一种留言信息的输出方法及智能音箱、存储介质与流程
本发明涉及智能音箱技术领域,具体涉及一种留言信息的输出方法及智能音箱、存储介质。
背景技术:
音箱是人们日常生活中常用的音频播放设备,近年来随着技术的发展逐渐趋向智能化。目前的智能音箱可具有留言箱功能,用于在用户查看留言箱时播放留言箱中提前录制或者从关联应用程序接收到的语音留言信息。实践中发现,这种留言方式往往需要用户主动查看,容易出现留言信息被遗漏的情况。
技术实现要素:
本申请实施例公开了一种留言信息的输出方法及智能音箱、存储介质,能够解决留言信息容易被遗漏的问题。
本申请实施例第一方面公开一种留言信息的输出方法,所述方法包括:
当进入留言模式时,获取留言信息和触发条件信息;所述触发条件信息包括用户信息和场景信息;
当检测到有人靠近时,判断是否识别出与所述用户信息相匹配的目标用户;
若识别出所述目标用户,获取第一场景,并判断所述第一场景是否与所述场景信息对应的目标场景相匹配;
若所述第一场景与所述目标场景相匹配,输出所述留言信息。
作为一种可选的实施方式,在本申请实施例第一方面中,所述方法还包括:
若所述第一场景与所述目标场景不相匹配,输出移动引导信息;所述移动引导信息用于引导所述目标用户移动至所述目标场景;
跟随所述目标用户的移动状态调整拍摄角度,并在所述目标用户停止移动时确定调整后的目标拍摄区域;
基于所述目标拍摄区域获取第二场景;
判断所述第二场景是否与所述目标场景相匹配;
若所述第二场景与所述目标场景相匹配,输出所述留言信息。
作为一种可选的实施方式,在本申请实施例第一方面中,所述触发条件信息还包括预设动作;所述若所述第一场景与所述目标场景相匹配,输出所述留言信息,包括:
若所述第一场景与所述目标场景相匹配,捕捉所述目标用户的第一动作,判断所述第一动作是否与所述预设动作相匹配;
若所述第一动作与所述预设动作相匹配,输出所述留言信息;
若所述第一动作与所述预设动作不匹配,输出交互引导信息,所述交互引导信息用于引导所述目标用户执行所述预设动作;当检测到所述目标用户根据所述交互引导信息执行的第二动作与所述预设动作相匹配时,输出所述留言信息。
作为一种可选的实施方式,在本申请实施例第一方面中,所述留言信息包括视频留言;所述当进入留言模式时,获取留言信息和触发条件信息,包括:
当进入留言模式时,响应于录制开始指令,开启视频录制模式;
在所述视频录制模式下,识别正在说话的留言对象,并跟随所述留言对象的移动状态实时调整拍摄角度,以使得所述留言对象出现在实时拍摄区域之内;
响应于录制结束指令,获得录制完成的视频留言;
以及,获取触发条件信息。
作为一种可选的实施方式,在本申请实施例第一方面中,所述若所述第一场景与所述目标场景相匹配,输出留言信息,包括:
若所述第一场景与所述目标场景相匹配,检测所述目标用户的视线落点;
判断所述视线落点是否投落于用于输出所述视频留言的显示屏上的显示区域;
若投落于所述显示区域,通过所述显示屏输出所述视频留言。
本申请实施例第二方面公开一种智能音箱,所述智能音箱包括:
第一获取单元,用于当进入留言模式时,获取留言信息和触发条件信息;所述触发条件信息包括用户信息和场景信息;
第一判断单元,用于在检测到有人靠近时,判断是否识别出与所述用户信息相匹配的目标用户;
第二获取单元,用于所述第一判断单元判定识别出所述目标用户时,获取第一场景;
第二判断单元,用于判断所述第一场景是否与所述场景信息对应的目标场景相匹配;
第一留言输出单元,用于所述第二判断单元判定所述第一场景与所述目标场景相匹配时,输出所述留言信息。
作为一种可选的实施方式,在本申请实施例第二方面中,所述智能音箱还包括:
引导信息输出单元,用于所述第二判断单元判定所述第一场景与所述目标场景不相匹配时,输出移动引导信息;所述移动引导信息用于引导所述目标用户移动至所述目标场景;
拍摄调整单元,用于跟随所述目标用户的移动状态调整拍摄角度,并在所述目标用户停止移动时确定调整后的目标拍摄区域;
第三获取单元,用于基于所述目标拍摄区域获取第二场景;
第三判断单元,用于判断所述第二场景是否与所述目标场景相匹配;
第二留言输出单元,还用于所述第三判断单元判定所述第二场景与所述目标场景相匹配时,输出所述留言信息。
作为一种可选的实施方式,在本申请实施例第二方面中,所述触发条件信息还包括预设动作;所述第一留言输出单元,包括:
动作捕捉子单元,用于所述第二判断单元判定所述第一场景与所述目标场景相匹配时,捕捉所述目标用户的第一动作;
动作匹配子单元,用于判断所述第一动作是否与所述预设动作相匹配;
第一留言输出子单元,用于在所述第一动作与所述预设动作相匹配时,输出所述留言信息;
引导信息输出子单元,用于在所述第一动作与所述预设动作不匹配时,输出交互引导信息,所述交互引导信息用于引导所述目标用户执行所述预设动作;
所述第一留言输出子单元,还用于在检测到所述目标用户根据所述交互引导信息执行的第二动作与所述预设动作相匹配时,输出所述留言信息。
作为一种可选的实施方式,在本申请实施例第二方面中,所述留言信息包括视频留言;所述第一获取单元,包括:
开启子单元,用于在进入留言模式时,响应于录制开始指令,开启视频录制模式;
拍摄控制子单元,用于在所述视频录制模式下,识别正在说话的留言对象,并跟随所述留言对象的移动状态实时调整拍摄角度,以使得所述留言对象出现在实时拍摄区域之内;
留言获取子单元,用于响应于录制结束指令,获得录制完成的视频留言;
条件获取子单元,用于获取触发条件信息。
作为一种可选的实施方式,在本申请实施例第二方面中,所述第一留言输出单元,包括:
检测子单元,用于所述第二判断单元判定所述第一场景与所述目标场景相匹配时,检测所述目标用户的视线落点;
判断子单元,用于判断所述视线落点是否投落于用于输出所述视频留言的显示屏上的显示区域;
第二留言输出子单元,用于所述判断子单元判定所述视线落点投落于所述显示区域时,通过所述显示屏输出所述视频留言。
本申请实施例第三方面公开一种电子设备,包括:
存储有可执行程序代码的存储器;
与所述存储器耦合的处理器;
所述处理器调用所述存储器中存储的所述可执行程序代码,执行本申请实施例第一方面公开的一种留言信息的输出方法。
本申请实施例第四方面公开一种计算机可读存储介质,其存储计算机程序,其中,所述计算机程序使得计算机执行本申请实施例第一方面公开的一种留言信息的输出方法。
本申请实施例第五方面公开一种计算机程序产品,当所述计算机程序产品在计算机上运行时,使得所述计算机执行第一方面的任意一种方法的部分或全部步骤。
本申请实施例第六方面公开一种应用发布平台,所述应用发布平台用于发布计算机程序产品,其中,当所述计算机程序产品在计算机上运行时,使得所述计算机执行第一方面的任意一种方法的部分或全部步骤。
与现有技术相比,本申请实施例具有以下有益效果:
本申请实施例中,当进入留言模式时,获取留言信息和触发条件信息,其中,触发条件信息包括用户信息和场景信息;当检测到有人靠近时,判断是否识别出与用户信息相匹配的目标用户以及获取到的第一场景是否与场景信息对应的目标场景相匹配,从而在识别出目标用户和目标场景时主动输出留言信息,能够解决传统留言方式中留言信息容易被遗漏的问题,并且改善用户的音箱使用体验;此外,不限于根据用户信息确定被留言对象,还可以根据场景信息选择触发留言信息输出的特定场景,提高了输出留言信息的灵活性。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
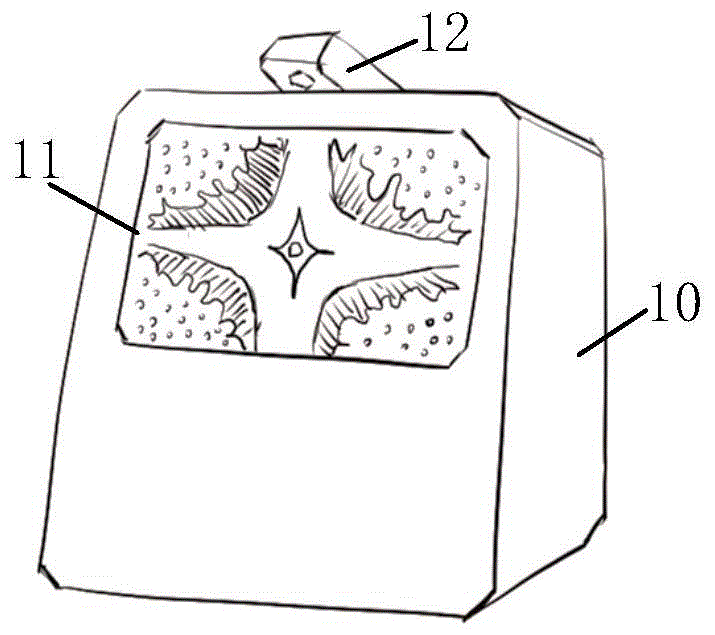
图1是本申请实施例公开的一种智能音箱的结构示意图;
图2是本申请实施例公开的一种留言信息的输出方法的流程示意图;
图3是本申请实施例公开的一种智能音箱获取第一场景的场景示意图;
图4是本申请实施例公开的一种智能音箱拍摄到的包括目标用户及第一场景的图像示意图;
图5是本申请实施例公开的一种智能音箱调整拍摄角度的示意图;
图6是本申请实施例公开的另一种留言信息的输出方法的流程示意图;
图7是本申请实施例公开的另一种智能音箱的结构示意图;
图8是本申请实施例公开的又一种智能音箱的结构示意图;
图9是本申请实施例公开的还一种智能音箱的结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,本发明的说明书和权利要求书中的术语“第一”、“第二”、“第三”“第四”等是用于区别不同的对象,而不是用于描述特定顺序。本申请实施例的术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
本申请实施例公开了一种留言信息的输出方法及智能音箱、存储介质,能够解决留言信息容易被遗漏的问题。本申请实施例公开的留言信息的输出方法适用于智能音箱,具体的,还可适用于上述智能音箱内的web应用、app或者专用软件。为了更好的理解本申请实施例公开的留言信息的输出方法,以下先对本申请实施例公开的一种智能音箱进行描述。
请参阅图1,图1是本申请实施例公开的一种智能音箱的结构示意图。如图1所示,该智能音箱10的箱体外壳上设有显示屏11,该智能音箱10的上方设有顶部摄像头12。
在一种可能的实现方式中,智能音箱10还可以在箱体外壳的其他位置设有一个或多个摄像头,具体数目与位置均不作限定。在另一种可能的实现方式中,该顶部摄像头12与智能音箱可拆卸连接,并可固定于智能音箱的箱体外壳上任意位置。为了方便理解,以下均以图1所示的顶部摄像头12为例进行描述。
在一些可选的实施例中,该顶部摄像头12可以为广角摄像头。
在一些可选的实施例中,该顶部摄像头12可以在用户手推下或者在马达驱动下,发生360°范围中的任意角度的旋转,以及镜头轴心线方向上的升降。
在一些可选的实施例中,该智能音箱10的底部可以设置有若干个滑动轮,使得智能音箱10可借助上述若干个滑动轮实现位置的快速移动。还可选的,该智能音箱10还可以借助内置的驱动装置和制动装置分别控制滑动轮的移动和停止运动。
下面结合附图对本申请实施例公开的留言信息的输出方法进行详细描述。
请参阅图2,图2是本申请实施例公开的一种留言信息的输出方法的流程示意图。如图2所示,该方法可以包括以下步骤。
201、当进入留言模式时,获取留言信息和触发条件信息;触发条件信息包括用户信息和场景信息。
在本申请实施例中,进入留言模式的方式可以包括但不限于:留言对象语音唤醒(比如用户语音指示“我要留言”)以及留言对象在智能音箱上手动开启提供留言功能的应用程序,其中,留言对象为主动发起留言的用户。留言信息的形式可以包括文字、语音和视频等,对此不作具体限定。触发条件信息用于指示触发智能音箱输出留言信息的条件,包括根据用户信息所确定的目标对象和根据场景信息确定的特定场所(比如卧室、客厅)。其中,用户信息可以为目标对象的人脸特征信息、指纹特征信息、声纹特征信息等,不作具体限定。
在一些可选的实现方式中,智能音箱可以识别留言对象语音指定的目标用户名称和目标场景名称,或者接收留言对象手动输入的目标用户名称和目标场景名称,从而根据目标用户名称和目标场景名称,从存储有用户数据以及场景数据的数据库中获取该目标用户对应的用户信息及场景信息。举例来说,智能音箱识别出用户a语音指定“客厅,给妈妈”,则可从用户a的好友列表中确定与用户a为母女关系的用户b,获得用户b的用户信息,并将用户a家客厅的图像确定为场景信息。
在另一些可选的实现方式中,智能音箱还可以响应于留言对象的拍摄指令,通过顶部摄像头拍摄留言对象当前所处环境的环境图像,并将该环境图像作为场景信息。
202、当检测到有人靠近时,判断是否识别出与用户信息相匹配的目标用户,若是,执行步骤203;若否,结束本流程。
在本申请实施例中,智能音箱可以通过内设的超声波传感器、红外接近感应部件或者顶部摄像头检测是否有人靠近,对此不作具体限定。当检测到有人靠近时,智能音箱可以利用麦克风采集人声信号,若从人声信号中识别出目标用户相匹配的声音特征信息,则判定识别出用户信息相匹配的目标用户;或者,智能音箱还可以利用启动的顶部摄像头拍摄人脸图像,若人脸图像与目标用户的人脸特征信息相匹配,则判定识别出用户信息相匹配的目标用户,对智能音箱识别目标用户的具体方式亦不作限定。
其中,可选的,智能音箱在检测到有人靠近时,若通过顶部摄像头无法拍摄到完整的用户人脸,则可以控制顶部摄像头旋转或升降,直至可利用顶部摄像头在调整后的特定拍摄角度下拍摄到完整的用户人脸,获得人脸图像。
另外,可选的,触发条件信息还可以包括时间信息,步骤202具体还可以为:若当前时间为时间信息所指示的触发时间,当检测到有人靠近时,判断是否识别出与用户信息相匹配的目标用户。
203、获取第一场景。
在一些可选的实现方式中,智能音箱利用顶部摄像头锁定目标用户,以保证目标用户出现在顶部摄像头的拍摄范围之内;之后,对目标用户及其所处场所进行拍摄,获得对第一场景拍摄得到的场景图像。
204、判断第一场景是否与场景信息对应的目标场景相匹配,若是,执行步骤205;若否,结束本流程。
在一些可选的实现方式中,智能音箱可以将对第一场景拍摄到的场景图像与场景信息包括的目标场景的场景图像进行匹配,若匹配成功,则判定第一场景与目标场景相匹配。
请一并参阅图3和图4,图3是本申请实施例公开的一种智能音箱获取第一场景的场景示意图,图4是本申请实施例公开的一种智能音箱拍摄到的包括目标用户及第一场景的图像示意图。如图3所示,智能音箱30利用顶部摄像头301锁定客厅中的目标用户31时,其拍摄范围如箭头32所示。智能音箱30基于箭头32所示的拍摄范围进行拍摄,获得如图4所示的图像,其中,从该图像中可识别出目标用户31和第一场景的场景图像33(图4中阴影区域)。假设目标场景为c家客厅,则可以利用第一场景的场景图像33与c家客厅的场景图像相匹配,从而确定第一场景是否与可触发留言的c家客厅相匹配。
205、输出留言信息。
在本申请实施例中,若留言信息为语音留言,则智能音箱可以通过扬声器播放该语音留言;若留言信息为文字留言,则智能音箱可以在显示屏上显示该文字留言,或者对文字留言进行文字语音转换,获得相应的语音信息进行播放;若留言信息为视频留言,则智能音箱可以在显示屏上播放该视频留言,不作具体限定。
在一些可选的实现方式中,若留言信息为视频留言,步骤201具体可以包括:当进入留言模式时,响应于录制开始指令,开启视频录制模式;在视频录制模式下,识别正在说话的留言对象,并跟随留言对象的移动状态实时调整拍摄角度,以使得留言对象出现在实时拍摄区域之内;响应于录制结束指令,获得录制完成的视频留言;以及,获取触发条件信息。
其中,录制开始指令可以为留言对象点击智能音箱上用于录制功能的虚拟或实体按键时产生的指令,也可以为用于指示录制开始的语音指令,不作具体限定。录制结束指令与录制开始指令类似,亦不作赘述。可见,这样能够改善录制视频留言的灵活度,扩大了录制视频留言时的移动范围,比如,家长录制视频留言来提醒孩子做好的早餐放置在厨房内何处,并教导孩子如何自己加热早餐,在此过程中,家长只需专注于教导步骤,无需手动移动智能音箱的箱体以调整拍摄角度,故智能音箱带来了更好的使用体验。
进一步的,在一些可选的实现方式中,在视频录制模式下,可以控制智能音箱的箱体跟随留言对象的移动状态而移动,以实时调拍摄角度;比如,当留言对象向左移动时,则控制箱体左移,当留言对象向右移动时,则控制箱体右移;
或者,可以跟随留言对象的移动状态控制摄像头旋转或升降;比如,当留言对象向右(或向左)移动时,则控制摄像头向右(或向左)转动,当留言对象向上(或向下)移动时,则控制摄像头上升(或下降);
或者,还可以跟随留言对象的移动状态,同时控制智能音箱的箱体移动以及摄像头的旋转或升降。
以控制智能音箱的箱体移动为例,请参阅图5,图5是本申请实施例公开的一种智能音箱调整拍摄角度的示意图。如图5中虚线部分所示,当智能音箱在处于初始位置50时,智能音箱的摄像头位于501所示位置处,其拍摄范围如虚线箭头51所示,可拍摄到在起点位置52处的目标用户。若目标用户从起点位置52移动至终点位置53,可见终点位置53已不属于智能音箱在初始位置50时的拍摄范围,故智能音箱将控制箱体随着目标用户的移动顺时针转动,直至处于移动位置54处的智能音箱可获得如实线箭头55所示的拍摄范围,并重新拍摄到终点位置53处的目标用户。
可见,实施上述可选的实现方式,利用上述多种方式调整拍摄角度,能够涵盖更多的拍摄角度,使得追踪留言对象的过程更为自然。
另外,在一些可选的实现方式中,步骤205具体可以包括:若第一场景与目标场景相匹配,检测目标用户的视线落点;判断视线落点是否投落于用于输出视频留言的显示屏上的显示区域;若投落于显示区域,通过显示屏输出视频留言。其中,上述显示屏可以指智能音箱的显示屏。
可见,实施上述可选的实现方式,当目标用户看向智能音箱的显示屏时,智能音箱才会播放视频留言,能够避免目标用户在未留意显示屏时错过视频留言的播放,而需要重新手动调整视频进度条的情况,减少不必要的人为操作。
在另一些可选的实现方式中,在检测目标用户的视线落点之后,智能音箱还可以检测附近可建立连接、且具有显示输出功能的若干其他智能设备;判断目标用户的视线落点是否投落于目标智能设备的显示区域,若投落于目标智能设备的显示区域,则通过目标智能设备输出视频留言。其中,目标智能设备为若干其他智能设备中任一智能设备;其他智能设备包括但不限于智能手机、平板电视机、平板电脑以及投影仪。可以理解,智能手机的显示区域应为手机屏幕,平板电视机的显示区域应为电视屏幕、平板电脑的显示区域应为电脑屏幕,以及投影仪的显示区域可以为与该投影仪建立连接的投影幕布等。
举例来说,若目标用户正在看向电视屏幕,则智能音箱可以播放视频留言,并通过电视投屏功能将正在播放的视频留言投影到智能电视上进行显示。可见,上述可选的实现方式还能够提供更多种视频留言的播放形式,适应目标用户的实际观看需求。
可见,实施图2所描述的方法,当进入留言模式时,若根据触发条件信息识别出目标用户和目标场景,主动输出留言信息,能够解决传统留言方式中留言信息容易被遗漏的问题,并且改善用户的音箱使用体验;此外,不限于根据用户信息确定被留言对象,还可以根据场景信息选择触发留言信息输出的特定场景,提高了输出留言信息的灵活性。
请参阅图6,图6是本申请实施例公开的另一种留言信息的输出方法的流程示意图。如图6所示,该方法可以包括以下步骤。
601、当进入留言模式时,获取留言信息和触发条件信息;触发条件信息包括用户信息和场景信息。
602、当检测到有人靠近时,判断是否识别出与用户信息相匹配的目标用户,若是,执行步骤603;若否,结束本流程。
603、获取第一场景。
604、判断第一场景是否与场景信息对应的目标场景相匹配,若否,执行步骤605~步骤608;若是,执行步骤609。
605、输出移动引导信息;移动引导信息用于引导目标用户移动至目标场景。
在本申请实施例中,移动引导信息的形式可以为文字信息、语音信息、图片信息或者视频信息,对此不作限定。比如,留言对象将为目标用户准备的生日礼物放在了书房,并留言提醒,则智能音箱可以输出内容为“嗨~不去书房里看一看吗?”的移动引导信息,以提示在客厅的目标用户移动至书房。
606、跟随目标用户的移动状态调整拍摄角度,并在目标用户停止移动时确定调整后的目标拍摄区域。
在本申请实施例中,智能音箱跟随目标用户的移动状态调整拍摄角度的方式请参照上述对智能音箱跟随留言对象的移动状态实时调整拍摄角度的描述,在此不再赘述。
607、基于目标拍摄区域获取第二场景。
608、判断第二场景是否与目标场景相匹配,若是,执行步骤609;若否,结束本流程。
可见,实施上述步骤605~步骤608,当目标用户未处于触发留言的目标场景时,能够引导目标用户移动至目标场景,提高触发留言信息的成功率。
在一些可选的实现方式中,触发条件信息还包括预设动作;若第一场景与目标场景相匹配,在执行步骤609之前,还可以捕捉目标用户的第一动作,判断第一动作是否与预设动作相匹配;
若第一动作与预设动作相匹配,执行步骤609;
若第一动作与预设动作不匹配,输出交互引导信息,交互引导信息用于引导目标用户执行预设动作;当检测到目标用户根据交互引导信息执行的第二动作与预设动作相匹配时,执行步骤609。
其中,交互引导信息的具体形式与移动引导信息类似,在此不再赘述。举例来说,假设目标场景为厨房,留言信息包括指示目标用户取出冰箱中食物的内容,则预设动作可以为打开冰箱门,如果目标用户在进入厨房之后,没有打开冰箱门便转身离去,则智能音箱可以语音指示“打开冰箱看一看吧”,直至拍摄到目标用户打开冰箱门时,输出留言信息。可见,实施上述可选的实现方式,还能够在目标场景中指定预设动作,提高触发输出留言信息的交互性。
609、输出留言信息。
在一些可选的实现方式中,步骤609之后,还可以响应于目标用户的通话请求,获取留言对象的通话路径信息,比如留言对象的手机号、微信号等;根据通话路径信息与留言对象关联的终端建立通信连接,以实现目标用户与留言对象的远程互动。可见,这样能够进一步提高智能音箱的实用性和互动性。
可见,实施图6所描述的方法,当进入留言模式时,若根据触发条件信息识别出目标用户和目标场景,主动输出留言信息,能够解决传统留言方式中留言信息容易被遗漏的问题,并且改善用户的音箱使用体验;此外,不限于根据用户信息确定被留言对象,还可以根据场景信息选择触发留言信息输出的特定场景,提高了输出留言信息的灵活性;进一步的,当目标用户未处于触发留言的目标场景时,能够引导目标用户移动至目标场景,提高触发留言信息的成功率;再进一步的,还能够在目标场景中指定预设动作,提高触发输出留言信息的交互性。
请参阅图7,图7是本申请实施例公开的另一种智能音箱的结构示意图。如图7所示,该智能音箱可以包括第一获取单元701、第一判断单元702、第二获取单元703、第二判断单元704以及第一留言输出单元705,其中:
第一获取单元701,用于当进入留言模式时,获取留言信息和触发条件信息;触发条件信息包括用户信息和场景信息。
在一些可选的实现方式中,第一获取单元701用于识别留言对象语音指定的目标用户名称和目标场景名称,或者接收留言对象手动输入的目标用户名称和目标场景名称,并根据目标用户名称和目标场景名称,从存储有用户数据以及场景数据的数据库中获取该目标用户对应的用户信息及场景信息。
在另一些可选的实现方式中,第一获取单元701还可以用于响应于留言对象的拍摄指令,通过顶部摄像头拍摄留言对象当前所处环境的环境图像,并将该环境图像作为场景信息。
在一些可选的实现方式中,若留言信息为视频留言,第一获取单元701,包括:
开启子单元7011,用于在进入留言模式时,响应于录制开始指令,开启视频录制模式;
拍摄控制子单元7012,用于在视频录制模式下,识别正在说话的留言对象,并跟随留言对象的移动状态实时调整拍摄角度,以使得留言对象出现在实时拍摄区域之内;
留言获取子单元7013,用于响应于录制结束指令,获得录制完成的视频留言;
条件获取子单元7014,用于获取触发条件信息。
进一步的,在一些可选的实现方式中,拍摄控制子单元7012具体用于在视频录制模式下,控制智能音箱的箱体跟随留言对象的移动状态而移动,以实时调拍摄角度;比如,当留言对象向左移动时,则控制箱体左移,当留言对象向右移动时,则控制箱体右移;或者,跟随留言对象的移动状态控制摄像头旋转或升降;比如,当留言对象向右(或向左)移动时,则控制摄像头向右(或向左)转动,当留言对象向上(或向下)移动时,则控制摄像头上升(或下降);或者,跟随留言对象的移动状态,同时控制智能音箱的箱体移动以及摄像头的旋转或升降。可见,利用上述多种方式调整拍摄角度,能够涵盖更多的拍摄角度,使得追踪留言对象的过程更为自然。
第一判断单元702,用于在检测到有人靠近时,判断是否识别出与用户信息相匹配的目标用户。
可选的,第一判断单元702还用于在检测到有人靠近时,若通过顶部摄像头无法拍摄到完整的用户人脸,则可以控制顶部摄像头旋转或升降,直至可利用顶部摄像头在调整后的特定拍摄角度下拍摄到完整的用户人脸,获得人脸图像。
另外,可选的,触发条件信息还可以包括时间信息,第一判断单元702还可以用于在当前时间为时间信息所指示的触发时间,且检测到有人靠近时,判断是否识别出与用户信息相匹配的目标用户。
第二获取单元703,用于第一判断单元702判定识别出目标用户时,获取第一场景。
第二判断单元704,用于判断第一场景是否与场景信息对应的目标场景相匹配。
第一留言输出单元705,用于第二判断单元704判定第一场景与目标场景相匹配时,输出留言信息。
在一些可选的实现方式中,第一留言输出单元705,包括:
检测子单元7051,用于第二判断单元704判定第一场景与目标场景相匹配时,检测目标用户的视线落点;
判断子单元7052,用于判断视线落点是否投落于用于输出视频留言的显示屏上的显示区域;
第二留言输出子单元7053,用于判断子单元7052判定视线落点投落于显示区域时,通过显示屏输出视频留言。
可见,实施上述可选的实现方式,能够避免目标用户在未留意显示屏时错过视频留言的播放,而需要重新手动调整视频进度条的情况,减少不必要的人为操作。
在另一些可选的实现方式中,第一留言输出单元705还包括检测子单元,检测子单元用于在检测目标用户的视线落点之后,检测附近可建立连接、且具有显示输出功能的若干其他智能设备;
判断子单元7052,还用于判断目标用户的视线落点是否投落于目标智能设备的显示区域,目标智能设备为若干其他智能设备中任一智能设备;
第二留言输出子单元7053,还用于在判断子单元7052判定目标用户的视线落点投落于目标智能设备的显示区域时,则通过目标智能设备输出视频留言。其中,其他智能设备包括但不限于智能手机、平板电视机、平板电脑以及投影仪。可以理解,智能手机的显示区域应为手机屏幕,平板电视机的显示区域应为电视屏幕、平板电脑的显示区域应为电脑屏幕,以及投影仪的显示区域可以为与该投影仪建立连接的投影幕布等。
可见,上述可选的实现方式还能够提供更多种视频留言的播放形式,适应目标用户的实际观看需求。
可见,实施图7所描述的智能音箱,当进入留言模式时,若根据触发条件信息识别出目标用户和目标场景,主动输出留言信息,能够解决传统留言方式中留言信息容易被遗漏的问题,并且改善用户的音箱使用体验;此外,不限于根据用户信息确定被留言对象,还可以根据场景信息选择触发留言信息输出的特定场景,提高了输出留言信息的灵活性。
请参阅图8,图8是本申请实施例公开的另一种智能音箱的结构示意图。其中,图8所示的智能音箱是由图7所示的智能音箱进行优化得到的。与图7所示的智能音箱相比较,图8所示的智能音箱还可以包括引导信息输出单元706、拍摄调整单元707、第三获取单元708、第三判断单元709以及第二留言输出单元710,其中:
引导信息输出单元706,用于第二判断单元704判定第一场景与目标场景不相匹配时,输出移动引导信息;移动引导信息用于引导目标用户移动至目标场景。
拍摄调整单元707,用于跟随目标用户的移动状态调整拍摄角度,并在目标用户停止移动时确定调整后的目标拍摄区域。
第三获取单元708,用于基于目标拍摄区域获取第二场景。
第三判断单元709,用于判断第二场景是否与目标场景相匹配。
第二留言输出单元710,还用于第三判断单元709判定第二场景与目标场景相匹配时,输出留言信息。
在一些可选的实现方式中,触发条件信息还包括预设动作;第一留言输出单元705,还包括:
动作捕捉子单元7054,用于第二判断单元704判定第一场景与目标场景相匹配时,捕捉目标用户的第一动作;
动作匹配子单元7055,用于判断第一动作是否与预设动作相匹配;
第一留言输出子单元7056,用于在第一动作与预设动作相匹配时,输出留言信息;
引导信息输出子单元7057,用于在第一动作与预设动作不匹配时,输出交互引导信息,交互引导信息用于引导目标用户执行预设动作;
第一留言输出子单元7056,还用于在检测到目标用户根据交互引导信息执行的第二动作与预设动作相匹配时,输出留言信息。
可见,实施上述可选的实现方式,还能够在目标场景中指定预设动作,提高触发输出留言信息的交互性。
在一些可选的实现方式中,该智能音箱还可以包括通话单元,通话单元用于在第一留言输出单元705输出留言信息之后,响应于目标用户的通话请求,获取留言对象的通话路径信息,比如留言对象的手机号、微信号等;根据通话路径信息与留言对象关联的终端建立通信连接,以实现目标用户与留言对象的远程互动。可见,这样能够进一步提高智能音箱的实用性和互动性。
可见,实施图8所描述的智能音箱,当进入留言模式时,若根据触发条件信息识别出目标用户和目标场景,主动输出留言信息,能够解决传统留言方式中留言信息容易被遗漏的问题,并且改善用户的音箱使用体验;此外,不限于根据用户信息确定被留言对象,还可以根据场景信息选择触发留言信息输出的特定场景,提高了输出留言信息的灵活性;进一步的,当目标用户未处于触发留言的目标场景时,能够引导目标用户移动至目标场景,提高触发留言信息的成功率;再进一步的,还能够在目标场景中指定预设动作,提高触发输出留言信息的交互性。
请参阅图9,图9是本申请实施例公开的还一种智能音箱的结构示意图。如图9所示,该智能音箱可以包括:
存储有可执行程序代码的存储器901;
与存储器901耦合的处理器902;
其中,处理器902调用存储器901中存储的可执行程序代码,执行图2或图6任意一种留言信息的输出方法。
本申请实施例公开一种计算机可读存储介质,其存储计算机程序,其中,该计算机程序使得计算机执行图2或图6任意一种留意信息的输出方法。
本申请实施例还公开一种计算机程序产品,其中,当计算机程序产品在计算机上运行时,使得计算机执行如以上各方法实施例中的方法的部分或全部步骤。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质包括只读存储器(read-onlymemory,rom)、随机存储器(randomaccessmemory,ram)、可编程只读存储器(programmableread-onlymemory,prom)、可擦除可编程只读存储器(erasableprogrammablereadonlymemory,eprom)、一次可编程只读存储器(one-timeprogrammableread-onlymemory,otprom)、电子抹除式可复写只读存储器(electrically-erasableprogrammableread-onlymemory,eeprom)、只读光盘(compactdiscread-onlymemory,cd-rom)或其他光盘存储器、磁盘存储器、磁带存储器、或者能够用于携带或存储数据的计算机可读的任何其他介质。
以上对本申请实施例公开的一种留言信息的输出方法及智能音箱、存储介质进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!