一种克服遮挡效应的驾驶场景双目深度估计方法与流程
本发明涉及机器视觉和自动驾驶领域,具体涉及一种克服遮挡效应利用自监督深度学习技术的驾驶场景双目深度估计方法。
背景技术:
随着人工智能技术的进步,自动驾驶得到了学术界和工业界的广泛研究,双目深度估计作为自动驾驶技术中一个重要部分,一直是研究热点。双目深度估计基于双目相机,拍摄左右两幅视图,从左右两幅视图得到对应的视差图,然后根据双目相机参数计算深度图像。
传统的双目深度估计采用立体匹配的方法,在左右两幅视图中寻找匹配的对应点。但是由于遮挡效应的存在,即左视图中出现的区域在右视图中被其它区域遮挡(或者右视图中出现的区域在左视图中被其它区域遮挡),会导致左右视图中出现无对应匹配的区域,也就是遮挡区域。这些遮挡区域无法估计深度,导致对应的深度图像出现空洞。并且遮挡区域还会影响非遮挡区域的估计精度。因此立体匹配的方法难以在驾驶场景下使用。
近年来,深度神经网络与立体匹配的结合使得双目深度估计的精度得到的极大提高。但是深度神经网络是一种有监督学习技术,需要大量带有标注的数据训练网络。然而,获取大量真实场景下的深度信息是极为困难的,并且成本高昂。现阶段可以利用双目相机系统的几何约束,通过神经网络输入的左(右)视图和输出的右(左)视差图,重建右(左)视图,将输入的左(右)视图和重建的左(右)视图的差异作为自监督信号,以此来训练网络模型。这种自监督训练机制虽然可以免去采集真实场景深度信息的麻烦,但是由于遮挡效应的存在,重建的视图是不可能和原始视图完全一致的,这会导致全局的精度下降。采取自监督方式训练的网络模型比有监督方式训练的网络模型精度会差很多。
技术实现要素:
为解决上述背景技术中存在的问题,本发明实例提出一种克服遮挡效应利用自监督深度学习技术的驾驶场景双目深度估计方法。该实例包含一种具有灵活的特征交互能力的神经网络设计架构,和一种能克服遮挡效应的自监督神经网络训练机制。
本发明在利用神经网络输入的左(右)视图和输出的右(左)视差图重建右(左)视图的同时,生成左(右)遮挡掩码图。遮挡掩码图每一点的取值为0或1,mi,j∈{0,1}。若左(右)遮挡掩码图中,某一点mi,j=0,表示左(右)视图中(i,j)该点在右(左)视图中存在对应的匹配点;若左(右)遮挡掩码图中,某一点mi,j≠0,表示左(右)视图中(i,j)该点在右(左)视图中不存在对应的匹配点。遮挡掩码图m中取值为0的部分即为被遮挡的区域,在训练网络优化损失函数时,去除遮挡区域的影响。
本发明的技术方案包含以下步骤:
步骤s1,构建图像数据集,所述数据集中的每一个样本包含一对,即左右2幅驾驶场景图像,不需要采集场景深度信息作为标注数据;
步骤s2,构建神经网络模型,该模型包括特征提取模块、代价创建模块、代价计算模块和视差回归模块;
步骤s3,构建一种克服遮挡效应的自监督训练方法:使用s1构建的图像数据集对步骤s2构建的神经网络模型进行自监督训练,具体为:
利用双目相机的左(右)片估计右(左)片视差图,并结合基线距离计算得到右片和左片视图,同时预测遮挡区域,利用原始的左片和右片图像作为真值,结合遮挡区域掩码图构建损失函数,对网络进行训练;
步骤s4,利用步骤s3训练好的模型进行深度估计。
进一步地,上述步骤s1所述数据集中的每一个样本包含一对(左右两幅)驾驶场景视图。构建图像数据集的步骤具体如下:
步骤s1-1,将2台摄像机固定在车辆上方组成双目摄像系统,保证2台摄像机镜头处于同一平面水平对齐,且镜头光心基线距离为b,焦距为f。
步骤s1-2,在车辆行驶时,使用步骤s1-1所述双目摄像系统以均匀时间间隔同时拍摄场景,在城市道路、乡村道路、居住区域、郊野区域等多种场景下拍摄,采集得到2m幅驾驶场景图像;
步骤s1-3,通过s1-2采集得到m个图像对,每个图像对包含左视图和右视图2幅图像,将每对图像对的左视图和右视图校准,保证水平对齐,减少垂直方向偏差。
步骤s1-4,经过上面三步的处理,得到m个数据样本,每个数据样本包含2幅图像(左视图和右视图),本方法不需要额外采集深度信息作为标注;将m个数据样本作为图像数据集。
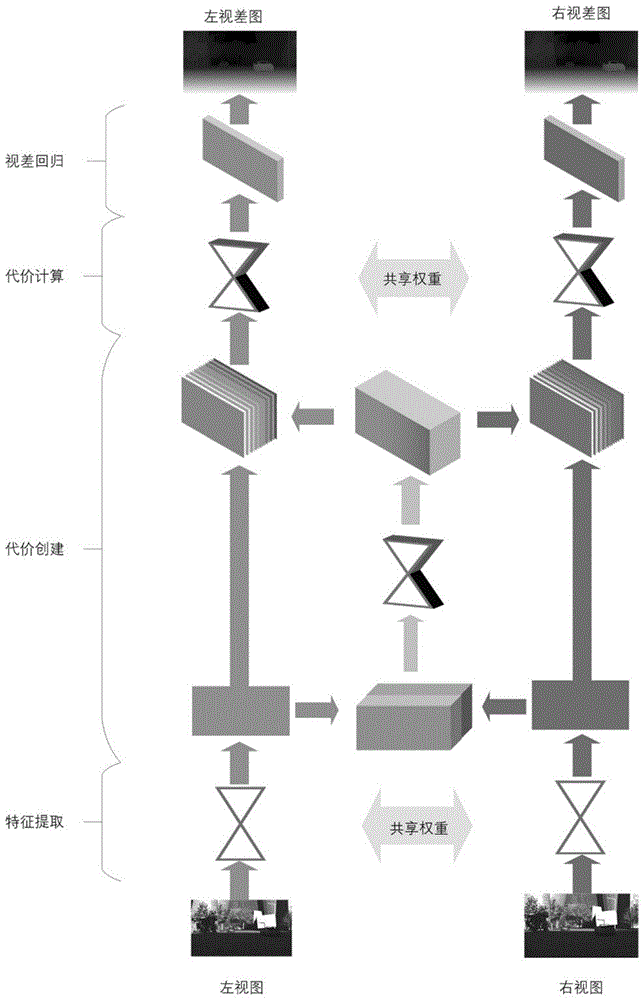
进一步地,上述步骤s2所述神经网络模型包括特征提取模块、代价创建模块、代价计算模块和视差回归模块4个组成部分。本发明所设计的神经网络架构如图1所示。
特征提取模块是2d全卷积网络,输入左右视图(h×w×3),输出左右视图的特征图fr1和fl1
代价创建模块将特征提取模块输出的左右视图的特征图
将左右特征图
将融合特征图
将融合特征图
将融合特征图
将融合特征图
将特征图a2
将左特征图fl1
将右特征图fr1
代价计算模块是多尺度3d全卷积网络,包括3d卷积层和3d反卷积层,它输入左右特征体costvolume
视差回归模块输入左右代价特征计算结果costresult(d×h×w×1,降维到d×h×w),输出左右视图对应的视差图(h×w)。计算方式如下:
这里,σ(·)表示二维softmax函数,cd表示三维特征体(d×h×w)上d维索引为d的二维数据(h×w)。
进一步地,使用s1构建的图像数据集对步骤s2构建的神经网络模型进行自监督训练方法如下:如图2所示,神经网络模型输入左右两幅图像il和ir,输出左右视差图dl和dr,使用dl和ir得到重建出的左视差图
右视差图
使用il、
loss=cl+cr
其中,α表示平衡系数。
上述步骤4通过步骤3获得的神经网络模型工作,输入左右视图,输出左右视差图,最终通过双目相机系统参数将左右视差图转换为左右深度图像。
本发明还设计了一种电子设备,其特殊之处在于,包括:
一个或多个处理器;
存储装置,用于存储一个或多个程序;
当一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现上述任一所述的方法。
基于同一个设计理念,本发明还设计了一种计算机可读介质,其上存储有计算机程序,其特征在于:所述程序被处理器执行时实现上述任一所述的方法。
本发明的优点:
1.本发明设计了一种新型的端到端的神经网络模型,它由特征提取模块、代价创建模块、代价计算模块和视差回归模块组成。其中代价创建模块我们使用了多尺度n×1卷积,具有很强的水平方向先验性和灵活的自适应性,能更加准确的处理左右视图信息的融合交互。
2.本发明创新地提出一种能有效克服遮挡效应的自监督神经网络训练机制。先前的自监督训练方法无法处理视图中出现的遮挡情况,导致估计的深度图像模糊不准。本实例所提出的自监督训练机制,无需人工标注场景深度信息,能有效处理遮挡效应,提高场景深度的估计精度。并且,利用所提出的训练方法,可以在线学习,增强网络在不同驾驶场景条件的鲁棒性。
附图说明
图1是本发明实例的神经网络模型架构图。
图2是本发明实例的自监督训练神经网络模型的示意图。
图3是本发明的工作流程图。
具体实施方式
为使本发明实施方式的目的、技术方案和和特点说明更加清楚,下面结合本发明的附图,对本发明实施方式中的技术方案进行清晰、完整地描述。显然,所描述的实施方式是本发明实施方法中的一部分,而不是全部。本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施方式,都属于本发明保护的范围。因此,以下对在本发明附图中所提供的消息描述并非旨在限制要求本发明的保护范围,而是仅仅表示本发明的选定实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施方式,都属于本发明保护的范围。
本发明提供的方法设计了一种新型的神经网络模型,并提出了一种克服遮挡效应的的自监督训练机制。神经网络模型总体架构参见图1,自监督训练方法参见图2。其具体实施流程图参见图3,包含以下步骤。
步骤s1,构建图像数据集,所述数据集中的每一个样本包含一对(左右2幅)驾驶场景图像。具体实施过程说明如下。
步骤s1-1,将2台摄像机固定在车辆上方组成双目摄像系统,保证2台摄像机镜头处于同一平面,且镜头光心基线距离为b,焦距为f。
步骤s1-2,在车辆行驶时,使用步骤s1-1所述双目摄像系统以均匀时间间隔同时拍摄场景,在城市道路、乡村道路、居住区域、郊野区域等多种场景下拍摄,采集得到2m幅驾驶场景图像;
步骤s1-3,通过s1-2采集得到m个图像对,每个图像对包含左视图和右视图2幅图像,将每对图像对的左视图和右视图校准,保证水平对齐,减少垂直方向偏差。
步骤s1-4,经过上面三步的处理,得到m个数据样本,没个数据样本包含2幅图像(左视图和右视图),本方法不需要额外采集深度信息作为标注;将m个数据样本作为图像数据集。
优选地,取m=50000,则每个样本为{il,ir},数据集为
步骤s2,构建深度学习网络模型,如附图1。该模型包括特征提取模块、代价创建模块、代价计算模块和视差回归模块。具体实施过程说明如下。
s2-1,特征提取模块是2d全卷积网络,输入左右视图(h×w×3),输出左右视图的特征图fr1和fl1
特征提取模块具体结构为:第1层为卷积层,输入左右视图2幅图像(h×w×3),卷积核大小为5×5,步长为2,卷积核个数是32;第2到17层为残差结构卷积块构成,每个残差块有2个卷积层,每层卷积核大小为3×3,步长为1,卷积核个数是32,每个残差块的输入经过跳层连接到残差块的输出,总共8个相同的残差块;第18层为卷积层,没有激活函数和batchnorm,卷积核大小为3×3,步长为1,卷积核个数是32,得到左右视图对应的特征图fr1和fl1
s2-2,将上一步得到的左右视图的特征图fr1和fl1
将左右特征图
将融合特征图
将融合特征图
将融合特征图
将融合特征图
将特征图a2
将左特征图fl1
将右特征图fr1
s2-3,将上一步得到的代价特征体costvolume
代价计算模块包含19层:第1层为3d卷积,输入代价特征体,卷积核大小为3×3×3,步长为1,卷积核个数为32;第2层为3d卷积层,输入第2层输出,卷积核大小为3×3×3,步长为1,卷积核个数为32;第3层为3d卷积层,输入代价特征体,卷积核大小为3×3×3,步长为2,卷积核个数为64;第4层为3d卷积层,输入第3层输出,卷积核大小为3×3×3,步长为1,卷积核个数为64;第5层为3d卷积层,输入第4层输出,卷积核个数为3×3×3,步长为1,卷积核个数为64;第6层为3d卷积层,输入为第3层输出,卷积核大小为3×3×3,步长为2,卷积核个数为64,;第7层为3d卷积层,输入为第6层输出,卷积核大小为3×3×3,步长为1,卷积核个数为64;第8层为3d卷积层,输入为第7层输出,卷积核大小为3×3×3,步长为1,卷积核个数为64,;第9层为3d卷积层,输入为第6层输出,卷积核大小为3×3×3,步长为2,卷积核个数为64;第10层为3d卷积层,输入为第9层输出,卷积核大小为3×3×3,步长为1,卷积核个数为64;第11层为3d卷积层,输入为第10层的输出,卷积核大小为3×3×3,步长为1,卷积核个数为64;第12层为3d卷积层,输入为第9层的输入,卷积核大小为3×3×3,步长为2,卷积核个数为128;第13层为3d卷积层,输入为第12层的输出,卷积核大小为3×3×3步长为1,卷积核个数为128;第14层为3d卷积层,输入为第13层的输出,卷积核大小为3×3×3,步长为1,卷积核个数为128;第15层为3d反卷积层,输入为第14层的输出,卷积核大小为3×3×3,步长为2,卷积核个数为64;第16层为3d反卷积层,输入为第15层和第11层的输出的残差和,卷积核大小为3×3×3,步长为2,卷积核个数为64;第17层为3d反卷积,输入为第16层和第8层输出的残差和,卷积核大小为3×3×3,步长为2,卷积核个数为64;第18层为3d反卷积,输入为第17层和第5层输出的残差和,卷积核大小为3×3×3,步长为2,卷积核个数为32;第19层为3d反卷积层,输入为第18层和第2层输出的残差和,卷积核大小为3×3×3,步长为2,卷积核个数为1,输出左右视图对应的代价特征计算结果costresult(d×h×w×1)。
优选地,代价计算模块第1层至第18层使用激活函数和batchnorm,第19层不使用激活函数和batchnorm。
s2-4,将上一步得到的左右视图对应的代价特征计算结果costresult(d×h×w×1,降维到d×h×w)输入视差回归模块,得到左右视图对应的视差图(h×w)。计算方式如下:
这里,σ(·)表示二维softmax函数,cd表示三维特征体(d×h×w)上d维索引为d的二维数据(h×w)。
步骤s3,所述使用s1构建的图像数据集对步骤s2构建的神经网络模型进行自监督训练方法,详细说明如下。
神经网络模型输入左右两幅图像il和ir,输出左右视差图dl和dr,使用dl和ir得到重建出的左视差图
使用il、
loss=cl+cr
其中,α表示平衡系数。
步骤s4,利用步骤s3训练好的深度学习模型,输入的左右两视图的驾驶场景图像,得到左右两视图对应的视差图。通过如下公式,可以得到左右视图像素点到摄像机平面的距离z:
这里,b表示双目摄像系统的基线距离,f表示双目摄像系统的焦距。
本发明还设计了一种电子设备,其特殊之处在于,包括:
一个或多个处理器;
存储装置,用于存储一个或多个程序;
当一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现上述任一所述的方法。
基于同一个设计理念,本发明还设计了一种计算机可读介质,其上存储有计算机程序,其特征在于:所述程序被处理器执行时实现上述任一所述的方法。
本发明的优点:
1.本发明设计了一种新型的端到端的神经网络模型,它由特征提取模块、代价创建模块、代价计算模块和视差回归模块组成。其中代价创建模块我们使用了多尺度n×1卷积,具有很强的水平方向先验性和灵活的自适应性,能更加准确的处理左右视图信息的融合交互。
2.本发明创新地提出一种能有效克服遮挡效应的自监督神经网络训练机制。先前的自监督训练方法无法处理视图中出现的遮挡情况,导致估计的深度图像模糊不准。本实例所提出的自监督训练机制,无需人工标注场景深度信息,能有效处理遮挡效应,提高场景深度的估计精度。并且,利用所提出的训练方法,可以在线学习,增强网络在不同驾驶场景条件的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!