用于存储器中心型计算机的MPI程序转换方法及装置与流程
相关申请的交叉引用
本申请要求于2018年10月25日提交的韩国专利申请no.10-2018-0128371与要求于2018年12月2日提交韩国专利申请no.10-2018-0160347的优先权和权益,其通过引用合并于此用于所有目的,如同在此完全阐述一样。
本公开涉及一种用于存储器中心型计算机的mpi程序转换方法及装置。
背景技术:
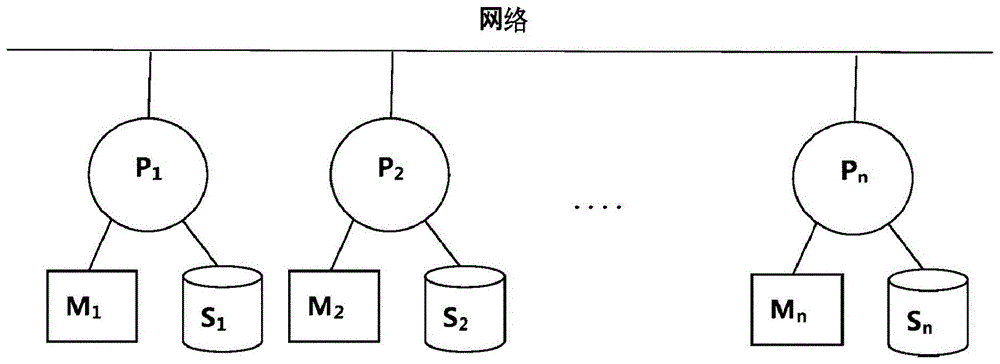
分布存储器结构(distributedmemoryarchitecture)的hpc(highperformancecomputer,高性能计算机)系统如图1所示,具有在一通信网络(communicationnetwork)上并联多个单元计算机(或者处理器,p1~pn)的结构。在高性能计算机系统中,在由多个单元计算机执行并行程序的过程中任意一单元计算机能够将包含中间计算结果的消息通过所述通信网络向其他单元计算机传送。这种现有系统的各单元计算机备有作为半导体储存装置的如存储器(m1~mn)和hdd的物理的储存装置的储存器(s1~sn)。
如上所述的利用通信网络的单元计算机间的消息传送方式由于速度缓慢因此对于并行程序的性能提高具有局限性。这归因为通信网络自身具有的局限性。
技术实现要素:
至少一个实施例提供一种将可在现有高性能计算机中执行而开发的mpi并行程序进行自动转换的方法及装置以使所述mpi并行程序在存储器中心型计算机中更加有效地执行。
至少一个实施例涉及的转换方法
在执行并行处理的计算机系统中,在执行mpi(messagepassinginterface,消息传递接口)并行程序的过程中,为了使任意一台计算机中生成的数据能够被其他计算机直接访问,分析(parsing)mpi函数,将相关mpi函数转换为网络函数以与其他计算机进行基本的通信,并生成能够通过总线线路直接访问存储器的总线线路命令。
在至少一个实施例中,为了自动转换mpi并行程序,提供了如下的新型结构体及函数。此外,还提供利用所述新型结构体及函数的根据不同mpi函数的转换方法。
1)mc_message型(type)
2)帮助函数
3)根据不同的主要mpi函数的转换
至少一个实施例涉及的mpi程序转换方法可包括:
执行分散处理的多台计算机装载用于并联的高性能计算机系统的mpi(messagepassinginterface,消息传递接口)并行程序的源代码的步骤;
通过分析(parsing)所述源代码法来提取(extract)mpi函数命令文本(statement)的步骤;
利用所述mpi函数命令文本将相关的pi函数生成通过网络与另一计算机进行通信的网络函数命令文本及生成通过总线线路直接访问由多台计算机共享的存储器的总线线路函数命令文本的步骤;以及
储存包括所述网络函数命令文本和总线线路函数命令文本的转换的源代码的步骤。
在至少一个实施例涉及的mpi程序转换方法中,所述网络函数命令文本可包括用于储存绝对地址信息的绝对地址传递者。
在至少一个实施例涉及的mpi程序转换方法中,所述绝对地址传递者可由包括所述存储器的绝对地址信息的结构体(对象)生成。
在至少一个实施例涉及的mpi程序转换方法中,所述mpi函数可包括mpi_send、mpi_recv、mpi_bcast、mpi_reduce、mpi_scatter、mpi_gather中至少一个。
在至少一个实施例涉及的mpi程序转换方法中,包括所述mpi_send函数的命令文本可包括储存绝对地址信息的绝对地址传递者并作为参数,在执行所述mpi_send函数命令文本后,等待来自目标计算机的响应。
在至少一个实施例涉及的mpi程序转换方法中,包括所述mpi_recv函数的命令文本可包括作为参数的用于储存绝对地址信息的绝对地址传递者,在执行所述mpi_recv函数命令文本后,可向执行mpi_send函数命令语的源计算机发送响应信号。
在至少一个实施例涉及的mpi程序转换方法中,
包括所述mpi_bcast函数的命令文本为:
当相关进程为根进程时,在执行向其他所有进程传递绝对地址信息的mpi_bcast函数后,等待来自其他所有进程的响应,或者
当相关进程不为根进程时,在执行mpi_bcast函数后,向根进程传送响应信号。
在至少一个实施例涉及的mpi程序转换方法中,
包括所述mpi_reduce函数的命令文本为:
当相关进程为根进程时,接收其他所有进程的绝对地址信息并执行运算符(operator)计算的mpi_reduce函数,或者
当相关进程不为根进程时,执行mpi_reduce函数以将相关进程的绝对地址信息向根进程传递。
在至少一个实施例涉及的mpi程序转换方法中,
包括所述mpi_scatter函数的命令文本为:
当相关进程为根进程时,执行mpi_scatter函数以传递其他所有进程的绝对地址信息的排列,或者
当相关进程不为根进程时,执行mpi_scatter函数以将根进程传送的消息储存在相关进程的绝对地址信息中。
在至少一个实施例涉及的mpi程序转换方法中,
包括所述mpi_gather函数的命令文本为:
当相关进程为根进程时,在执行将其他进程的绝对地址信息以排列的形式储存在相关进程的绝对地址上的mpi_gather函数后,将所有处理器的绝对地址信息以排列的形式储存,或者
当相关进程不为根进程时,执行传递相关进程的绝对地址信息的mpi_gather函数。
根据至少一个实施例,一种用于存储器中心型计算机的mpi程序转换系统,所述系统用于转换mpi并行程序的源代码,所述mpi并行程序的源代码用于多台计算机并联并执行分散处理的计算机系统中,该mpi程序转换系统可包括,
储存媒介,其用于储存源代码和转换的源代码;以及
处理装置,其通过分析所述源代码来提取mpi函数命令文本,利用提取的mpi函数命令文本将相关mpi函数通过网络生成与其他计算机进行通信的网络函数命令文本及生成通过总线线路直接访问由多台计算机共享的存储器的总线线路函数命令文本,然后将包括所述网络函数命令文本和总线线路函数命令文本的转换的源代码储存在所述储存媒介中。
附图说明
被包括以提供对本发明的进一步理解并且被并入且构成本说明书的一部分的附图例示本发明的示例性实施例,并且与说明书一起用于解释本发明构思。
图1例示分布式存储器结构的计算机系统的结构。
图2例示存储器中心型结构的计算机系统的结构。
图3是概念性地图示至少一个实施例涉及的函数转换过程的流程图。
图4根据本发明至少一个实施例图示了mpi函数之一的mpi_send的转换过程。
图5根据本发明至少一个实施例图示了mpi函数之一的mpi_recv的转换过程。
图6根据本发明至少一个实施例图示了mpi函数之一的mpi_bcast的转换过程。
图7根据本发明至少一个实施例图示了mpi函数之一的mpi_reduce的转换过程。
图8根据本发明至少一个实施例图示了mpi函数之一的mpi_scatter的转换过程。
图9根据本发明至少一个实施例图示了mpi函数之一的mpi_gather的转换过程。
具体实施方式
以下,参照附图对至少一个实施例涉及的mpi程序转换方法进行说明。
存储器中心型计算机(mc:memorycentriccomputer)系统如图2所示,作为具有将多个单元计算机p1~pn直接连接在十分快速的共享存储器mshared(sharedmemory)的结构的一种系统,为了进行计算机间的消息传送,不使用速度缓慢的通信网络,而是直接访问快速的共享存储器。
截至目前为止,开发的众多并行程序是使用称之为mpi(messagepassinginterface,消息传递接口)的标准库函数编写的,即使有新开发的存储器中心型计算机结构上市,由于该mpi并行程序使用速度缓慢的通信网络,因此也只能低效率地执行。
如图2所示的存储器中心型计算机不同于现有的存储器分散型计算机,具有所有的单元计算机共享共享存储器mshared的形态,不使用如现有使用的hdd等的物理性储存装置,而只使用作为半导体储存装置的存储器mshared。这种存储器中心型计算机系统相比于接近饱和状态的cpu开发,基于仍然能够实现迅速处理及提高容量的半导体存储器的到来得到助力。
在至少一个实施例中,在执行分散处理的cpu中心的高性能计算机系统的mpi并行程序中,为了使任意一台计算机所生成的数据通过存储器可被其他计算机直接访问,分析(parsing)源代码内的mpi函数,并将相关mpi函数转换为网络函数以与其他计算机进行基本的通信,并生成通过总线线路直接访问储存其他计算机的运算结果的存储器的总线线路命令。
上述的mpi(messagepassinginterface)作为用于并行编程的标准兼容库,目前支持c,c++,fortran等的编程语言。这种mpi作为hpc(highperformancecomputing,高性能计算)系统中使用最多的并行编程工具,由学界及产业界机构构成的mpi论坛(forum)主管。
如图3所示,至少一个实施例涉及的程序转换方法包括:
装载源代码的步骤;
分析源代码并提取作为转换对象的mpi函数命令文本的步骤;
从所述命令文本中提取函数的参数的步骤;
定义并生成用于与其他计算机进行存储器信息传递的绝对地址传递者的步骤;
利用(或分析)提取的原始(raw)mpi函数,将所述提取的mpi函数转换为通过网络在单元计算机间进行基本通信的网络命令(一个或者多个命令语),并生成通过总线线路直接访问存储器的总线线路命令(一个或者多个命令语)的步骤;以及
储存包括在所述过程中转换的命令文本的转换的代码的步骤。
本实施例的说明书中提及的mpi是用于并行处理的典型的库的一例,但是本发明明显不限于这种特定的库。
在至少一个实施例中,通过网络函数从相关的计算机接收储存有其他计算机的运算结果的存储器的绝对地址,使接收所述绝对地址的计算机通过总线线路函数直接访问存储器上的绝对地址。
为此,在本发明至少一个实施例中,定义或者生成用于储存及传递绝对地址的结构体(structure)及其相关的帮助函数(helperfunctions)。
在此,结构体的生成是用于传递存储器的绝对位置,很明显可由独立的一个或者多个变量、特别地由指示器变量替代。
i.绝对地址传递者(absoluteaddresstransporter)
为了自动转换现有高性能计算机系统中执行的mpi并行程序以使所述mpi并行程序在存储器中心型计算机中更加有效地执行,在至少一个实施例中定义了如下的新型结构体(structure),例如“mc_message”。
该结构体的成员包括大小变量,所述大小变量用于储存待传递的消息的绝对地址(absoluteaddress)的绝对地址变量和绝对地址变量的大小。定义如下的结构体mc_message是用于表示固定大小的字节(size-1)的消息,该结构体可包括‘addr'及size',所述‘addr'用于储存地址信息和地址信息的大小,例如绝对地址,所述‘size'用于储存大小(长度)。
typedefstruct{
void*addr;
intsize;
}mc_message
ii.帮助函数(helperfunctions)
为了自动转换mpi并行程序以使所述mpi并行程序在存储器中心型计算机系统中更加有效地执行,在至少一个实施例中定义或者生成如下的帮助函数。该函数也同样用于转换在至少一个实施例中执行的mpi函数。
a.帮助函数1:
可能需要将目前进程(process)的虚拟地址转换为绝对地址的函数。为此,在本实施例中定义帮助函数1如下。
mc_address(addr)
函数mc_address可将目前进程的虚拟地址“addr”转换为绝对地址并作为返回值返回绝对地址。
b.帮助函数2
可能需要将绝对地址的数据复制到目前进程的虚拟地址。为此,在本实施例中定义帮助函数2如下。
mc_memcpy(to,from,size)
函数“mc_memcpy”将由参数“from“传递的从绝对地址起具有“size”大小的数据复制到目前进程的虚拟地址参数“to”。
c.帮助函数3
为了与特定等级的单元计算机进行通信,可能需要向相关单元计算机发送信号的函数。为此,在本实施例中定义帮助函数3如下。
mc_post(rank)
函数mc_post向具有给定等级(rank,单元或者进程号码)的单元计算机(进程)发送响应信号。该函数可用于判断是否能够与相关单元计算机进行通信。
d.帮助函数4
为了与特定的单元计算机进行通信,向相关单元计算机发送信号后,可能需要等待其响应的函数。为此,在本实施例中定义帮助函数4如下。
mc_pend(rank)
函数mc_pend等待具有相关等级(rank)的单元计算机发送的响应信号。
e.帮助函数5
特定的单元计算机可能需要用于向相同的通信网络(communicationnetwork)上或者进程组(communicator,comm.)内的所有进程发送信号的函数。为此,在本实施例中定义帮助函数5如下。
mc_post_all(comm)
函数mc_post_all向构成给定的进程组(comm)的所有等级(现等级除外)发送信号。
f.帮助函数6
特定的单元计算机可能需要用于从相同的通信网络(communicationnetwork)上或者进程组(communicator,comm.)内的进程接收信号的函数。为此,在本实施例中定义帮助函数6如下。
mc_pend_all(comm)
函数mc_pend_all等待由构成给定的进程组(comm)的所有等级(现等级除外)发送的信号。
g.帮助函数7
可能需要对应各mpi约简运算符(reduceoperator)的函数,本实施例中为此定义帮助函数7如下。
mc_op(op)
函数mc_op对应mpi_max,mpi_min,mpi_sum等的mpi约简运算符而制成。
以下,根据至少一个实施例说明在现有cpu中心型高性能计算机系统的mpi并行程序中转换主要的mpi函数的方法。
iii.mpi的主要函数的说明
以下主要的6个mpi函数的含义如下。
mpi_send(buffer,count,datatype,dest,tag,comm):
mpi_send具有“buffer”,“count”,“datatype”,“dest”,“tag”,“comm”等参数。
根据这些函数,目前进程从作为存储器地址(initialaddress)的“buffer”向等级(rank)为“dest”的目标进程(destinationprocess)传送(count*datatype)字节的消息。此时,可增加用于区分消息的信息标签(tag)。目标进程的等级“dest”表示属于相关进程组(comm.)的进程的等级。如果在执行该mpi函数过程中发生错误,则返回错误代码。
mpi_recv(buffer,count,datatype,source,tag,comm,status)
mpi_recv函数具有“buffer”,“count”,“datatype”,“source”,“tag”,“comm”,“status”等参数。执行所述mpi_recv函数的目前进程在接收等级为“source”的进程发送的消息后,在作为存储器地址的“message”上在(count*datatype)字节的地址上储存。
此时,可使用tag作为区分接收的消息的信息。“source”表示对应进程组“comm.”所属的进程的等级。如果在执行该mpi函数过程中发送错误则返回错误代码。
mpi_bcast(buffer,count,datatype,root,comm)
mpi_bcast函数针对root进程和non-root进程进行不同的操作。目前进程在相关进程组(comm)中为“root”时,向相关进程组“comm”所属的root之外的所有进程,发送自作为存储器地址的“buffer”起(count*datatype)字节的消息。此外,目前进程不为root时,接收“root”进程发送的消息,并在自作为存储器地址的“message”起(count*datatype)字节的地址上储存。如果在执行该mpi函数过程中发送错误则返回错误代码。
mpi_reduce(send_buffer,recv_buffer,count,datatype,operator,root,comm)
目前进程为“root”时,接收进程组“comm.”所属的所有进程发送的消息并执行operator(例如:mpi_max,mpi_min,mpi_sum等)计算后,将其结果储存在“recv_buffer”中。目前进程不为“root”时,将自作为存储器地址的“send_buffer”起(count*datatype)字节的消息向“root”传递。如果在执行该mpi函数过程中发送错误则返回错误代码。
mpi_scatter(send_buffer,send_count,send_datatype,recv_buffer,recv_count,recv_datatype,root,comm)
目前进程为“root”时,向进程组“comm.”所属的“root”之外的所有进程,发送自作为存储器地址的“send_buffer”起(send_count*send_datatype)字节的消息。目前进程不为“root”时,接收“root”发送的消息,并在自作为存储器地址的“recv_buffer”起(recv_count*recv_datatype)字节的地址上储存。如果在执行该mpi函数过程中发送错误则返回错误代码。
mpi_gather(send_buffer,send_count,send_datatype,recv_buffer,recv_count,recv_datatype,root,comm)
目前进程为“root”时,接收进程组“comm.”所属的所有进程发送的消息,并作为排列在自“recv_buffer”起(recv_count*recv_datatype)字节的地址上储存。目前进程不为“root”时,向“root”传递自作为存储器地址的“send_buffer”起(send_count*send_datatype)字节的消息。如果在执行该mpi函数过程中发送错误则返回错误代码。
iv.mpi主要函数的分析(parsing)
本发明中的mpi程序转换方法将转换前面说明的现有主要的6个mpi函数,所述转换中使用作为编译器技术的分析(parsing)及符号执行(symbolicexecution)技术。
在分析mpi函数的过程中,通过符号执行,对调用mpi程序内各mpi函数的执行条件通过分析调用函数mpi_comm_rank时的rank(=mpi逻辑进程号码)引数(argument),并表现为现进程的等级(rank)值(例如:rank==0或者rank>0等),对于上述信息和各mpi函数调用的引数通过使用给定的等级(rank)信息,并判断各mpi函数的调用者是sender或者是receiver。
根据本发明的mpi函数转换(mpi函数调用转换)在调用mpi程序内的各mpi函数的过程中,在源级别上由多字节(size-m)消息转换为固定大小字节(size-1)消息,此时通过使用前面分析的各mpi函数调用的sender与receiver信息来有条件地进行转换。
v.主要的mpi函数的转换
以下,对前面所述的6个主要的mpi函数的转换方法的各种实施例进行说明。
各mpi函数的转换方法如图4至图9所示的流程图。
图4至图9中所示的各流程图图示了当各mpi函数被转换时,转换的程序的执行流程。在转换过程中基于源代码的分析来提取mpi函数及该函数的参数(parameters),并基于利用所述函数及其参数生成的多个命令行生成转换的代码。
<mpi_send函数转换例>
图4根据本发明至少一个实施例图示了mpi函数之一的mpi_send的转换(置换)过程。
如上述例子,具有1列的命令行的原型输入代码根据本发明的方法生成依时间顺序的多列,本实施例中依次生成5列的命令行。
<mpi_recv函数转换例>
图5根据本发明至少一个实施例图示了mpi函数之一的mpi_recv的转换过程。
如上述例文中所示,根据本发明,mpi_recv函数的第2参数作为常数“1”被传递。mpi_recv函数最终接收1字节的mc_buffer。然后,mc_memcpy函数利用所述mc_buffer的地址及大小信息将存储器上的数据储存在“buffer”上。
<mpi_bcast函数转换>
图6根据本发明至少一个实施例图示了mpi函数之一的mpi_bcast的转换过程。
<mpi_reduce函数转换>
图7根据本发明至少一个实施例图示了mpi函数之一的mpi_reduce的转换过程。
<mpi_scatter函数转换>
图8根据本发明至少一个实施例图示了mpi函数之一的mpi_scatter的转换过程。
<mpi_gather函数转换>
图9根据本发明至少一个实施例图示了mpi函数之一的mpi_gather的转换过程。
通过上述实施例,揭示了能够将应用于现有分布式存储器结构的hpc上的mpi程序直接应用于存储器中心型结构的hpc上的mpi程序转换方法及装置。其结果,根据本发明能够将用于分布式存储器结构的hpc而开发的大量的mpi程序无需大的改动便可直接应用于存储器中心型结构的hpc,从而具有巨大的经济性优点。
虽然已在此描述了某些示例性实施例和实施方式,但是根据该描述,其它实施例和修改将是明显的。因此,本发明构思不限于这些实施例,而是限于所附权利要求的更宽范围,并且对于本领域普通技术人员来说,各种显而易见的修改和等同布置将是明显的。
- 还没有人留言评论。精彩留言会获得点赞!