一种汉语选词填空方法与流程
本发明属于计算机领域,具体涉及一种汉语选词填空方法。
背景技术:
本发明主要解决的技术问题和应用需求有两方面。其一是让计算机参加高考语文答题的部分试题求解,针对高考语文中选词填空试题。正确使用词语是每年高考的一个必考点,其考查范围包括两个层面:一是正确理解词语,二是正确使用词语。即理解词语在具体语境中的意义,根据语境使用词语。
其二是辅助汉语初学者进行词语使用练习,包括中小学生的汉语选词填空练习和对外汉语教学中的词语使用练习,这些主要涉及同义词或形近词在汉语句子中的使用。
从检索查阅的学术论文、专利、论著来看,还没有汉语自动选词填空的相关技术和方法的公开发表。因此,一种汉语选词填空方法亟待提出。
技术实现要素:
为解决让计算机自动选词填空问题,本发明提供一种汉语选词填空方法。
为了解决上述技术问题,本发明提供了如下的技术方案:
本发明提供一种汉语选词填空方法,包括以下步骤:
s1、从一给定的训练语料中获得词语特征及其出现的频次;
s2、切分要进行汉语填空的汉语句子:将待填空的汉语句子切分为词语序列;
s3、计算比较待填空的汉语句子所对应的词语序列条件下空白处填写每个候选词语的条件概率;
s4、根据计算比较每个候选词语填入空白处的条件概率大小确定用于填空的汉语词语;
s5、输出填空的汉语词语结果。
作为本发明的一种优选技术方案,步骤s1包括:设定样本窗口大小,并选定特征模板集,从一给定的训练语料中按照设定的样本窗口大小通过特征模板集扩展出上下文词语特征,统计求取上下文词语特征及其频次,训练语料是经过汉语分词后的汉语语料。
作为本发明的一种优选技术方案,步骤s2将待填空的汉语句子切分为词语序列w1w2……wn。
作为本发明的一种优选技术方案,对每个候选词语,计算待填空的汉语句子s所对应的词语序列条件下空白处填写该候选词语的条件概率;
一个句子具有很多特征,把它的众多特征看作一个向量,即f=(f1,f2,f3,……,fn),用f这个向量来表征这个句子;这样,条件概率的计算公式为:
直接计算条件概率p(w0|f)比较困难,而概率p(w0),p(f|w0)可以从训练数据集中求得;根据公式(1)将后验概率p(w0|f)的求解转换为先验概率p(w0),p(f|w0)的求解;又由于假设上下文特征f向量中的各特征相互独立,所以
由于p(f)对于所有不同的候选词语都相同,显然
其中,w是候选词语集合,w0表示当前词,在待填空的句子中就是待填入的词语,也就是句子的空白处;假设上下文特征f向量中的各特征相互独立,则有:
而概率p(w0),p(w-2|w0),……,p(w1w2|w0)可以通过步骤s1从训练语料中得到的上下文词语特征及频次求得;
计算过程中由于数据稀疏现象,采用good-turing估计进行数据平滑处理;
最终,选择条件概率最大的词语作为填入汉语句子空白处的词语。
本发明的有益效果是:本发明将汉语自动选词填空采用概率统计的方法实现,计算简单、运算量小、选词填空准确率较高。
附图说明
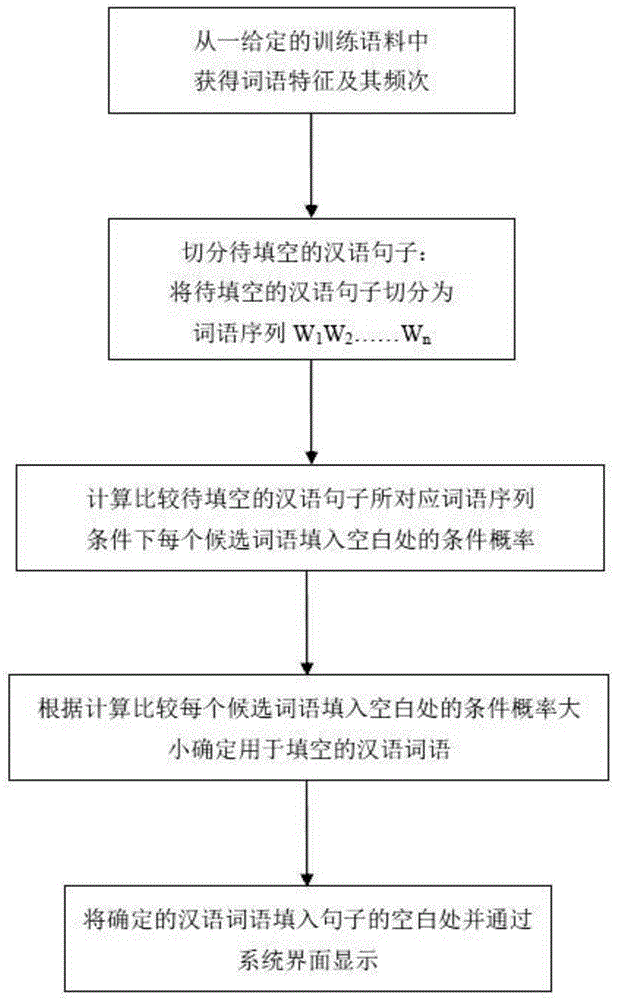
图1是本发明一种汉语选词填空方法的工作流程图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
为了达到本发明的目的,如图1所示,在本发明的其中一种实施方式中提供一种汉语选词填空方法,包括以下步骤:
s1、从一给定的训练语料中获得词语特征及其出现的频次;
s2、切分要进行汉语填空的汉语句子:将待填空的汉语句子切分为词语序列;
s3、计算比较待填空的汉语句子所对应的词语序列条件下空白处填写每个候选词语的条件概率;
s4、根据计算比较每个候选词语填入空白处的条件概率大小确定用于填空的汉语词语;
s5、输出填空的汉语词语结果。
具体的,步骤s1包括:设定样本窗口大小,并选定特征模板集,从一给定的训练语料中按照设定的样本窗口大小通过特征模板集扩展出上下文词语特征,统计求取上下文词语特征及其频次,训练语料是经过汉语分词后的汉语语料。
其中,特征选择的关键在于根据具体的任务选择合适的词语特征,包括选取上下文范围和设定特征模板集,也就是样本窗口大小设定和特征模板集的选定。
通常情况下,上下文的选取是基于当前词左右一定范围进行的,这个固定的范围被称为窗口;窗口中的上下文实质是一个特定样本,所以将该窗口称为样本窗口;可以限定样本窗口是“5词窗口”,即使用当前词前后各两个词作为上下文,也可以限定样本窗口是“7词窗口”,即使用当前词前后各三个词作为上下文。本发明采用“5词窗口”作为样本窗口。
特征模板集是特征模板的集合,特征模板的主要功能是定义上下文中某些特定位置的语言成分或信息与某类待预测事件的关联情况。由于本发明是根据一个汉语句子中空白处的上下文来确定该空的应填词语,因此就由该空前后出现的词、词的组合信息及这些信息出现的位置来确定上下文词语特征。习惯上,特征模板可以看作是对一组上下文词语特征按照共同的属性进行的抽象;
在5词样本窗口下,可以将上下文特征按照特征模板中出现的词与当前词的距离属性进行抽象。如果限定样本窗口是5词窗口,则这一具体任务的上下文词语特征是指当前词本身、以及当前词前后各两个词及其词语组合所组成的特征。将5词样本窗口下常见上下文词语特征抽象为8类,分别是:w0,w-2w0,w-1w0,w0w1,w0w2,w-2w-1w0,w-1w0w1,w0w1w2,记这些特征模板构成的特征模板集为tmpt-8,这8个特征模板的含义如表1所示。其中,模板中的wn代表当前词和当前词相距若干位的词。例如,w0表示当前词,w1表示当前词的后一个词,w-1表示当前词的前一个词,依此类推。
表1为tmpt-8中特征模板列表
具体的,步骤s2将待填空的汉语句子切分为词语序列w1w2……wn。
具体的,对每个候选词语,计算待填空的汉语句子s所对应的词语序列条件下空白处填写该候选词语的条件概率;
一个句子具有很多特征,把它的众多特征看作一个向量,即f=(f1,f2,f3,……,fn),用f这个向量来表征这个句子;这样,条件概率的计算公式为:
直接计算条件概率p(w0|f)比较困难,而概率p(w0),p(f|w0)可以从训练数据集中求得;根据公式(1)将后验概率p(w0|f)的求解转换为先验概率p(w0),p(f|w0)的求解;又由于假设上下文特征f向量中的各特征相互独立,所以
由于p(f)对于所有不同的候选词语都相同,显然
其中,w是候选词语集合,w0表示当前词,在待填空的句子中就是待填入的词语,也就是句子的空白处;假设上下文特征f向量中的各特征相互独立,则有:
而概率p(w0),p(w-2|w0),……,p(w1w2|w0)可以通过步骤s1从训练语料中得到的上下文词语特征及频次求得;
计算过程中由于数据稀疏现象,采用good-turing估计进行数据平滑处理;
最终,选择条件概率最大的词语作为填入汉语句子空白处的词语。
下面举例说明本发明:
如下示例是一道中小学选词填空练习题,候选词有两个:“爱惜”和“珍惜”,需要根据给出的汉语句子分别将两个候选词填入两个空白处。
1.他从小就养成了()书籍的好习惯。
2.我们应该()时间,不能随便浪费时间。
根据步骤s2将要进行汉语填空的汉语句子首先分词,即将待填空的汉语句子切分为词语序列,如下所示:
1.他从小就养成了()书籍的好习惯。
2.我们应该()时间,不能随便浪费时间。
根据步骤s3对每个待填空的汉语句子计算比较所对应的词语序列条件下空白处填写每个候选词语的条件概率,取条件概率大的候选词语填入该句子的空白处。在步骤s3中要使用步骤s1从训练语料中统计的上下文特征结果。
对该例子计算比较条件概率大小,选词填空过程如下:
待填空的汉语句子1和句子2有两个候选填空词语:“爱惜”和“珍惜”,根据前面的分析知道对每个句子都需要计算比较空白处填入“爱惜”或“珍惜”的条件概率大小,即计算比较p(w0为爱惜|f)和p(w0为珍惜|f)两个条件概率大小。也就是根据空白处的前后两个词语最终确定最可能的填入词语,我们以句子2为例计算比较。
2.我们应该()时间,不能随便浪费时间。
句子2中上下文“5词窗口”:(w-2,w-1,w0,w1,w2)是(我们,应该,__,时间,,),注意在句子2中词语w2对应的是“逗号,”,计算过程中标点符号也看作一个词语。这样,表征待填空汉语句子的上下文特征就是向量f=(w-2,w-1,w1,w2,w-2w-1,w-1w1,w1w2),即向量f为(我们,应该,时间,,,我们应该,应该时间,时间,)。
根据公式(3)和公式(4),要计算比较p(w0为爱惜|f)和p(w0为珍惜|f)两个条件概率大小,只需要将相应的上下文词语特征及频次代入公式(1)中右边分子p(w0)p(f|w0)比较大小即可,也就是比较下面两个式子的大小。
p(w0为爱惜)p(w-2为我们|w0为爱惜)p(w-1为应该|w0为爱惜)......p(w1w2为时间,|w0为爱惜)(7)
p(w0为珍惜)p(w-2为我们|w0为珍惜)p(w-1为应该|w0为珍惜)......p(w1w2为时间,|w0为珍惜)(8)
而两个式子中的概率值可以通过公式(5)和公式(6)求得,
例如,条件概率值p(w-1为应该|w0为珍惜)的求解需要从步骤s1中得到的训练语料中“‘应该珍惜’的同现次数”除以训练语料中“‘珍惜’出现次数”,其实也就是训练语料中根据“5词窗口”逐词滑动得到的所有样本中,“当前词为‘珍惜’,且其前一个词为‘应该’的样本数”除以“当前词为‘珍惜’的样本数”。假如在训练语料中有1000个“当前词为‘珍惜’”的样本,而这1000个样本中又有50个“当前词的前一个词为‘应该’”样本。则条件概率
这样,我们就可以求出式子(7)和(8)的值,假如式子(8)的值大,则p(w0为珍惜|f)>p(w0为爱惜|f),所以选择条件概率值大的词语“珍惜”作为填入汉语句子空白处的词语。即:
2.我们应该(珍惜)时间,不能随便浪费时间。
同样,对于句子1应选择条件概率值大的词语“爱惜”作为填入汉语句子空白处的词语。即:
1.他从小就养成了(爱惜)书籍的好习惯。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!