则接收两个网络输出的信息来进行判别手部行为。
为实现上述目的,本发明提供一种实时的存取行为方法,所述实时的存取行为方法包括以下步骤:
获取采集的人体视频图像,逐帧送入预设的手部关键点检测网络中,得到手腕关键点、手部掌心关键点;
记录手腕关键点的轨迹信息,每一帧的关键点与起始的关键点可以推理手部的运动信息;
手腕关键点和手掌关键点可以推测手部roi区域,然后将手部roi区域送入预设的分类模型,执行手部是否有无物体的二分类;
利用手部运动信息和手部物体有无分类信息按照预设的规则进行存取行为的判别。
与现有技术相比较,本发明具有如下技术效果。
可以从技术原理和本方法实施的角度考虑下,本发明的技术特色以及技术优势所在之处。
1.本发明的算法时间复杂度和空间复杂很低,可以做到实时检测。
2.本发明具有较高的鲁棒性,能够很好适应货柜场景。
3.本发明仅仅依赖手部信息就可以取得很好的检测结果。
4.本发明可以很方便的在本地pc机上部署,不需要高性能服务器。
附图说明
图1是本发明人货柜场景下存取行为识别方法的流程示意图;
图2是本发明人预测手部关键点的流程示意图;
图3是本发明人预测手部运动信息的流程示意图;
图4是本发明人预测手部物体有无信息的流程示意图;
具体实施方式
应当理解,此处所描述的具体实例仅仅用以解释本发明,并不用于限定本发明。本发明经过了算法验证,基于货柜场景下的实时存取行为检测系统包括:gpu、cpu、内存卡、rgb广角摄像头和显示屏。gpu为英伟达gtx1050ti,cpu为英特尔第8代酷睿i5;
实施过程:rgb广角摄像头部署在货柜正上方,确保能够拍到进入货柜的人手。rgb广角摄像头与pc机相连,pc机通过rgb广角摄像头逐帧采集图像,采集图像后送入内存卡,之后通过pc机的gpu和cpu系统执行整个算法流程,存取结果将显示在显示屏上。采集图像、图像处理、逻辑运算等计算需要cpu进行处理,神经网络的计算需要使用gpu。
算法框架参考如下:
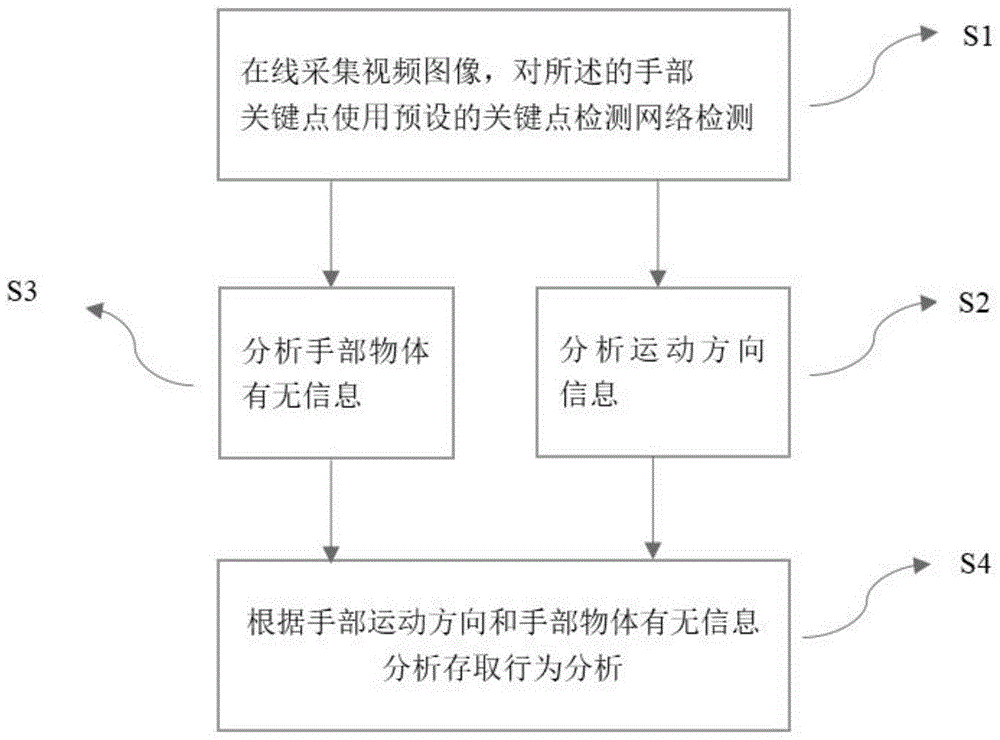
请参照图1,图1是本发明提出的基于货柜场景下的存取行为检测实例的流程示意图。
如图1所示,本发明实施里提出一种基于货柜场景下的存取行为检测方法,所述的人体行为检测总体上包括以下步骤:
步骤s1,在线获取人体视频图像,对所述的手部视频图像使用关键点检测的网络进行特征提取,获得手腕关键点,手部掌心关键点。
步骤s2,记录并且分析手腕关键点运动信息;
步骤s3,将手部roi送入到分类模型中,识别手部物体有无。
步骤s4,使用规则对手部关键点运动信息和手部物体有无进行行为检测。
具体的算法参考如下:
步骤s1具体算法如图2所示,使用dhrnet-lite网络对视频图像逐帧检测,得到手腕关键点概率图、手掌心关键点概率图,计算关键点概率图中的最大概率点的坐标,然后这个最大概率值与设置的阈值α(α>0.5)作比较,若这个概率值超过阈值α,则取得该点的坐标有效,否则丢弃这个预测,视为没有预测到相应的坐标。有效的手腕关键点和手掌关键点会存入到一个先进先出的队列q中,队列为有限长,根据实际场景设置合适的长度。
其中,关键点的检测模块的基础网络参考dhrnet,针对原始冗余的dhrnet网络进行减枝,分别从原始网络的分支数量、通道宽度、网络深度进行裁剪,构成轻量版本的dhrnet-lite。根据需要求解的关键点来对dhrnet-lite网络进行有监督的训练,得到dhrnet-lite网络模型。
步骤s2具体算法如图3所示,得到手腕关键点坐标后,计算关键点的运动信息,求解手部的伸缩信息。首先从队列q中连续取出两个时间点的手腕关键点坐标,先取出来的为当前帧的关键点坐标,后取出来的为前一帧的关键点坐标,计算运动方向时我们仅仅使用手腕关键点信息,然后计算前一帧的关键点和当前关键点的关键点之间的矢量,假设前一帧手腕关键点的坐标为p1=(x1,y1),x1表示手腕关键点在图像中的横坐标,y1表示手腕关键点在图像中的纵坐标,在图像当前帧手腕关键点的坐标p2=(x2,y2),x2表示手腕关键点在图像中的横坐标,y2表示手腕关键点在图像中的纵坐标,则瞬时运动矢量为s=(x2-x1,y2-y1)=(x3,y3),而s的大小就是手在前后两帧的位移距离为
步骤s3具体算法如图4所示,得到手部关键点信息后,计算手部roi区域,求解手部物体有无信息。首先从步骤s2得到对应的手腕关键点h1和手掌关键点h2,根据检测到的掌心关键点坐标和手腕关键点坐标计算roi区域,所述的roi区域为正方形区域,使用手掌关键点作为roi区域的形心,使用手掌到手腕的距离的2倍作为roi区域的边长,其中roi区域的下边与图像的下边保持平行。在得到roi区域后,将roi区域使用线性变换映射到预设的图像尺寸(根据实际场景定制图像尺寸),使用resnet6网络进行分类,识别手部物体有无。
其中,分类模块参考resent网络,堆叠6个residualblock,最后全连接层作为预测层,得到resnet6网络,预测手部物体有无两种信息。使用固定尺寸大小的图像对resnet6网络进行有监督的训练。
步骤s4具体算法规则,根据手部物体有无信息和手部运动信息来判别手部行为信息。手缩回时,若手中有物体,则判定为存物体。手伸展时,若手中有物体,则判定为取物体。
- 还没有人留言评论。精彩留言会获得点赞!