一种基于人脸语义特征约束卷积网络的眼镜检测方法与流程
本发明涉及计算机视觉的目标检测领域,尤其涉及一种基于人脸语义特征约束卷积网络的眼镜检测方法。
背景技术:
在人像采集的日常工作中,需要对采集照片进行质量核审,检测是否佩戴眼镜等饰物是照片质量检测中的重要一环。传统的检测算法对眼镜检测效果不佳,同时人工方式审核人员照片是否佩戴眼镜耗时耗力,人像大小等因素都影响人像照片的眼镜检测无法达到检测预期目标。
从已有发明来看,目前发明主要采用传统的眼镜检测和深度学习方法,检测准确率需要进一步提高。传统算法例如cn102163288a先从需要检测的人像照片中定位眼镜区域图像,使用单眼区域分类器对眼镜区域进行第一判别,根据判别结果的绝对值与预设阈值的大小关系进行分析,若结果绝对值大于阈值,则输出眼镜检测结果,反之则使用双眼区域分类区对眼镜区域进行第二判别,根据此判别结果判断是否佩戴眼镜,最终得到眼镜检测的结果。该发明对初始的人脸位置要求较低,一定程度上提高了眼镜检测的精度。cn106778451a该发明提出了一种面部识别的眼镜检测方法,先使用人脸检测方法对图像进行检测得到人脸区域,在此基础上进行眼镜定位得到眼镜区域位置,并根据该位置对人脸区域图像进行归一化操作来得到预设尺寸大小的目标图像,通过使用特征分类器对眼镜区域图像分类,得到是否配戴眼镜的检测结果。cn106503611a该发明是关于一种基于边缘信息投影定位镜架横梁的人脸图像眼镜检测方法,利用人脸图像定位人脸嘴部区域,镜架横梁中心水平方向位置由嘴部区域确定,镜架横梁中心垂直方向位置由人脸图像边缘信息图的像素横向投影情况来确定,根据水平和垂直两者方向位置定位镜架横梁区域,根据横梁区域的横线长度判断是否配戴眼镜,若横线长度与镜架横梁区域水平方向长度近似相等,则佩戴眼镜,反之,未戴眼镜。该发明需要的特征信息少,相对其他方法更加简捷,能有效检测人脸图像是否佩戴眼镜。也有基于深度学习的眼镜检测方法,例如陈文青等人基于眼睛区域的边缘特征提出一种基于神经网络的眼镜检测方法,考虑到眼镜边框与周围像素对比度明显,提取眼睛区域的边缘特征。使用bp神经网络进行模型训练,对人脸图像进行边缘检测和特征提取,利用训练好的模型进行判断人脸图像是否佩戴眼镜。
另外一方面,卷积网络在目标检测中得到了广泛的应用。和传统的bp神经网络相比较,卷积网络在目标检测准确率提到了明显的提升。尽管已有研究对目标检测做了大量的研究,提出了一系列算法。例如fast-rcnn在提取objectproposals的基础上,利用卷积网络实现一种多任务学习方式,对目标分类和包围框回归进行同步训练。例如faster-rcnn设计了候选区域生成网络即rpn,将objectproposal检测算法也加入到深度卷积网络中实现,是端到端的深度学习算法。yolo则直接将整张图像作为网络的输入,仅通过一次前向传播直接得到目标包围框的位置和目标类别,检测速度快,但是检测效果特别是小目标检测效果稍差。ssd借鉴了多参考窗口技术,分别在多个尺度的特征图上进行检测和包围框回归。但是,这些卷积网络应用于眼镜检测时,由于眼镜目标较小、半框和无框眼镜的特征难以获取等原因导致检测准确率不高,存在明显的漏检等问题。
技术实现要素:
本发明为克服上述的不足之处,目的在于提供一种基于人脸语义特征约束卷积网络的眼镜检测方法,本发明针对structureinferencenet存在的场景区域不准确问题,提出通过结构推理网络充分利用人脸区域和其他区域的特征信息来提高后续区域的可靠性。由于人脸与眼镜的相对位置稳定,可将人脸或附近区域视为眼镜所处的场景,眼镜与人脸等目标之间也有一定的联系,结合场景和物体间的联系可以提高眼镜检测的精度。提出的眼镜检测卷积网络利用人脸场景信息和眼镜之间的内在语义关联性性建立推理模型,可以大大提高眼镜检测的准确率;解决了现有目标检测技术存在的未充分、合理利用图片场景信息的问题。
本发明是通过以下技术方案达到上述目的:一种基于人脸语义特征约束卷积网络的眼镜检测方法,包括:
(1)初始训练数据采集及标注,得到带标签的训练集;
(2)人脸语义特征约束下的眼镜检测卷积网络模型的构建,并基于训练集进行训练模型;
(3)基于训练好的人脸语义特征约束下的的眼镜检测卷积网络模型进行眼镜检测,实现对人像照片的眼镜检测。
作为优选,所述步骤(1)具体如下:
(1.1)利用人工拍照、人工从网络或者其他开源人脸数据集中搜集戴眼镜人像照片,对采集图像进行人工标注,其中眼镜区域为xmin,ymin,xmax,ymax四个坐标,代表眼镜区域,得到初始部分训练集cs1;(1.2)选取若干副眼镜图片,使用抠图方法得到眼镜的png图,并人工标注眼镜区域,标注方法同步骤(1.1)的标注方法,选择人像照片,标注双眼位置,并根据双眼的中心宽度和与水平系的夹角,将眼镜png图合成到人像图片上,得到得到初始部分训练集cs2;
(1.3)经过上述步骤得到带标签的初始训练集cs=cs1+cs2。
作为优选,所述步骤(2)具体如下:
(2.1)使用官方在imagenet图像库上训练好的模型作为眼镜检测的预训练模型,在此基础上进行微调;
(2.2)人脸语义特征约束下的眼镜检测卷积网络模型由faster-rcnn网络和结构推理网络混合构成,其中由faster-rcnn的rpn方法生成固定数量的roi,经过roi-pooling得到特征向量并映射成一个节点作为结构推理网络sin的初始状态sin;
(2.3)根据步骤(2.2)中由rpn生成的固定数量roi区域,以每一个roi区域的宽高和中心点为基准,分别选取宽度和高度为rw倍和rh倍的区域作为该roi区域的场景,经过vgg16、roi-pooling等层作为sin的场景输入ins;
(2.4)根据步骤(2.2)中由rpn生成的固定数量roi区域,每两个roi的联系信息,作为结构推理模型的边缘信息输入ine,共十二维;
i,k代表两个roi区域;
(2.5)利用结构推理网络sin对sin推理,推理结构初始场景和边缘gru状态都为sin,ins是场景输入,ine是边缘信息输入,sout是推理结果,即推理输出;
(2.6)推理结果使用softmax进行分类,使用bounding-boxregression边界框回归;其中,模型目标函数为
其中pi为anchor预测为目标的概率,
(2.7)利用梯度下降方法对步骤(2.6)中的目标函数进行优化。
作为优选,所述步骤(3)具体如下:
(3.1)将测试图片输入到训练好的网络模型中,得到测试图片的目标分类和定位;
(3.2)进行统计分析,统计输出目标被正确分类和定位的准确率,以map为标准;得到最终模型的正确检测效果。
本发明的有益效果在于:本发明根据图片中眼镜目标区域的粗略位置即选取特定位置的场景,即人脸背景,提取这部分的关键特征信息作为结构推理网络的场景输入;这种处理方法使结构推理网络能合理获取到准确的场景信息,提升推理效果,提高眼镜检测精度;构建人脸语义特征约束下的眼镜检测卷积网络模型,根据眼镜目标的尺寸和位置选取特定位置的场景信息作为结构推理网络的场景输入,舍弃了图片的多余信息,保留最关键信息,在经过roi-pooling后,最大程度保留了眼镜目标的最关键场景信息,提高推理效果,提高本发明的实际应用价值;本发明设计充分利用人脸语义信息有效提高眼镜的检测精度。
附图说明
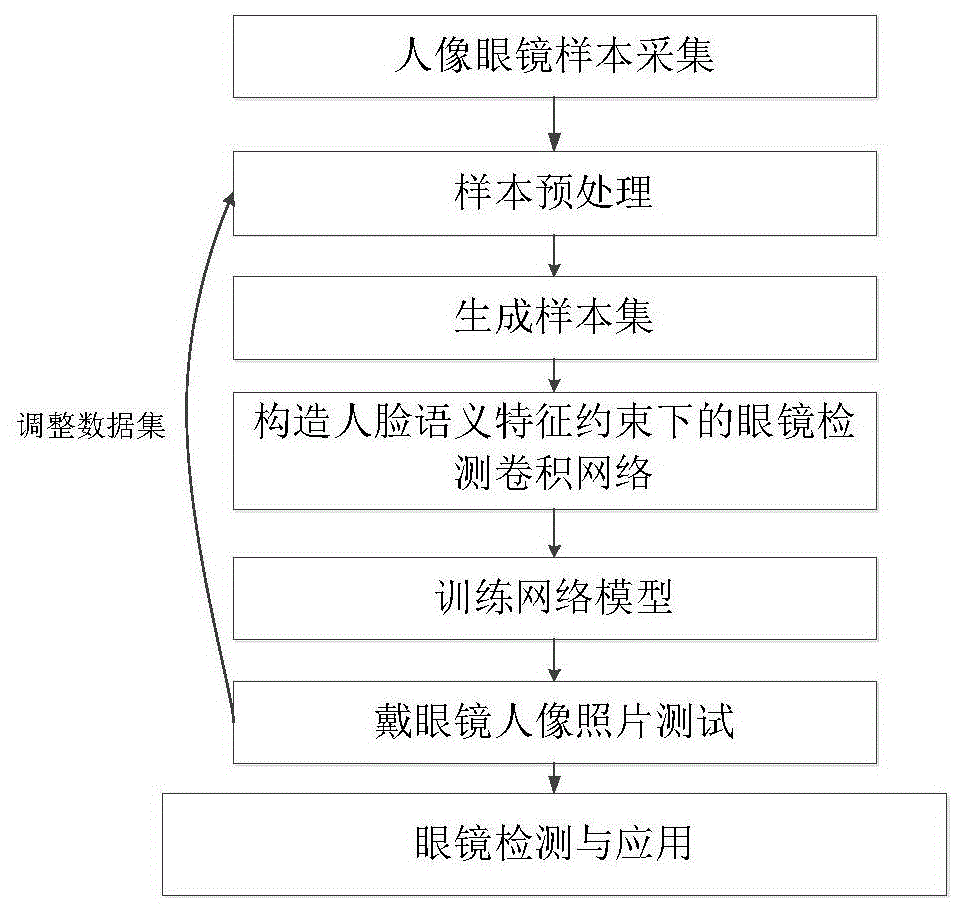
图1是本发明的方法流程示意图;
图2是本发明实施例的结构推理网络示意图。
具体实施方式
下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此:
实施例:本实施例中,人像戴眼镜图片内容定义为:个人半身或全身正面戴眼镜照片。以眼镜目标为正样本,其余为负样本。由于人工收集样本图像具有周期长、数量少、成本高等特点,不能完全满足模型训练需要的大量样本图像,因此需要采取其他方法进行样本图像的增强处理,能在一定程度上提高模型训练的识别率。
如图1所示,一种基于人脸语义特征约束卷积网络的眼镜检测方法,包括如下步骤:
步骤一、初始训练数据采集及标注;
步骤1.1:利用人工拍照、人工从网络或者其他开源人脸数据集中搜集大量戴眼镜人像照片,约2000张;
步骤1.2:选取若干副眼镜图片,使用抠图方法得到眼镜的png图,并人工标注眼镜镜片区域。
步骤1.3:搜集大量人像照片,人工标注双眼位置,用于之后的图像合成计算。
步骤1.4:对所有样本图像进行预处理。由于采集的样本来自不同的网站平台,存在规格大小不一,附带水印等问题。对网络收集图片,利用人工方式进行裁剪去除水印,并使用python代码将图片缩放至长宽500像素以下,约2000张(戴眼镜与无眼镜比例大致为1:1)。对人像照片,根据眼镜镜片和人像眼睛的标注计算双眼的中心宽度和与水平系的夹角,将眼镜png图合成到人像图片上,生成图片以及眼镜变换后的坐标框,约3000张合成图。
步骤1.5:经过上述步骤将网络样本集cs1和合成样本集cs2组成训练集。
步骤二、人脸语义特征约束下的眼镜检测卷积网络模型的构建及训练;
步骤2.1:本方法基于tensorflow深度学习框架,以faster-rcnn检测网络为基础,融合结构推理网络sin来构建人脸语义特征约束下的眼镜检测卷积网络模型;
步骤2.2:结构推理网络的初始化,由faster-rcnn的rpn方法生成128个roi区域,提取这些roi区域的特征,并经过roi-pooling、fc等层得到特征向量并映射成一个节点作为结构推理网络sin的初始状态;
步骤2.3:场景的选择,对每一个roi区域,以原roi中心点位置为初始位置,以原roi区域长宽为基准,选取高度和宽度分别为rh和rw倍的区域,根据图片左上角为原点建立坐标轴,原始roi区域的坐标为:xc1,yc1,w1,h1,其中xc1和yc1为roi中心坐标,w1和h1分别为roi区域的宽度和高度.选择的场景区域为:xc2=xc1,yc2=yc1,w2=rww1,h2=rhh1其中xc2和yc2为场景区域中心坐标,w2,h2分别为场景区域的宽度和高度,超过边界的部分按图片最大或最小长宽值处理.由于人脸和眼镜相对位置稳定,可以从眼镜推断出大致的人脸位置,以人脸位置为眼镜目标的场景最为适合,因此令rh和rw取值为7和2。
步骤2.4:结构推理网络的场景输入,提取经过场景选择后的场景特征,128个roi区域与128个场景区域特征一一对应,并经过roi-pooling、fc等层得到特征向量并转化成一个向量作为结构推理网络sin的场景输入。
步骤2.5:结构推理网络的边缘信息输入,对于物体vi,其他物体vk传递给vi的消息是
其中xi和yi是roi区域bi的中心,wi和hi是bi的宽度和高度,si是bi的面积。
步骤2.6:结构推理网络,如图2所示;使用场景gru和边缘gru,原始图像提供两个gru的初始状态,场景选择为场景gru提供输入,roi之间的空间关系为边缘gru提供输入,场景gru和边缘gru的输出进行一次meanpooling平均池化操作,得到最终的gru输出结果,即最终的推理输出。推理输出使用softmax进行分类,使用bounding-boxregression边界框回归。
步骤三、基于眼镜检测卷积网络模型的眼镜检测;
步骤3.1:将测试图片输入训练好的最终网络模型,得到测试图像的目标分类和定位;
步骤3.2:对测试图片做统计分析,统计输出目标被正确分类和定位的准确率,以map为标准,得到模型的检测效果。
经过上述步骤的操作,即可实现对人像照片的眼镜检测。
以上的所述乃是本发明的具体实施例及所运用的技术原理,若依本发明的构想所作的改变,其所产生的功能作用仍未超出说明书及附图所涵盖的精神时,仍应属本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!