一种基于行人的关键点信息与语义分割信息进行行人重识别的方法与流程
本发明涉及行人重识别技术领域,尤其是一种基于行人的关键点信息与语义分割信息进行行人重识别的方法。
背景技术:
中国专利公开了一种行人重识别方法,专利号为201610922236.x,其中记载:包括行人特征提取和特征的度量;行人特征提取主要采用滑动窗口提取图像颜色直方图,对主颜色进行扩展,再在每一行滑窗中统计每一颜色模式出现的次数,选取较大的几次之和作为该颜色的特征输出,滑窗遍历整幅图像,归一化后形...
上述方案计算量较小可快速得出结果,但显而易见的,行人是一种姿态多变且周围环境在不断变换的目标,甚至会出现换装等情况,现有技术难以识别。
技术实现要素:
针对现有技术的不足,本发明提供一种基于行人的关键点信息与语义分割信息进行行人重识别的方法。
本发明的技术方案为:
一种基于行人的关键点信息与语义分割信息进行行人重识别的方法,包括以下步骤:
s1,目标检测,在图片中找到目标的位置,输出目标的位置信息;
s2,语义分割,在图片中找到目标的位置,输出目标的具体形状掩码;
s3,人脸识别,识别出人脸的具体类别,包括身份、性别和年龄段;
s4,关键点检测,定位人在图像中的位置以及人体各个关键点的位置;
s5,行人重识别,以人的身体属性识别出人的身份,可以理解的,此时的图片可能是视频中的一帧,故分辨率可以较低,甚至可以看不见其脸部信息。
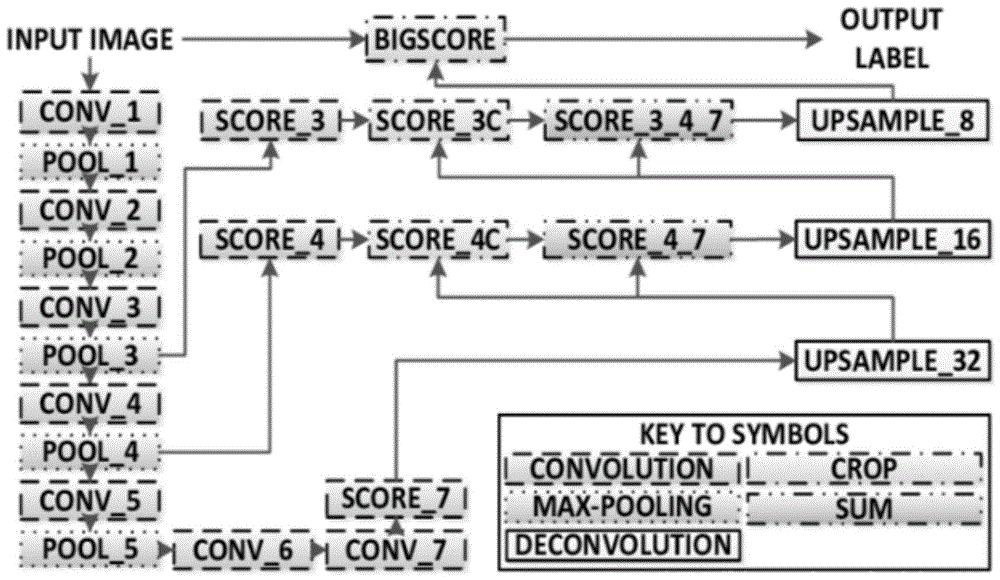
其中,语义分割方法:具体步骤如下:
encoder:使用预先培训过的vgg16作为编码器。解码器从vgg16的第7层开始。
fcnlayer-8:最后一个完全连接的vgg16层被1x1卷积替换。
fcnlayer-9:fcnlayer-8升序2次,与vgg16的layer4匹配,使用带参数的转置卷积:(kernel=(4,4),stead=(2,2),padding='same')。之后,在vgg16的第4层和fcn的第9层之间添加了一个跳过连接。
fcnlayer-10:fcnlayer-9被放大2倍,以便与vgg16第3层的尺寸匹配,使用带参数的转置卷积:(kernel=(4,4),stead=(2,2),padding=(相同))。之后,在vgg16的第3层和fcn第10层之间添加了一个跳过连接。
fcnlayer-11:fcnlayer-10被放大4倍以匹配输入图像大小的尺寸,因此我们得到实际图像,深度等于类数,使用带参数的转置卷积:(kernel=(16,16),step=(8,8),padding='same')。
进一步地,所述语义分割的具体实现步骤:
步骤1
我们首先将预先培训过的vgg-16模型加载到tensorflow中。
步骤2
现在,我们主要使用vgg模型中的张量为fcn创建层。给定vgg层输出的张量和要分类的类数,我们返回该输出最后一层的张量。特别地,我们将1x1卷积应用于编码器层,然后将解码器层添加到具有跳过连接和升序采样的网络中。
步骤3
优化神经网络,也就是建立tensorflow损失函数和优化器操作。
步骤4
定义了train-nn函数,它接受重要的参数,包括epoch数、批大小、丢失函数、优化器操作和输入图像的占位符、标签图像、学习速率。
步骤5
训练网络,在这个run函数中,首先使用load_vgg、layers和optimize函数构建网络;然后,使用train_nn函数对网络进行训练,并保存推理数据以备记录。
具体的,所述关键点检测的方法采用二维人体骨骼关键点检测或者三维人体骨骼关键点检测。
具体的,所述二维人体骨骼关键点检测方法为:
图像数据获取,然后进行人体关键点检测,继而进行人体关键点组合,而后将关键点信息映射到原图,将处理后的图像输出(输出方式为rgb)。
具体的,所述三维人体骨骼关键点检测方法为:
图像数据获取,然后进行人体关键点检测,继而进行人体关键点组合,而后将关键点信息映射到原图,转到三维空间,将处理后的图像输出(输出方式为rgbd)。
本发明的有益效果为:通过关键点信息锁定行人,在行走过程中行人的各种动作甚至脸部关键信息的缺失都不会造成目标丢失,通过语义分割可快速将我们感兴趣的区域/目标呈现,减少追踪的工作量。
附图说明
图1为本发明中语义分割的示意图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步说明:
实施例1
如图1所示,一种基于行人的关键点信息与语义分割信息进行行人重识别的方法,包括以下步骤:
s1,目标检测,在图片中找到目标的位置,输出目标的位置信息;
s2,语义分割,在图片中找到目标的位置,输出目标的具体形状掩码;
s3,人脸识别,识别出人脸的具体类别,包括身份、性别和年龄段;
s4,关键点检测,定位人在图像中的位置以及人体各个关键点的位置;
s5,行人重识别,以人的身体属性识别出人的身份,可以理解的,此时的图片可能是视频中的一帧,故分辨率可以较低,甚至可以看不见其脸部信息。
其中,语义分割方法:具体步骤如下:
encoder:使用预先培训过的vgg16作为编码器。解码器从vgg16的第7层开始。
fcnlayer-8:最后一个完全连接的vgg16层被1x1卷积替换。
fcnlayer-9:fcnlayer-8升序2次,与vgg16的layer4匹配,使用带参数的转置卷积:(kernel=(4,4),stead=(2,2),padding='same')。之后,在vgg16的第4层和fcn的第9层之间添加了一个跳过连接。
fcnlayer-10:fcnlayer-9被放大2倍,以便与vgg16第3层的尺寸匹配,使用带参数的转置卷积:(kernel=(4,4),stead=(2,2),padding=(相同))。之后,在vgg16的第3层和fcn第10层之间添加了一个跳过连接。
fcnlayer-11:fcnlayer-10被放大4倍以匹配输入图像大小的尺寸,因此我们得到实际图像,深度等于类数,使用带参数的转置卷积:(kernel=(16,16),step=(8,8),padding='same')。
进一步地,所述语义分割的具体实现步骤:
步骤1
我们首先将预先培训过的vgg-16模型加载到tensorflow中。以tensorflowsession和vgg文件夹的路径(可在此处下载)为例,我们返回vgg模型中的张量元组,包括图像输入、keep-prob(控制辍学率)、第3层、第4层和第7层。
步骤2
现在,我们主要使用vgg模型中的张量为fcn创建层。给定vgg层输出的张量和要分类的类数,我们返回该输出最后一层的张量。特别地,我们将1x1卷积应用于编码器层,然后将解码器层添加到具有跳过连接和升序采样的网络中。
步骤3
下一步是优化我们的神经网络,也就是建立tensorflow损失函数和优化器操作。这里我们使用交叉熵作为损失函数,使用adam作为优化算法。
步骤4
这里我们定义了train-nn函数,它接受重要的参数,包括epoch数、批大小、丢失函数、优化器操作和输入图像的占位符、标签图像、学习速率。对于培训过程,我们还将保持概率设置为0.5,学习率设置为0.001。为了跟踪进度,我们还打印出培训期间的损失。
步骤5
最后,是时候训练我们的网络了!在这个run函数中,我们首先使用load_vgg、layers和optimize函数构建网络。然后,我们使用train_nn函数对网络进行训练,并保存推理数据以备记录。
选择epochs=40,batch_size=16,num_classes=2,image_shape=(160,576)。
具体的,所述关键点检测的方法采用二维人体骨骼关键点检测。
具体的,所述二维人体骨骼关键点检测方法为:
图像数据获取,然后进行人体关键点检测,继而进行人体关键点组合,而后将关键点信息映射到原图,将处理后的图像输出(输出方式为rgb)。
实施例2
如图1所示,一种基于行人的关键点信息与语义分割信息进行行人重识别的方法,包括以下步骤:
s1,目标检测,在图片中找到目标的位置,输出目标的位置信息;
s2,语义分割,在图片中找到目标的位置,输出目标的具体形状掩码;
s3,人脸识别,识别出人脸的具体类别,包括身份、性别和年龄段;
s4,关键点检测,定位人在图像中的位置以及人体各个关键点的位置;
s5,行人重识别,以人的身体属性识别出人的身份,可以理解的,此时的图片可能是视频中的一帧,故分辨率可以较低,甚至可以看不见其脸部信息。
其中,语义分割方法:具体步骤如下:
encoder:使用预先培训过的vgg16作为编码器。解码器从vgg16的第7层开始。
fcnlayer-8:最后一个完全连接的vgg16层被1x1卷积替换。
fcnlayer-9:fcnlayer-8升序2次,与vgg16的layer4匹配,使用带参数的转置卷积:(kernel=(4,4),stead=(2,2),padding='same')。之后,在vgg16的第4层和fcn的第9层之间添加了一个跳过连接。
fcnlayer-10:fcnlayer-9被放大2倍,以便与vgg16第3层的尺寸匹配,使用带参数的转置卷积:(kernel=(4,4),stead=(2,2),padding=(相同))。之后,在vgg16的第3层和fcn第10层之间添加了一个跳过连接。
fcnlayer-11:fcnlayer-10被放大4倍以匹配输入图像大小的尺寸,因此我们得到实际图像,深度等于类数,使用带参数的转置卷积:(kernel=(16,16),step=(8,8),padding='same')。
进一步地,所述语义分割的具体实现步骤:
步骤1
我们首先将预先培训过的vgg-16模型加载到tensorflow中。以tensorflowsession和vgg文件夹的路径(可在此处下载)为例,我们返回vgg模型中的张量元组,包括图像输入、keep-prob(控制辍学率)、第3层、第4层和第7层。
步骤2
现在,我们主要使用vgg模型中的张量为fcn创建层。给定vgg层输出的张量和要分类的类数,我们返回该输出最后一层的张量。特别地,我们将1x1卷积应用于编码器层,然后将解码器层添加到具有跳过连接和升序采样的网络中。
步骤3
下一步是优化我们的神经网络,也就是建立tensorflow损失函数和优化器操作。这里我们使用交叉熵作为损失函数,使用adam作为优化算法。
步骤4
这里我们定义了train-nn函数,它接受重要的参数,包括epoch数、批大小、丢失函数、优化器操作和输入图像的占位符、标签图像、学习速率。对于培训过程,我们还将保持概率设置为0.5,学习率设置为0.001。为了跟踪进度,我们还打印出培训期间的损失。
步骤5
最后,是时候训练我们的网络了!在这个run函数中,我们首先使用load_vgg、layers和optimize函数构建网络。然后,我们使用train_nn函数对网络进行训练,并保存推理数据以备记录。
选择epochs=40,batch_size=16,num_classes=2,image_shape=(160,576)。
具体的,所述关键点检测的方法采用三维人体骨骼关键点检测。
具体的,所述三维人体骨骼关键点检测方法为:
图像数据获取,然后进行人体关键点检测,继而进行人体关键点组合,而后将关键点信息映射到原图,转到三维空间,将处理后的图像输出(输出方式为rgbd)。
上述实施例和说明书中描述的只是说明本发明的原理和最佳实施例,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。
- 还没有人留言评论。精彩留言会获得点赞!