一种数据驱动的易逝品订货方法与流程
本发明属于易逝品订货的分析领域,具体涉及一种数据驱动的易逝品订货方法。
背景技术:
需求不确定问题是供应链管理实践和研究中的重大挑战。在需求不确定的情况下最大化利润一直是收益管理的核心问题,解决需求风险的重要方法是部署安全库存,为了设置适当的库存水平,许多库存模型都假设了一种具体的需求分布,一个典型的例子是报童问题。然而现实生活中,真实的需求分布往往无法获得,甚至可能随时间发生改变。一旦估计了有偏差的需求分布,就可能导致高度失真的订货决策。因此,基于需求分布假设的订货方法很难对易逝产品的需求做到精确预测,也无法得到最优的订货决策。
然而,数据驱动方法本质上是直接从历史需求数据入手,对这些数据进行分析处理,挖掘数据背后所蕴含的价值。例,历史需求数据在一定程度上能够反映需求的变化趋势,为决策者做出最优决策提供有效信息。该方法直接跳过了模型驱动中模型假设与分布拟合,解决了需求分布不存在,数据更新后需求分布改变和数据更新后需求分布参数改变的三大难题。相比传统模型驱动方法,该方法不仅计算简单,而且能获得更准确的订货决策。
技术实现要素:
针对现有技术中的上述不足,本发明提供了一种数据驱动的易逝品订货方法,以期能够改善传统模型驱动方法订货误差大的问题。
为了达到上述发明目的,本发明采用的技术方案为:
一种数据驱动的易逝品订货方法,包括以下步骤:
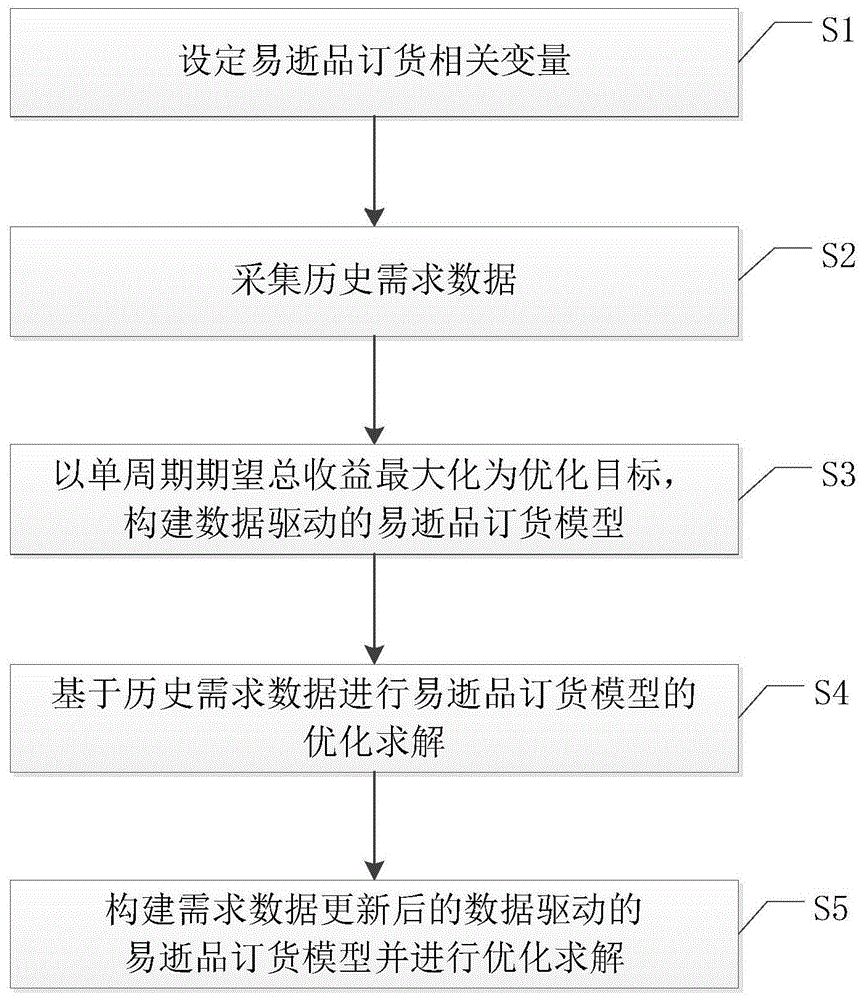
s1、设定易逝品订货相关变量;
s2、采集消费者的历史需求数据;
s3、构建单周期期望总收益函数,以单周期期望总收益最大化为优化目标,构建数据驱动的易逝品订货模型;
s4、基于步骤s2采集的历史需求数据对步骤s3构建的易逝品订货模型进行优化求解;
s5、构建需求数据更新后的数据驱动的易逝品订货模型并进行优化求解。
作为上述易逝品订货方法的进一步改进,所述步骤s1中易逝品订货相关变量包括订货量q、单位订货成本c、单位零售价p、单位缺货成本s、单位残值v、单位缺货损失cu和单位过剩损失co。
作为上述易逝品订货方法的进一步改进,所述s2具体采集当天前n天内消费者每天的需求量d,表示为
d=(d1,d2,...di,...,dn)
其中,di表示第i天的需求量。
作为上述易逝品订货方法的进一步改进,所述步骤s3中单周期期望总收益函数表示为e[π(q,d)]=e[pmin(q,d)+vmax(0,q-d)-smax(0,d-q)-cq]
其中,e[π(q,d)]为单周期期望总收益函数,q为数据驱动的易逝品订货模型的决策变量,d为决策者面临的随机需求。
作为上述易逝品订货方法的进一步改进,所述步骤s3中以单周期期望总收益最大化为优化目标,构建数据驱动的易逝品订货模型,表示为
作为上述易逝品订货方法的进一步改进,所述步骤s4中基于步骤s2采集的历史需求数据对步骤s3构建的易逝品订货模型进行优化求解,具体包括:
对步骤s2采集的历史需求数据d=(d1,d2,...di,...,dn)按照从小到大顺序排列,得到序列d(1)<d(2)<...<d(i)<...<d(n);
将数据驱动的易逝品订货模型目标函数转换为:
比较决策变量q与每个d(i)的大小,求解目标函数得到最优订货量q*。
作为上述易逝品订货方法的进一步改进,所述步骤s5中构建需求数据更新后的数据驱动的易逝品订货模型,具体包括:
在步骤s2采集的n个历史需求数据的基础上增加n个新的需求数据,通过n+n个需求数据的均值估计随机需求的期望,得到需求数据更新后的数据驱动的易逝品订货模型,表示为
其中,qn为需求数据更新后的数据驱动的易逝品订货模型的决策变量。
作为上述易逝品订货方法的进一步改进,所述步骤s5中对需求数据更新后的数据驱动的易逝品订货模型进行优化求解,具体包括:
对需求数据更新后的历史需求数据d=(d1,d2,...dn,...,dn+n)按照从小到大顺序排列,得到序列d(1)<d(2)<...<d(n)<...<d(n+n);
将数据驱动的易逝品订货模型目标函数转换为:
比较决策变量qn与每个d(i)的大小,求解目标函数得到最优订货量
本发明具有以下有益效果:
(1)本发明从历史需求数据入手,直接跳过了模型驱动中模型假设与分布拟合,不仅大大减少了管理者处理选取和拟合模型的繁琐工作,也解决了真实需求分布获取难和需求分布随时间改变的难题;
(2)本发明通过构建数据驱动的易逝品订货模型,提高了决策者订货决策的精准度;
(3)本发明通过构建数据驱动的易逝品订货模型,发现最优订货决策仅仅依赖历史需求数据的正确排序,而序列角标由样本个数n、单位缺货损失cu和单位过剩损失co所决定,因此这一结果更具有现实意义。
附图说明
图1是本发明的数据驱动的易逝品订货方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
参照图1,本发明实施例提供了一种数据驱动的易逝品订货方法,包括步骤s1至s5:
s1、设定易逝品订货相关变量。
在本实施例中,易逝品订货相关变量包括订货量q、单位订货成本c、单位零售价p、单位缺货成本s、单位残值v、单位缺货损失cu(机会成本)和单位过剩损失co。
下面对易逝品订货相关变量的具体含义进行说明:
订货量q指决策者向上游供应商订购产品的数量;
单位订货成本c指决策者向上游供应商订购产品的单位价格;
单位零售价p指决策者向下游消费者销售产品的单位价格;
单位缺货成本s指决策者没有满足消费者需求时受到的单位缺货损失;
单位残值v指决策者满足消费者需求后剩余产品的单位价值;
单位缺货损失cu指决策者没有满足消费者需求时不仅会受到此次的单位缺货成本s,还会受到潜在p-c的利润损失,即cu=p+s-c;
单位过剩损失co指决策者满足消费者需求后剩余产品会造成c-v的损失,即co=c-v。
s2、采集消费者的历史需求数据。
在本实施例中,本发明采用数据驱动的方法,从历史需求数据入手,采集设定周期不同情形下消费者的真实历史需求数据,即当天之前n天内消费者每天的需求量d,表示为
d=(d1,d2,...di,...,dn)
其中,di表示第i天的需求量。
本发明采集的历史需求数据在一定程度上能够反映需求的变化趋势,从而为决策者做出最优决策提供有效信息。
本发明从历史需求数据入手,不需要提前设定需求必须符合正态分布、t分布或者其他诸如此类的分布假定,直接跳过了模型驱动中模型假设与分布拟合,这不仅大大减少了管理者处理选取和拟合模型的繁琐工作,也解决了真实需求分布获取难和需求分布随时间改变的难题。
s3、构建单周期期望总收益函数,以单周期期望总收益最大化为优化目标,构建数据驱动的易逝品订货模型。
在本实施例中,当需求为随机变量时,得到单周期期望总收益函数表示为e[π(q,d)]=e[pmin(q,d)+vmax(0,q-d)-smax(0,d-q)-cq](1)
其中,e[π(q,d)]为单周期期望总收益函数,q为数据驱动的易逝品订货模型的决策变量,d为决策者面临的随机需求。
等价于
e[π(q,d)]=e[(p+s-c)q-(p+s-v)max(0,q-d)-sd](2)
再以单周期期望总收益最大化为优化目标,通过当天之前n天历史需求数据的均值估计随机需求的期望,构建数据驱动的易逝品订货模型,表示为
s4、基于步骤s2采集的历史需求数据对步骤s3构建的易逝品订货模型进行优化求解。
在本实施例中,上述优化求解过程具体包括:
对步骤s2采集的历史需求数据d=(d1,d2,...di,...,dn)按照从小到大顺序排列,得到序列d(1)<d(2)<...<d(i)<...<d(n);
将数据驱动的易逝品订货模型目标函数转换为:
通过对历史需求数据排序,本发明提出的数据驱动方法只需要比较决策变量q与每个d(i)的大小,便能求解目标函数得到最优订货量q*。
下面针对决策变量q取值范围分情况进行详细说明。
如果d(j)≤q≤d(j+1),那么目标函数(4)等价于
由于
如果q≤d(1),那么目标函数(4)等价于
由于
如果q≥d(n),那么目标函数(4)等价于
由于
综上所述,如果
等价于
q*=d(j),其中
本发明得到的最优订货决策具有解析解,且仅仅依赖历史需求数据的正确排序。序列角标由样本个数n、单位缺货损失cu(机会成本)和单位过剩损失co所决定,因此这一结果更具有现实意义。
s5、构建需求数据更新后的数据驱动的易逝品订货模型并进行优化求解。
在本实施例中,构建基于优化求解需求数据更新后的数据驱动的易逝品订货模型,具体包括:
在步骤s2采集的n个历史需求数据的基础上增加n个新的需求数据,通过n+n个需求数据的均值估计随机需求的期望,得到需求数据更新后的数据驱动的易逝品订货模型,表示为
其中,qn为需求数据更新后的数据驱动的易逝品订货模型的决策变量。
然后采用与步骤s4类似的基于历史需求数据进行易逝品订货模型的优化求解方法,具体包括:
对需求数据更新后的历史需求数据d=(d1,d2,...dn,...,dn+n)按照从小到大顺序排列,得到序列d(1)<d(2)<...<d(n)<...<d(n+n);
将数据驱动的易逝品订货模型目标函数转换为:
更新需求数据后,仍然可以只通过比较决策变量qn与每个d(i)的大小,求解目标函数得到最优订货量
然后参照步骤s4,分别讨论d(j)≤qn≤d(j+1),qn≤d(1)和qn≥d(n+n)三种情况,求解得到
可以得出更新数据后的数据驱动的易逝品订货模型仍然具有解析解,并且由于样本个数的增加使得最优决策的排序位置向后移动。
本发明采用数据驱动方法直接从需求数据出发,对需求数据进行分析处理,挖掘数据背后所蕴含的价值;并且本发明的数据驱动方法从管理决策范式进行创新,具有动态性、开放性和连续性的优势,为易逝品订货管理研究带来了新的视角与方法。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!