结合GPU-DMM与文本特征的短文本关键词提取方法与流程
本发明涉及短文本关键词提取方法,尤其涉及一种结合gpu-dmm与文本特征的短文本关键词提取方法;具体地说,本发明是结合gpu-dmm主题模型与词语长度、词性序列等文本特征的一种新的短文本关键词提取方法。
背景技术:
随着社交媒体的兴起,短文本己成为网络上信息传递的主要载体。例如微博、朋友圈、网页的标题、搜索片段、电商评论、facebook等网站的主要内容都是以短文本的形式呈现。因此,短文本关键词提取已经成为了短文本信息抽取领域内一个非常重要的研究方向。正如文档摘要在长文本(新闻、博客等)中所起到的作用一致,关键词可以准确的反映出短文本的核心内容,这是人们快速理解文档内容和掌握短文本主题的重要途径。此外,短文本关键词提取在自然语言处理领域的短文本聚类和短文本分类任务中有积极作用,在自动问答,主题跟踪和智能客服等信息检索领域也具有重要的应用价值。
然而,由于短文本句法语义分析复杂,字词歧义丰富,语言表达多样灵活,使得基于短文本的关键词提取异常困难,并存在着主题相关性问题,即很难保证抽取的关键词与短文本主题相关。已有基于主题模型的短文本关键词提取方法大都采用lda模型进行主题识别,以解决短文本和关键词之间的主题相关性问题,从而提高短文本的关键词抽取效果。lda模型在抽取以传统新闻文档为代表的长文本主题时取得了良好的效果,这是因为长文本的文本长度较长,词语共现信息丰富。但是,由于短文本具有长度短、噪音大和词共现信息极度缺乏等特点,直接利用lda进行短文本主题抽取效果较差,从而影响关键词提取效果,这是本发明要解决的关键问题。
技术实现要素:
本发明的目的就在于克服现有技术存在缺点和不足,提供一种结合gpu-dmm与文本特征的短文本关键词提取方法。
本发明的目的是这样实现的:
利用在短文本主题抽取方面效果较好的gpu-dmm模型,并结合tf-idf、词语长度和词性序列,用于短文本关键词的提取,与传统方法比较起来,本发明能够有效的提高短文本关键词提取的效果。
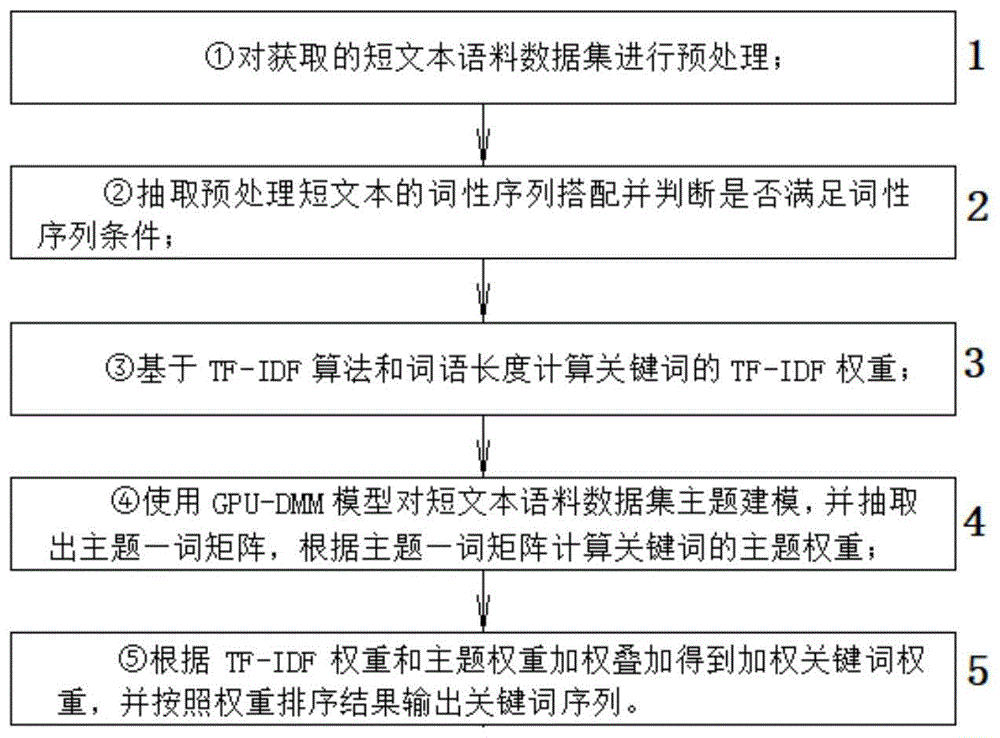
具体地说,本方法包括以下步骤:
①对获取的短文本语料数据集进行预处理;
②抽取预处理短文本的词性序列搭配并判断是否满足词性序列条件;
③基于tf-idf算法和词语长度计算关键词的tf-idf权重;
④使用gpu-dmm模型对短文本语料数据集主题建模,并抽取出主题—词矩阵,根据主题—词矩阵计算关键词的主题权重;
⑤根据tf-idf权重和主题权重加权叠加得到加权关键词权重,并按照权重排序结果输出关键词序列。
本发明具有如下优点和积极效果:
本方法融合了gpu-dmm主题模型与词性序列、词语长度和tf-idf文本特征,可以显著提高关键词提取效果;
实验结果表明,本方法在准确率、召回率和f值三个评价指标上都要优于基准方法。
附图说明
图1是本方法的步骤图;
图2是本发明实施例中与基准方法的准确率、召回率和f值比较示意图。
英译汉
1、gpu-dmm:generalizedpólyaurn-dirichletmultinomialmixture,短文生成模型。
2、lda:latentdirichletallocation,是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。
3、tf-idf:termfrequency–inversedocumentfrequency,是一种在自然语言处理领域常用的加权方法,tf表示词频,idf表示逆文本频率指数。
具体实施方式
下面结合附图和实施例详细说明:
一、方法
如图1,本方法包括下列步骤:
①对获取的短文本语料数据集进行预处理-1
所述的预处理包括分词、词性标注、过滤掉非中文字符和停用词;
②抽取预处理短文本的词性序列搭配并判断是否满足词性序列条件-2
首先判断短文本中是否存在多个名词连接构成的词性序列搭配,根据语料人工标注结果认定当一个短文本是由多个名词连接构成时,当关键词权重与所处位置成反比关系时,输出关键词序列,否则,实施步骤③;
③基于tf-idf算法和词语长度计算关键词的tf-idf权重-3
根据语料人工标注结果,认定在汉语中,一个词语的长度越长,则表示该词所承载的信息量越大,同时该词成为专有名词的可能性就越大,相对于长度较短的词语,其重要性越高;因此,如公式(1)所示,对传统tf-idf算法做出了如下改进:
其中,wttfidf表示词t的tf-idf权重值,len(t)表示词t的长度,nt表示词t在语料数据集中出现的次数,v表示语料数据集中词语的总数,
④使用gpu-dmm模型对短文本语料数据集主题建模,并抽取出主题—词矩阵,根据主题—词矩阵计算关键词的主题权重-4
在使用gpu-dmm模型抽取短文本语料数据集主题时,对于每篇短文本,每次循环迭代的过程中都需要采样出一个主题,其条件概率受到其他短文本的主题标签影响,如公式(2)所示:
其中,zd表示短文本d的主题,-d表示相关变量去除掉短文本d及其所包含的所有词语,mk表示主题为k的短文本数量,α和β表示预先指定的狄利克雷分布的先验参数,k表示主题总数,
如公式(3)所示,主题—词矩阵φ通过点估计进行近似计算:
其中,
⑤根据tf-idf权重和主题权重加权叠加得到加权关键词权重,并按照权重排序结果输出关键词序列-5
如公式(4)所示,在计算得出词t的tf-idf权重和主题权重之后,词t的加权关键词权重wt由tf-idf权重和主题权重加权叠加计算:
wt=λ×wttfidf+(1-λ)×wttopic(4)
其中λ是权重平衡参数;
最后,根据短文本中所有词的加权关键词权重从高到低依次输出关键词序列。
二、实验结果
本方法和基准方法通过实验比较可以验证本方法的高效性。本发明使用20000条搜索引擎查询短文本作为实验所用的数据集,并聘请4名自然语言处理研究方向的硕士研究生标注其中5000条短文本用来评估不同方法的性能。本方法利用搜狗公开数据集89万条查询短文本训练cpu-dmm主题模型,模型的参数设置为:k=2200,α=50/k,β=0.01,λ=0.7。本方法通过准确率、召回率、f值和基准方法tf-idf、lda、textrank比较短文本关键词提取性能。实验结果如图2所示,本发明的实验效果要优于3种基准方法。这是因为本发明综合考虑了gpu-dmm主题模型和文本特征,从而使得关键词提取效果更加精确。
三、声明
应当理解的是,本说明书未详细阐述的部分均属于现有技术。
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!