一种基于改进关联规则的社团发现算法的制作方法
本发明涉及一种基于改进关联规则的社团发现算法。
背景技术:
随着大数据时代的到来,无线城市的建设也逐步完善。复杂网络研究一直是社会研究的热点,社团发现对研究复杂网络有重要的作用。在海量数据中挖掘无线城市存在的社团关系成为新的挑战。
针对传统社团发现算法,提出了将社团发现算法和关联规则相融合的混合算法,改进的算法提高了社团发现的准确度,但改进的算法又引入了关联规则算法的缺点,提高搜索时间、降低搜索效率。马威等提出利用有向无权图改进社团发现的cs算法,改进算法在挖掘社团的时间空间方面都得到显著的提高,但算法在权重排序后产生大量团冗余并且该算法发现的成员关系较强,在现实生活不一定成立。张燕等提出利用二叉树结构改进社团发现算法,并将mapreduce和二叉树相结合改进社团发现算法,实现算法的并行化,解决了处理海量数据时效率低,数据溢出的问题,但mapreduce在进行迭代时,需要频繁扫描磁盘,增加计算时间。yangqinliu等提出利用矩阵改进关联规则,该算法解决了传统关联规则算法频繁扫描事务数据集的缺点,提高了运算效率,但该算法在处理海量数据时,消耗大量时间。王雪平等提出apriori算法支持度置信度自适应的思想,该算法解决了人为设置支持度和置信度时存在主观性和、无科学依据的问题,但算法并没有解决传统apriori算法存在的缺点。
技术实现要素:
基于以上现有技术的不足,本发明所要解决的问题在于提供一种基于改进关联规则的社团发现算法,结合支持度自适应的思想和利用权重生成布尔矩阵的方法改进apriori算法,并在spark平台上将改进的算法和社团发现算法相融合的arcd算法。
为了解决上述技术问题,本发明通过以下技术方案来实现:
本发明提供一种基于改进关联规则的社团发现算法,包括以下步骤:
s1:支持度自适应,用数学方法计算出最小支持度;
s2:引入布尔矩阵和事务权重思想改进apriori算法,减少扫描数据库次数;
s3:与spark平台结合,实现改进关联规则的社团发现算法并行化。
可选的,所述步骤s1中,对apriori算法进行优化:
s11、对事务数据集d中的每一项进行支持度计数,并从大到小排序;
s12、根据数据对进行k次项多项式曲线拟合。
可选的,所述步骤s2中,针对apriori算法频繁扫描事务数据,生成候选集冗余问题,arcd算法利用权重和布尔矩阵进行“与”操作得到候选项集的方法改进apriori算法。
进一步的,所述步骤s3包括以下步骤:
s31、扫描数据集生成频繁1项集l1,将结果存储在hdfs上,将存储在hdfs上的数据集看作一个rdd,并将rdd划分为n块,分给m个work节点;
s32、构造局部矩阵,计算局部矩阵的支持度计数
s33、利用reducebykey操作,合并局部频繁项集,得到全局候选项集。
由上,本发明基于关联规则改进的社团发现算法存在候选结果以及生成结果大量冗余、时间复杂度高的问题,提出了一种基于改进关联规则的社团发现arcd(acommunitydetectionalgorithmbasedonimprovedassociationrules)算法。该算法通过利用mac地址挖掘社团成员,引入支持度自适应的思想和通过添加事务权重生成布尔矩阵的方法来改进apriori算法,将改进的算法与spark结合实现算法的并行化,通过挖掘频繁项集的方式挖掘社团成员间的关系。实验结果表明,arcd算法解决了人为设置支持度的主观性及社团挖掘结果冗余的问题,具有良好的可扩展性,提高了社团发现的挖掘速度。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下结合优选实施例,并配合附图,详细说明如下。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例的附图作简单地介绍。
图1为cs算法流程图;
图2为mp-t-cs算法流程图;
图3为sacs流程图;
图4为支持度自适应流程图;
图5为改进apriori算法流程图;
图6为改进apriori算法在spark上运行流程图;
图7为五种算法在不同数据量下的运行时间图;
图8为两算法在不同集群数下加速比的比较图;
图9为arcd算法在不同数据量下的加速比变化图。
具体实施方式
下面结合附图详细说明本发明的具体实施方式,其作为本说明书的一部分,通过实施例来说明本发明的原理,本发明的其他方面、特征及其优点通过该详细说明将会变得一目了然。在所参照的附图中,不同的图中相同或相似的部件使用相同的附图标号来表示。
本文提出了结合支持度自适应的思想和利用权重生成布尔矩阵的方法改进apriori算法,并在spark平台上将改进的算法和社团发现算法相融合的arcd算法。实验结果表明,arcd算法在处理海量数据时,运行时间快,计算效率高,在挖掘社团成员关系时,有良好的并行性。
社团发现的核心是指找出参与社团活动的用户与用户直接的关系。无线城市,是使用高速宽带无线技术覆盖城市行政区域,向公众提供利用无线技术随时随地获取信息的服务。mac地址:即物理地址,用来确认网上设备位置。mac地址具有唯一性。
关联规则:形式如x→y,其中x是先导项集,y是后继项集,且x∩y≠φ。
事务:表1中的每行为一个事务。
项:表1中的每列为一个项。
表1购物篮数据的二元表示
项集:包含0个及多个的项的集合称为项集。
支持度计数:事务中包含项集的总数。
支持度:用来确定某一项集是否频繁。定义如公式(1)
频繁项集:大于支持度阈值的项集。
二阶导数:对原函数y=f(x)进行两次求导,二阶导数为0的点可能是极值点。
曲线拟合:是指选择适当的曲线类型来拟合观测数据,并用拟合的曲线方程分析两变量间的关系。
决定系数:决定系数用r2表示,用来衡量模型的拟合度。
spark是2009年加州大学伯克利分校rad实验室设计的可以进行交互式查询和迭代计算的操作引擎。它能够在内存中计算,具有高效的容错机制。spark扩展了mapreduce模型,运行速度是hadoop中mapreduce的100倍,相比与hadoop适合处理非实时的海量数据,spark更适合处理实时数据。它支持更多的计算模型(如交互式查询、流处理)。弹性分布数据集(rdd)是spark的核心数据结构,是一个可并行操作的容错集合,主要包括转换操作和行动操作。
基于团搜索(cs)的社团发现
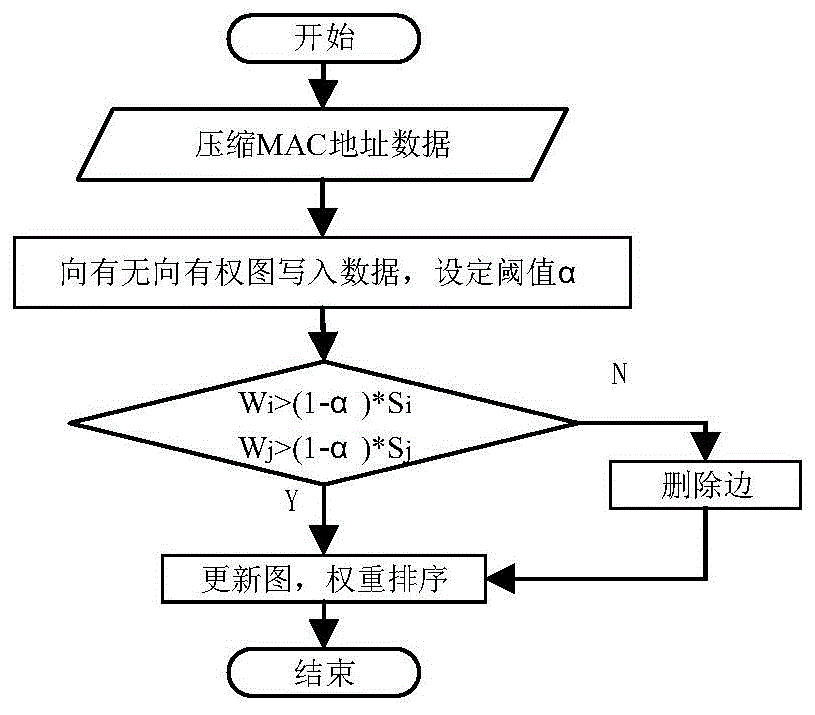
cs算法利用无向有权图改进的社团发现算法,cs算法将原始数据中mac地址压缩,整理后mac数据作为图的顶点v,如果maci(记为vi)和macj(记为vj)出现在同一场所或有相同的ap,则用边e连接,记(eij),且设边的权值wij=1。将mac地址依次映射到图中,每出现eij,则wij加1。直到处理完所有的mac地址。权重较大边组成的团,就是cs算法找到的社团,算法流程图如图1所示。
算法缺点:cs算法由于对所有顶点的边一一排序导致边冗余,由边生成团导致团冗余。cs算法挖掘出权重值高的团,表示两成员之间有较强的关系,但现实生活中,成员之间的关系往往不如算法得到的那么强。
基于mapreduce的t-cs算法
mp-t-cs算法是将t-cs算法应用在hadoop的mapreduce平台上,使用特殊的二叉树实现团搜索算法的并行化。mp-t-cs算法首先将原始mac数据以特殊二叉树的形式存储,将二叉树转换为文本储存,对文本数据进行map和reduce操作,生成(key,value)键值对。再对键值对进行权重k选择排序。最后对排序后的图进行深度优先搜索遍历得到极大连通图。极大连通图就是mp-t-cs算法找到的社团,算法流程图如图2所示。
算法缺点:虽然m-t-cs算法无论在整体和还是局部方面挖掘效果都优于cs算法,提高了时间和空间性能,但由于m-t-cs算法是基于mapreduce的并行化计算,将运行结果存储在hdfs文件中,每次使用都要从磁盘中读取,大量的迭代计算增加了运行时间。
基于spark的acs算法
sacs算法主要通过spark的分布式计算来实现apriori算法的并行化。sacs算法首先将数据集存储在hdfs中,将生成的rdd划分为n块用来处理切分的数据集,对生成的(key,value)键值对处理,得到n个局部频繁项集,对局部频繁项集进行reduce操作,得到全局候选项集,在对全局候选项集进行切片,生成新的(key,value)键值对,统计全局支持度计数,与最小支持度比较,过滤不符合条件的项集,得到全局频繁项集,输出社团成员集合,算法结束,算法流程图如图3所示。
算法缺点:sacs算法在spark上并行化处理apriori,解决了基于hadoop计算时频繁扫描磁盘的缺点。但sacs算法没有解决传统apriori算法的缺点,首先需要自设支持度阈值,其次sacs算法仍需多次扫描数据库,消耗了运算时间。
acdr算法
arcd算法:acommunitydetectionalgorithmbasedonimprovedassociationrules。arcd算法通过无线城市中mac地址事务数据来获取社团成员所在的位置数据。首先,针对apriori算法支持度大多数凭经验设置,arcd算法结合自适应支持度的方法,用科学的方法求apriori算法中的最小支持度。其次,针对apriori算法频繁扫描数据库的缺点,利用事务权重和布尔矩阵改进算法生成频繁项集。最后,针对hadoop每次处理数据后都将运算结果写入磁盘的缺点,提出了将改进的算法应用在社团发现,并结合spark平台实现并行化。
数据预处理
针对数据量过大,不能很好的体现用户之间的共现模式,提出了对mac地址进行时间空间(场所)压缩的处理方法。表2为原始数据,其中service_code表示接入场所编号、ap_mac表示接入的ap地址、user_mac代表用户的mac地址,time代表接入时间。
表2原始mac地址数据集
mac地址预处理的原则是,将相同ap地址,或2分种以内出现为依据进行数据压缩。对表2中数据压缩后得到表3。
表3mac地址事务数据
用改进的apriori算法来寻找mac的频繁项集,寻找频繁项集这一过程称为社团发现。数据压缩处理后,将mac地址等价成in,例如mac1=i1。其中in代表项,tn代表事务。频繁项集里的各项macn(in)地址的拥有者就是社团成员。例如算法最终得到频繁三项集{i1,i2,i3},它们对应mac地址{mac1,mac2,mac3},而mac地址对应的社团成员是{1,2,3}。所以我们得出结论用户1,2,3属于同一社团。
基于apriori算法的改进
针对传统的apriori算法由于频繁迭代导致计算效率低的问题,本文从以下三个方面对apriori算法进行优化:一、支持度自适应,用数学方法计算出最小支持度。二、引入布尔矩阵和事务权重思想改进apriori算法,减少扫描数据库次数。三、与spark平台结合,实现改进关联规则的社团发现算法并行化。
支持度自适应
支持度自适应是指对自身数据分析统计,通过对递减排列支持度计数进行的k项式曲线拟合,找到拟合曲线二阶导数为0的点作为min_sup。支持度自适应首先对事务数据集d中的每一项进行支持度计数,并从大到小排序。根据公式(2)建立“支持度-序号”的集合。
{(x,y)}={(1,v1),(2,v2),...,(i,vi)}(2)
公式(2)中vi表示将从大到小排序后的支持度赋值给v1,v2,...vi。i是事务d中项的总数。通过数据对(i,vi)建立平面坐标系。根据数据对进行k次项多项式曲线拟合,拟合的多项式曲线如公式(3)。
k值从第2次后,每次加1。通过公式(4)来判断k的取值。
rk2可决系数,取值[0,1]。rend=0.05为终止条件。当公式(3)成立时,k值加1,直到公式(4)不成立,停止循环。求当前k项多项式的二阶导数,公式如(5)。
最后二阶导数为0的点x0就是min_sup。此时当1<x0<2时上取整为2,当x0>2时下取整,执行流程图如图4所示。
支持度自适应伪代码如下:
算法1支持度自适应
输入:事务数据集t,rend。
输出:min_sup。
1:c1=find_candidate_1-itemsets(d)
2:forc∈c1do
3:δ(c)=δ(c)+1//支持度计数
4:l1=dec_sort(c)//支持度递减排序
//自适应求多项式拟合曲线的次数k
5:k=find_k_mult_curve_fitting(l1)
6:f(x)=mult_curve_fitting(l1,k)//k次多项式曲线
7:wheref"(x0)=0
8:if1<x0<2
9:x0=round(x0)//向上取整x0
10:elsex0=trunx(x0)//向下取整x0
11:min_sup=x0
基于事务权重和矩阵的apriori
针对apriori算法频繁扫描事务数据,生成候选集冗余等问题,arcd算法利用权重和布尔矩阵进行“与”操作得到候选项集的方法改进apriori算法,通过只扫描一次数据库来提高算法的运算效率。
布尔矩阵:元素只取0或1的矩阵。
定理1:如果两个频繁的k-1项集可以连接生成k项集,那么它们的k-2项集的项必须是相同的。
定理2:如果一个项集是频繁的,那么它的所有子集也必须是频繁的。反之,如果一个项集不频繁,那么它的所有超集一定不是频繁的。
将包含事务m,项集n的数据项目集d映射到如式(6)所示的布尔矩阵。
其中
arcd算法引入权重公式sup_count(i)=wti。其中sup_count是项的支持度计数。wt是事务t的权重,i是事务矩阵的列向量。算法初始化wt={1,1,...,1}。当我们扫描事务t时,发现重复事务,权重加1并删除重复项。将处理后的新事务更新布尔矩阵,删除为0的事务和支持度小于最小支持度的项。再对每列进行“与”操作,得到候选k+1项集。重复上述工作,直到找不到频繁项集算法结束。改进的apriori算法流程图如图5所示。
改进apriori算法伪代码如下:
算法2频繁项集的获取
输入:事务数据集t,min_sup,t=1,wt={1,1,…1}。
输出:频繁t项集。
改进apriori算法并行化实现
arcd算法是基于事务权重和矩阵来改进apriori算法,只需要扫描1次数据集,并与spark操作引擎结合,实现算法的并行化,提高运算速度。arcd算法在spark中的运算过程:首先扫描数据集生成频繁1项集l1,将结果存储在hdfs上,将存储在hdfs上的数据集看作一个rdd,并将rdd划分为n块,分给m个work节点。其次,构造局部矩阵,计算局部矩阵的支持度计数。对局部矩阵的每一列进行“与”操作得到局部候选项集。删除支持度小于最小支持度的项和全为0的事务,得到局部频繁项集。最后,利用reducebykey操作,合并局部频繁项集,得到全局候选项集。计算全局支持度,过滤小于最小支持度的列(项集)和全为0的行(事务),得到矩阵的全局频繁项集。将频繁项集等价成mac地址,并得到拥有这些mac地址的成员集合。改进的apriori算法在spark上运行的流程图如图6所示。
算法举例
为了更清晰的解释arcd算法的主要思想,对如表4所示的事务数据集进行举例分析。
表4事务数据集t
扫描事务数据集t,对候选项集的各项进行支持度计数,从小到大排列支持度,利用公式(2)得到数据,并建立坐标对表,如表5所示。
表5各项支持度和项号排序表
利用表中的各个点坐标绘制坐标系,根据公式(3)和公式(4)进行曲线拟合,求得k=4,数据集t的支持数拟合曲线如式(6)所示:
ft=-0.16667x4+1.833x3-6.833x2+9.167x+3(6)
求函数ft二阶导数为0的点,ft的二阶求导如公式(7)所示:
ft”(x)=-2.0004x2+10.998x-13.666(7)
令ft”(x)=0,求得x0=2,所以数据集t的最小支持度为2。将事务数据集t映射到布尔矩阵,其中每一行代表一个事务,每一列代表一个项。如果某一项在事务中存在,对应的位置为1,否则为0,生成的布尔矩阵rt。
根据事务数据集t看出,事务t4和t5重复交易,所以权重为wt={1,1,1,2,1,1,1,1,1}。计算矩阵每一列的支持度计数,例如sup_count(i1)=wti1=0+0+1*1+1*2+1*1+0+0+0+1=5。即i1的支持度为5,而最小支持度为2,所以项i1是频繁的。同样求出其他项的支持度,可以看出,所有项的支持度都大于最小支持度阈值,所以频繁1项集为{i1},{i2},{i3},{i4},{i5},再对每一列做“与”操作得到候选二项集r2。
可以看出事务t9全为0,根据定理2,删除t9,求候选二项集中每一项集的支持度计数。如sup_count(i1,i2)=wt(i1i2)=0+0+1+0+1+0+0+0=2,sup_count(i3,i5)=wt(i3i5)=0+0+1+0+0+0+0+0=1,二项集i1i2的支持度为2,所以二项集i1i2是频繁的。可以看出二项集i3i5的支持度为1小于最小支持度2,删除i3i5所在的列。计算所有项集的支持度,得出频繁2项集为{i1i2},{i1i3},{i1i4},{i1i5},{i2i4},{i2i5},{i3i4},{i4i5},根据定理1对频繁项集的列进行连接和“与”操作。得到候选三项集r3。
可以看出事务行t2,t7,t8,t10全为0,根据定理1,删除这三行,计算每一列的支持度计数。其中sup_count(i1,i2,i4)=1,sup_count(i1,i2,i5)=1,sup_count(i1,i3,i4)=1,sup_count(i2,i4,i5)=1,这些三项集的支持度都小于最小支持度2,将不满足min_sup的三项集删除,所以频繁3项集为{i1i2i3},{i1i4i5},{i2i3i4}。由定理1可知,无法连接和进行“与”操作得到候选四项集,所以算法结束。
综上分析,频繁项集{i1i2i3},{i1i4i5},{i2i3i4}满足要求。将项ii转换成mac地址,得到频繁三项集的{mac1,mac2,mac3},{mac1,mac4,mac5},{mac2,mac3,mac4}。所以拥有上述mac地址的用户,即用户1,用户2,用户3为同一社团成员。用户1,用户4,用户5为同一社团成员。用户2,用户3,用户4为同一社团成员。
实验验证与分析
实验环境
本实验搭建包括1个master主节点,7个slave从节点的spark集群。集群节点配置如下:linux操作系统、centos7.3、scala2.11.8、jdk1.8、hadoop2.7.3、spark2.1.1。
实验对比
为了验证本文arcd算法的有效性,采用uci数据集生成的mac地址样本如表6所示。
表6数据集特征信息统计
为了验证算法挖掘数据结果的准确性。使用d1,d2数据集比较cs算法、mp-t-cs算法、apriori算法、sacs算法、arcd算法在挖掘数据结果准确度。设min_sup=20%,δ=0.05。n()代表挖掘后mac地址数量。实验结果如表7所示。
表7数据集挖掘结果对比
由表7可以看出,arcd算法与传统的apriori算法和在spark上并行化sacs算法挖掘到mac地址数量和质量相同,说明相对于cs算法和mp-t-cs算法,本文算法挖掘社团成员的准确性更高。
为了验证算法的计算效率,算法选取d1~d5数据集,arcd算法与cs算法、mp-t-cs算法、apriori算法、sacs算法对比,得到实验结果如图7所示。
由图7可知,数据量较小时,不能体现出hadoop和spark平台的计算优势,当数据量增加时,可以看出arcd算法的优势逐渐明显,计算速度优于其他算法,与传统的apriori算法相比,运算时间相当于传统apriori的十分之一。这是因为arcd算法利用布尔矩阵压缩数据集,改进的算法只需要扫描一次数据库就可以得到频繁项集,降低了运算的时间。其次,arcd算法利用spark是基于内存计算的特点,数据越大,spark的优势越明显,计算速度越快。
为了验证算法的可扩展性及算法的并行化效果,arcd算法在d4数据集下与mp-t-cs算法比较加速比。
由图8可知,两个算法的加速比随集群数量的增加而增加,可以看出两个算法都有很好的并行性。arcd算法的加速比要高于sacs算法,主要原因是arcd算法将数据集映射到布尔矩阵,通过“与”操作得到频繁项集,算法只需要扫描一次数据库,提高了运算速度。实验证明arcd算法具有较好的并行性,在处理海量数据集时运算速度更快。
为了验证本文算法在不同数据集下的可扩展性,实验取数据集d1~d5,在不同节点下测试arcd算法的加速比。实验结果如图9所示。
由图9可知,数据量较小时,随着集群个数的增加,加速效果并不明显,这是因为数据量小计算时间短,并行计算不占优势。当数据量足够大时,加速比几乎呈线性。实验证明了arcd算法面对海量数据集时并行处理能力很好,具有良好的可扩展性。
针对传统的社团发现算法计算效率低的问题,本文提出了在spark平台上利用事务权重和布尔矩阵改进关联规则的arcd算法。arcd算法结合了支持度自适应的方法,解决了人为设置支持度的主观性。将改进的算法在spark上实现并行化,解决了mapreduce频繁扫描磁盘,增加i/o消耗的问题。实验结果表明,arcd算法在挖掘社团成员关系时,计算效率高,有良好的并行性和可扩展性,在处理海量数据时有明显优势。
以上所述是本发明的优选实施方式而已,当然不能以此来限定本发明之权利范围,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和变动,这些改进和变动也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!