一种结合BERT模型的图像描述生成方法与流程
本发明涉及一种结合bert模型的图像描述生成方法,属于图像处理技术领域。
背景技术:
图像具有直观、形象的特点,便于人们接受,但随着智能手机及网络技术的发展,网络上有大量的图片产生,庞大的信息使得人们在进行图像检索阅读时花费大量时间。因此,如何通过自动化的方法快速生成图像的描述,并对其进行筛选过滤成为一个迫切需求,图像描述生成技术是一个合理有效的解决方案。此外,生成图像的描述语句还能帮助盲人理解图像内容。
在现有技术中,随着深度学习的发展,图像描述生成技术主要是采用深度学习方法,使用机器来自动生成对图像关键信息的自然语言描述语句,但这些方法由于训练数据集有限,无法涵盖所有领域的图像信息,因此生成的图像描述语句存在词语缺失以及语义信息不足等问题,无法得到很好的效果。
技术实现要素:
为解决上述技术问题,本发明提供了一种结合bert模型的图像描述生成方法,该结合bert模型的图像描述生成方法相对于传统的基于端到端并加入注意力机制的图像描述生成方法,解决了图像描述生成语句语义信息不足的问题,并针对生成语句词汇不足的情况进行了补充,从而能够更准确的描述图像数据的语义含义。
本发明通过以下技术方案得以实现。
本发明提供的一种结合bert模型的图像描述生成方法,首先提取图像的特征向量,对特征向量进行压缩、维度扩充,其次,用外部语料数据扩充词典,然后,将特征向量和词典输入基于端到端加入注意力机制的图像描述生成模型,生成弱语义描述语句a,最后,通过bert模型对弱语义描述语句a进行语义调整,获取完整的图像描述语句。
基于一种结合bert模型的图像描述生成方法,包括以下步骤:
①提取特征向量:采用图像特征提取模型提取出图像的特征向量,并表示成固定维度;
②特征向量压缩、维度扩充:对特征向量进行特征嵌入,将高维度的特征压缩为低维度的特征,然后对维度进行扩充;
③词典扩充:通过外部语料数据对图像描述生成模型所用的词典进行扩充;
④生成式图像描述模型:将特征向量和词典输入基于seq2seq+attention机制的图像描述生成模型,生成弱语义描述语句a;
⑤结合bert模型进行语义调整:通过bert模型的上下文预测功能,对弱语义描述语句a中的语义表达进行调整;
⑥图像描述语句:获取完整的图像描述生成语句。
所述步骤①中,图像特征提取采用resnet50模型,提取出的图像特征维数为2048维。
所述步骤②中,将原有的2048维特征压缩为128维,再运用特征向量扩充得到(none,1,128)的张量。
所述步骤③中,词典扩充采用维基百科各领域文本数据,并用分词后的词语对词典进行扩充。
所述步骤④中,图像描述生成模型由seq2seq+attention机制的编码器和基于lstm的解码器组成,并采用attention机制来增大重要信息权重。
所述步骤③分为以下步骤:
(3.1)采集各领域的维基百科文本数据;
(3.2)对文本数据进行分词,去除停用词处理;
(3.3)将分完词的词语加入到词典中,去除重复词语,并对每个词语进行编号;
(3.4)完成词典扩充。
采用embedding方式将原始提取的2048维图像特征向量压缩为128维。
所述步骤④分为以下步骤:
(4.1)将特征向量和词典输入seq2seq+attention机制的编码器,作为输出向量;
(4.2)在第一时刻输入步骤(4.1)中的输出向量,之后每个时刻输入的数据由前一时刻的输出组成,再通过单向lstm解码器,获取弱语义描述语句a。
所述步骤⑤分为以下步骤:
(5.1)通过bert模型判断弱语义描述语句a中,词语的词性;
(5.2)若词性为动词,将当前词语所在的语句输入bert模型中,预测接下来的词语,描述生成的词语采用bert模型预测的词语;
(5.3)若词性为非动词,描述生成的词语采用解码器输出的词语;
(5.4)循环执行(5.1)~(5.3),获取完整的图像描述生成语句。
本发明的有益效果在于:通过图像特征提取模型提取出图像数据的特征向量,对特征向量进行压缩与维度扩充,增强图像数据的特征表达含义;利用基于端到端并加入注意力机制的图像描述生成模型生成弱语义图像描述语句,同时对于词汇不足的问题采用应用外部语料数据扩充词典的方式;结合bert模型对弱语义图像描述语句进行语义调整,增强语义含义,使所生成的图像描述能更准确的表征图像的内容,具有更丰富的语义。
附图说明
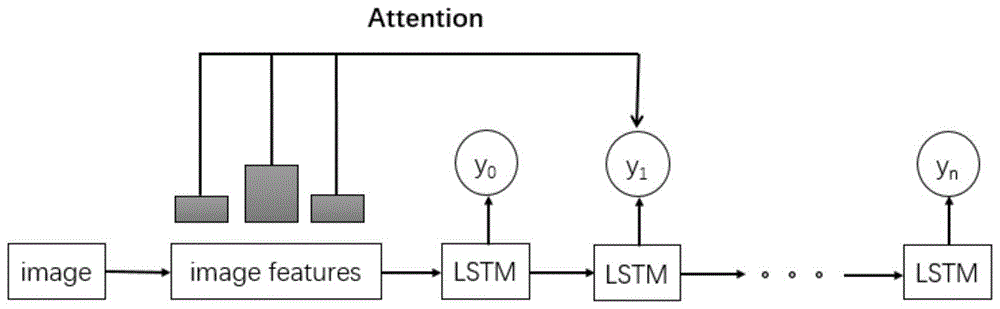
图1是本发明编码器、解码器以及图像描述生成模型的结构示意图;
图2是本发明的流程图。
具体实施方式
下面进一步描述本发明的技术方案,但要求保护的范围并不局限于所述。
如图1和2所示,一种结合bert模型的图像描述生成方法,首先提取图像的特征向量,对特征向量进行压缩、维度扩充,其次,用外部语料数据扩充词典,然后,将特征向量和词典输入基于端到端加入注意力机制的图像描述生成模型,生成弱语义描述语句a,最后,通过bert模型对弱语义描述语句a进行语义调整,获取完整的图像描述语句。
基于一种结合bert模型的图像描述生成方法,包括以下步骤:
①提取特征向量:采用图像特征提取模型提取出图像的特征向量,并表示成固定维度;
进一步地,图像特征提取采用resnet50模型,提取出的图像特征维数为2048维;
②特征向量压缩、维度扩充:对特征向量进行特征嵌入,将高维度的特征压缩为低维度的特征,然后对维度进行扩充;
进一步地,将原有的2048维特征压缩为128维,再运用特征向量扩充得到(none,1,128)的张量;
优选的,采用embedding方式将原始提取的2048维图像特征向量压缩为128维;
③词典扩充:通过外部语料数据对图像描述生成模型所用的词典进行扩充;
优选的,词典扩充采用维基百科各领域文本数据,并用分词后的词语对词典进行扩充;
具体分为以下步骤:
(3.1)采集各领域的维基百科文本数据;
(3.2)对文本数据进行分词,去除停用词处理;
(3.3)将分完词的词语加入到词典中,去除重复词语,并对每个词语进行编号;
(3.4)完成词典扩充;
④生成式图像描述模型:将特征向量和词典输入基于seq2seq+attention机制的图像描述生成模型,生成弱语义描述语句a;
进一步地,图像描述生成模型由seq2seq+attention机制的编码器和基于lstm的解码器组成,并采用attention机制来增大重要信息权重;
具体的,分为以下步骤:
(4.1)将特征向量和词典输入seq2seq+attention机制的编码器,作为输出向量;
(4.2)在第一时刻输入步骤(4.1)中的输出向量,之后每个时刻输入的数据由前一时刻的输出组成,再通过单向lstm解码器,获取弱语义描述语句a;
⑤结合bert模型进行语义调整:通过bert模型的上下文预测功能,对弱语义描述语句a中的语义表达进行调整;
具体的,分为以下步骤:
(5.1)通过bert模型判断弱语义描述语句a中,词语的词性;
(5.2)若词性为动词,将当前词语所在的语句输入bert模型中,预测接下来的词语,描述生成的词语采用bert模型预测的词语;
(5.3)若词性为非动词,描述生成的词语采用解码器输出的词语;
(5.4)循环执行(5.1)~(5.3),获取完整的图像描述生成语句;
⑥图像描述语句:获取完整的图像描述生成语句。
实施例
如上所述,一种结合bert模型的图像描述生成方法,首先输入图像(image)数据,提取图像的特征向量,对特征向量进行压缩、维度扩充,应用外部语料数据扩充词典,解决生成语句词汇不足问题,然后采用基于端到端并加入注意力机制的图像描述生成模型(imagefeatures)初步生成弱语义描述语句a,并结合bert模型对生成的语句a进行语义调整,增强语义含义,最后得到完整的图像描述语句。
具体包括以下步骤:
①提取特征向量:采用图像特征提取模型提取出图像的特征向量,并表示成固定维度;
②特征向量压缩、维度扩充:对特征向量进行特征嵌入,将高维度的特征压缩为低维度的特征,同时将维度扩充为合适的大小,以满足基于端到端结合注意力机制的图像描述生成模型的输入;
③词典扩充:应用外部语料对图像描述生成模型所用的词典进行扩充,增加词典种词语的数量与领域范围;
④生成式图像描述模型:将压缩、维度扩充后的图像特征向量输入基于seq2seq+attention机制的图像描述生成模型,生成弱语义的图像描述语句a;
⑤结合bert模型进行语义调整:对弱语义的图像描述语句a,通过bert模型的上下文预测功能,对a中的语义表达进行调整,使图像描述语句更加具有逻辑性与语义相关性;
⑥图像描述语句:将步骤⑤中语义调整后的图像描述语句作为最终的图像描述生成语句。
进一步地,所述步骤①中,图像特征提取采用resnet50模型,提取出的图像特征维数为2048维。
进一步地,所述步骤②中,特征向量压缩将原有的2048维特征压缩为128维,再运用特征向量扩充得到(none,1,128)的张量。
进一步地,所述步骤③中,词典扩充采用维基百科各领域文本数据,并用分词后的词语对词典进行扩充。
进一步地,所述步骤④中,生成式图像描述模型采用基于seq2seq+attention机制的方法生成图像描述语句。
进一步地,所述生成式图像描述模型由编码器和基于lstm的解码器组成,并采用attention机制来增大重要信息权重。
进一步地,所述步骤⑤中,结合bert模型对生成的弱语义语句进行语义调整,通过上下文关联,替换不合逻辑词语,增强语句的语义相关性。
进一步地,所述步骤②分为以下步骤:
(2.1)采用embedding方式将原始提取的2048维图像特征向量压缩为128维;
(2.2)将压缩后的特征向量扩充为(none,1,128)的特征张量;
进一步地,所述步骤③分为以下步骤:
(3.1)采集各领域的维基百科文本数据;
(3.2)对文本数据进行分词,去除停用词处理;
(3.3)将分完词的词语加入到词典中,去除重复词语,并对每个词语进行编号;
进一步地,所述步骤④分为以下步骤:
(4.1)采用步骤①及步骤②的方法对图像数据进行特征提取,作为seq2seq+attention机制的编码器输出向量;
(4.2)解码器采用单向lstm网络模型,在第一时刻输入步骤(4.1)中得到的特征向量,之后每个时刻输入的数据由前一时刻的输出组成(组成为图像描述语句序列yn),然后由lstm输出弱语义的图像描述语句;
进一步地,所述步骤⑤分为以下步骤:
(5.1)对步骤(4.2)每个时刻生成词语,判断其词性;
(5.2)若词性为动词,则将当前词语所在的语句输入bert模型中,预测接下来的词语,描述生成的词语采用bert模型预测的词语;
(5.3)若词性为非动词,描述生成的词语采用解码器输出的词语;
(5.4)循环执行(5.1)~(5.3),最后生成完整的图像描述语句。
综上所述,本发明针对传统基于深度学习的图像描述生成模型所生成的描述语句语义信息不足问题,通过将bert模型与基于深度学习的图像描述生成方法相结合,对弱语义图像描述语句进行语义调整,增强语义含义,使用图像特征提取模型提取出图像数据的特征向量,对特征向量进行压缩与维度扩充,增强图像数据的特征表达含义,同时对于词汇不足的问题,采用应用外部语料数据扩充词典的方式,解决词汇不足问题,得到语义含义更丰富,描述更准确的图像描述语句。
- 还没有人留言评论。精彩留言会获得点赞!