文本情感分类方法、装置、设备和存储介质与流程
本发明涉及计算机
技术领域:
,尤其涉及一种文本情感分类方法、装置、设备和存储介质。
背景技术:
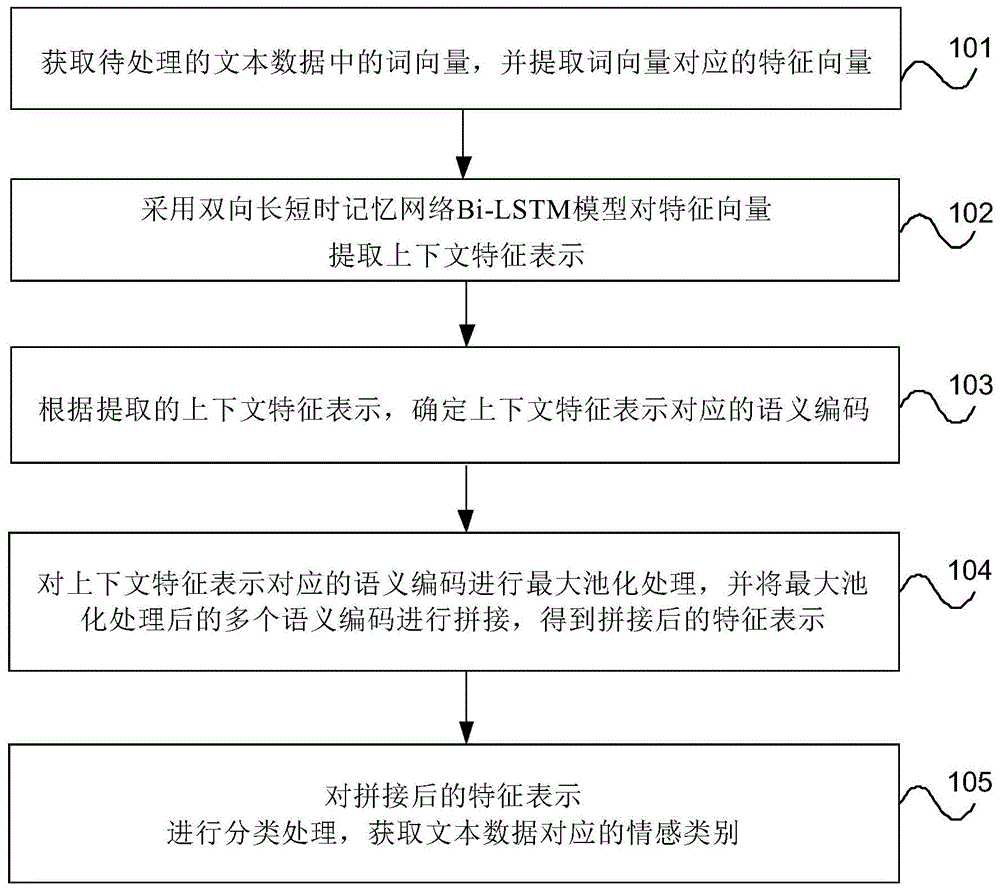
:随着互联网的发展及互联网用户的增多,网络用户在互联网上产生了大量的文本信息,比如对某商品、电影、店铺等的评论,如何从这些文本中挖掘出有用信息不仅对商家、消费者等都有益处。因此,文本情感倾向性分析变得尤为重要,文本情感倾向性分析(即文本情感分类)是自然语言处理(naturallanguageprocessing,简称nlp)领域的一个分支,传统的文本情感分类主要有:基于情感字典的文本情感分类方法和基于机器学习的文本情感分类方法,上述两种方法并没有考虑词语的上下文信息或文本的语序问题并且需要大量的人力去提取文本特征,可能不能更深层次的提取文本中重要的特征。近几年随着深度学习技术的发展,提出了递归神经网络(recurrentneuralnetwork,简称rnn)和卷积神经网络(convolutionalneuralnetwork,简称cnn)模型,cnn模型主要是利用卷积层和降采样层进行特征提取,rnn模型是使当前节点(或前几个节点)的状态可以影响下一个节点的状态,并将最后一个节点的状态作为特征,但上述模型在进行文本情感分类效果较差。技术实现要素:本发明提供一种文本情感分类方法、装置、设备和存储介质,以提高文本情感分类效果。第一方面,本发明提供一种文本情感分类方法,包括:获取待处理的文本数据中的词向量,并使用卷积操作提取所述词向量对应的特征向量;采用双向长短时记忆网络bi-lstm模型对所述特征向量提取上下文特征表示;根据提取的所述上下文特征表示,确定所述上下文特征表示对应的语义编码;对所述上下文特征表示对应的语义编码进行最大池化处理,并将最大池化处理后的多个语义编码进行拼接,得到拼接后的特征表示;对所述拼接后的特征表示进行分类处理,获取所述文本数据对应的情感类别。第二方面,本发明提供一种文本情感分类装置,包括:提取模块,用于获取待处理的文本数据中的词向量,并提取所述词向量对应的特征向量;所述提取模块,还用于采用双向长短时记忆网络bi-lstm模型对所述特征向量提取上下文特征表示;确定模块,用于根据提取的所述上下文特征表示,确定所述上下文特征表示对应的语义编码;处理模块,用于对所述上下文特征表示对应的语义编码进行最大池化处理,并将最大池化处理后的多个语义编码进行拼接,得到拼接后的特征表示;对拼接后的特征表示进行分类处理,获取所述文本数据对应的情感类别。第三方面,本发明实施例提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面中任一项所述的方法。第四方面,本发明实施例提供一种电子设备,包括:处理器;以及存储器,用于存储所述处理器的可执行指令;其中,所述处理器配置为经由执行所述可执行指令来执行第一方面中任一项所述的方法。本发明实施例提供的文本情感分类方法、装置、设备和存储介质,获取待处理的文本数据中的词向量,使用卷积操作提取所述词向量对应的特征向量;采用双向长短时记忆网络bi-lstm模型对所述特征向量提取上下文特征表示;根据提取的所述上下文特征表示使用attention机制来获取不同特征的重要性后送入top-k-maxpooling池化层来提取出最重要的前k个特征,至此确定所述上下文特征表示对应的语义编码;对所述上下文特征表示对应的语义编码进行分类处理,获取所述文本数据对应的情感类别,bi-lstm模型能够充分获得文本数据中词的上下文特征,而且经过语义编码可以区分出重要特征和过滤掉非重要特征,并使得重要的特征有了更高的权重,提升了文本情感分类的准确率,分类效果较好。附图说明此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。图1是本发明提供的文本情感分类方法一实施例的流程示意图;图2是本发明提供的文本情感分类效果方法一实施例的原理示意图;图3是本发明提供的方法一实施例的池化处理原理示意图;图4是本发明提供的方法一实施例的bi-lstm模型原理示意图;图5是本发明提供的方法一实施例的注意力机制原理示意图;图6是本发明提供的文本情感分类装置一实施例的结构示意图;图7是本发明提供的电子设备实施例的结构示意图。通过上述附图,已示出本公开明确的实施例,后文中将有更详细的描述。这些附图和文字描述并不是为了通过任何方式限制本公开构思的范围,而是通过参考特定实施例为本领域技术人员说明本公开的概念。具体实施方式这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。本发明的说明书和权利要求书及所述附图中的术语“包括”和“具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。首先对本发明所涉及的应用场景进行介绍:本发明实施例提供的文本情感分类方法,应用于对文本数据进行情感分类的场景中,以提高分类准确性。情感根类是判定一个文本数据表达的是褒义还是贬义的情感,例如针对网络上的评论,如购买评价,影评,微博评论等。本发明提供的方法可由电子设备如处理器执行相应的软件代码实现,也可由该电子设备在执行相应的软件代码的同时,通过和服务器进行数据交互来实现,如服务器执行部分操作,来控制电子设备执行方法。下面的实施例均以电子设备为执行主体进行说明。下面以具体的实施例对本发明的技术方案进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例不再赘述。图1是本发明提供的文本情感分类方法一实施例的流程示意图。如图1所示,本实施例提供的方法,包括:步骤101、获取待处理的文本数据中的词向量,并提取词向量对应的特征向量。具体的,在获取词向量之前可以对词向量进行训练,例如可以使用搜狗的30g新闻语料训练词向量,通过使用python下的jieba库对这些语料进行分词,之后开始训练词向量,使用word2vec下的cbow模型训练词向量,参数可以设定为:上下文窗口长度设置为5,学习速率alpha使用默认值0.025,最低频率min-count使用默认值5,即如果一个词语在文档中出现的次数小于5,那么就会丢弃,词向量维度设置为100维。将待处理的文本数据进行分词得到多个单词,并根据训练的词向量模型将文本数据中的单词转换成词向量。文本数据例如包括多个句子,每个句子对应多个词向量。例如通过图2所示的词嵌入层进行处理。进一步的,如图2所示,将文本数据转换成相应的词向量之后,通过一层的一维卷积层来提取初步的特征向量,本发明实施例使用不同大小的卷积窗口进行卷积操作,每次卷积操作的结果按照卷积顺序形成新的特征向量。步骤102、采用双向长短时记忆网络bi-lstm模型对特征向量提取上下文特征表示。具体的,本发明实施例的方法中将卷积层的计算结果即卷积操作得到的特征向量送入到bi-lstm模型(如图2所示),bi-lstm模型可以充分提取文本特征。双向长短时记忆网络在处理序列数据(及有顺序的文本数据)时有很大优势,所以本发明实施例中在第一层卷积操作后将特征向量bi-lstm模型中。长短时记忆网络(lstm)相比传统循环神经网络(recurrentneuralnetwork,简称rnn)模型不存在梯度消失和梯度爆炸问题,在自然语言处理中具有不错的效果。为了使lstm能够将当前时刻的词汇信息与其全部上下文信息融合到一起,本发明实施例中使用能够双向读取文本的bi-lstm模型。通过bi-lstm模型对卷积操作后的特征向量提取上下文特征表示。步骤103、根据提取的上下文特征表示,确定上下文特征表示对应的语义编码。具体的,如图2所示,通过注意力attention机制确定上下文特征表示对应的语义编码,即在文本情感分类中通过计算注意力分布概率,可以突出重要特征的影响,即语句中不同关键词对分类结果具有不同的影响作用。例如,我们在看关于某一商品的评论时不可能记住所有的描述,能记住的也只是一些关键词,比如“很好”、“很不错”、“大大的赞”等词,而这些词对于文本情感倾向的表达很重要,因此文本数据中的不同特征对分类结果具有不同的影响作用。语义编码是是根据bi-lstm层的输出结果(即上下文特征表示)与概率权重计算得出的。步骤104、对上下文特征表示对应的语义编码进行最大池化处理,并将最大池化处理后的多个语义编码进行拼接,得到拼接后的特征表示;为了进一步降低数据纬度在生成语义编码后可以进行最大池化操作:k-max-pooling,使用固定滑动窗口在生成的语义编码结果中进行前k个最大值的选取,提取出最重要的前k个特征,以此过滤掉非重要特征来降低数据纬度进而提高模型收敛速度和预测精度。步骤105、对拼接后的特征表示进行分类处理,获取文本数据对应的情感类别。具体的,根据语义编码以及前k值最大池化处理的结果对文本数据进行分类处理,获取该文本数据对应的情感类别。可以通过预设的分类函数进行分类处理。其中,可以利用不同的分类器进行分类处理。例如,对于某一商品的评论,假设进行二分类,可以分类为好评、差评的类别。好评中可能包括“很好”、“很不错”等词,差评中可能包括使用体验不好,不会再购买等语句。本实施例的方法,获取待处理的文本数据中的词向量,并提取所述词向量对应的特征向量;采用双向长短时记忆网络bi-lstm模型对所述特征向量提取上下文特征表示;根据提取的所述上下文特征表示,确定所述上下文特征表示对应的语义编码;对所述上下文特征表示对应的语义编码进行分类处理,获取所述文本数据对应的情感类别,bi-lstm模型能够充分获得文本数据中词的上下文特征,而且经过语义编码可以区分出重要特征和过滤掉非重要特征,并使得重要的特征有了更高的权重,提升了文本情感分类的准确率,分类效果较好。在上述实施例的基础上,可选的,步骤104具体可以通过如下方式实现:使用预设的滑动窗口选取所述滑动窗口内的语义编码中前k个最大的语义编码,得到多个滑动窗口对应的前k个最大的语义编码;对所述多个滑动窗口对应的前k个最大的语义编码进行拼接得到所述拼接后的特征表示。具体的,如图2所示在进行语义编码后进行k最大池化处理,如图3所示,top-k计算公式为:top-k=maxk{c1,c2,c3,…cp}上式中的k表示取最大的前k个值,c1,c2,c3,…cp分别表示语义编码值,p表示滑动窗口的大小。号表示向量的拼接。滑动窗口的步长可以为k-1。即一次在p个语义编码值找前k个最大的语义编码值,然后滑动窗口向右移动k-1个语义编码值,找下一组p个语义编码值。最后,可以利用预设的分类函数对拼接后的特征表示进行分类处理,得到所述文本数据对应的情感类别。在上述实施例的基础上,可选的,步骤101中提取所述词向量对应的特征向量具体可以通过如下方式实现:将所述词向量输入卷积层得到如下的特征矩阵:其中,f矩阵中每一行表示不同大小的卷积窗口对所述文本数据中的词向量进行卷积后生成的特征向量;其中每一行中的cij=relu(sjf+θ),其中relu为激活函数,f∈rk×d表示卷积层长度为k(即卷积窗口大小为k)的过滤器在d维词向量上的卷积操作,θ表示偏移量,sj表示所述文本数据中第j个词开始的连续k个词组成的词向量矩阵sj=[wj,wj+1,…,wj+k-1],其中,wj∈rd表示所述文本数据中第j个单词的词向量,维度是d维,i取值范围为1到m;m为卷积窗口的种类个数,j的取值范围为1到n,n为文本数据分词后的词个数。m例如为3,第1类卷积窗口k大小为2,第2类卷积窗口k大小为3,第3类卷积窗口k大小为4。进一步的,如图4所示,步骤102具体可以通过如下方式实现:根据如下公式(2),确定所述特征向量对应的上文特征表示;根据如下公式(3),确定所述特征向量对应的下文特征表示;根据上文特征表示以及所述下文特征表示,利用如下公式(4),得到所述特征向量对应的上下文的特征表示;其中,ht为所述文本数据中第t个单词对应的隐藏状态,ht=ot⊙tanh(ct),ot=δ(wo·x+bo),ct=ft⊙t-1+it⊙tanh(wc·x+bc),ft=δ(wf·x+bf),,it=δ(wi·x+bi);其中,wf、wi、wo、wc为lstm的权重矩阵,bf、bi、bo、bc为lstm的偏置量,w1t为所述f矩阵的第t列的列向量;δ(·)为激活函数;⊙为矩阵的点乘操作;n为词向量的个数。具体的,δ(·)可以为激活函数sigmoid。bi-lstm层能够将当前词汇信息与其全部上下文信息融合到一起,获取到上下文的特征表示。进一步的,如图5所示,步骤103具体可以通过如下方式实现:根据所述bi-lstm模型提取的上下文的特征表示,以及概率权重,利用如下公式(5),确定所述上下文的特征表示对应的语义编码;其中outt是所述上下文的特征表示,alt表示第t个特征表示的重要程度,即第t个特征表示的概率权重,alt由如下公式(6)计算得出:其中,rt=vttanh(waoutt+b),wa为参数矩阵,b为偏执项,vt为随机初始矩阵v的转置。l的取值范围为1到n,n为词向量的个数。上下文的特征表示对应的语义编码是根据bi-lstm层的输出结果以及概率权重计算得出的,利用attention机制突出重要特征的影响。本发明实施例的方法,将bi-lstm模型作为单独一层融入到卷积层和池化层之间,首先利用一层卷积层进行文本初步的特征提取,为了充分获得文本数据中词的上下文特征将特征向量送入到bi-lstm模型中,为了区分出重要特征和过滤掉非重要特征对bi-lstm模型的输出结果引入了注意力机制和top-k最大池化处理,注意力机制使得重要的特征有了更高的权重,top-k最大池化处理的滑动窗口步长可以k-1的步长以此来模拟自然语言处理中的n-gram操作,本发明实施例中的卷积层和后面提出的top-k最大池化处理层相当于对文本数据进行了两次n-gram操作。综上,本发明实施例的方法在卷积层卷积计算特征向量后按照计算顺序逐个将计算的结果放入到特征矩阵f中为了防止池化层打乱原语句的顺序在卷积层后直接引入了bi-lstm,将bi-lstm的计算结果引入attention机制使得重要的特征有了更高的权重,为了降低特征维度提高分类准确率,引入了top-k最大池化处理,最后为了提升文本情感分类的准确率可以将提取出来的特征表示送入强分类器进行分类,能够取得较好的分类效果。基于上述实施例的方法,使用cnn和bi-lstm模型融合的方式建立本发明实施例的cbltk模型,利用深度学习能够提取更深层次特征的特点来提取文本的特征,为了提升最后分类准确率,以下对比了几种常用的强分类器,将提取到的特征送入到强分类器中进行分类(支持向量机(supportvectormachine,简称svm)/随机森林(randomforest,简称rf)等):以下使用的文本数据例如是豆瓣影评数据,该些文本数据已经在评论时由用户的星星颗数打好标记(五颗星表示很好,一颗星表示很差),从中抽取五颗星和一颗星数据进行文本情感分类的研究(即对文本数据进行二分类),使用正负类每类三万条共六万条文本数据作为训练数据,使用正负类每类六千条共一万两千条文本数据作为测试数据,据统计平均每条评论包括45个词,所以本发明实施例的模型使用文本数据的句子长度规定为45个词,如果有句子超过45那么直接截断,如果句子长度少于45则使用null进行填补,分词工具使用python的jieba分词,使用tensorflow1.6构建本发明实施例的cbltk模型。其中词向量训练语料可以选取搜狗新闻语料30g。基于文本数据的词语之间具有顺序的特点,本发明实施例在cbltk模型第一层仅使用一层卷积核,以及在使用注意力机制后采用一层max-pooling最大池化层外加分类层,例如softmax分类,模型训练过程中可以将dropout设置为50%,使用l2正则化。本发明实施例的模型可以将minimatch设置为100,使用三类不同大小的卷积窗口每类150个卷积核,并选取了三类最好的卷积窗口。表1卷积窗口大小的选择从表1结果中我们选取卷积窗口分别为2、3、4长度的卷积窗口进行卷积操作,对于bi-lstm层中lstm层隐层神经元个数可以选取150个隐层神经元。对于k最大池化层,对k值从1到6找出最合适的值,从下表得出的结果可以选取k为3。表2k值的选取top-k值准确率171.2%274.5%377.6%475.3%576.8%675.6%本发明实施例的cbltk模型主要以最后分类准确率作为评判指标,做了几组对比试验分别是使用softmax分类、使用强分类器,结果中加入了使用传统的文本情感分类方法的分类结果作为基准。具体结果如下所示:表3使用softmax分类器模型准确率cnn80.3%lstm81.1%cnn+lstm82.8%lstm+cnn83.3%cbltk85.2%表4使用强分类器(svm)从表3和表4可以看出使用传统的文本情感分类方法(如词频-逆文本频率指数(termfrequency–inversedocumentfrequency,简称tf-idf)算法)由于只能提取浅层的文本特征表示所以准确率没有使用深度学习的方法高,使用先cnn再lstm效果没有先使用lstm再使用cnn效果好。从表2可以看出虽然本发明实施例提出的cbltm模型使用了svm但是效果提升幅度不大所以接下来本模型结合了四种常用的强分类器:svm、rf、朴素贝叶斯、gbdt,找出分类效果较好的一种结合方式。表5结合不同分类器结合方式准确率cbltk+svm86.1%cbltk+rf87.6%cbltk+gbdt89.3%cbltk+朴素贝叶斯85.3%表5当前的结果除了和当前选取的数据有关外还与其他因素有关,比如数据量、当前模型提取到的特征是否适用于当前分类器等,从表5中结果可以看出使用了强分类器未必效果就全部好,比如和朴素贝叶斯结合效果并没有达到预期这可能和当前所用的数据和朴素贝叶斯的特点有关:朴素贝叶斯成立的前提是假设每个特征之间是相互独立的,而在文本分类中词语与词语之间是有很强的相互关系的,从结果中还能看出使用gbdt要优于随机森林(randomforest,简称rf)可能原因是rf使用集成学习中的bagging的思想即:有放回均匀取样,而gbdt属于boosting思想是根据错误率来取样也就是说在训练时某个弱分类器弱分类错误那么给其相对低的权重所以gbdt的训练过程跟融入attention机制的深度学习模型类似,使用权重值大小来突出重要的特征。图6为本发明提供的文本情感分类装置一实施例的结构图,如图6所示,本实施例的文本情感分类装置,包括:提取模块601,用于获取待处理的文本数据中的词向量,并提取所述词向量对应的特征向量;提取模块601,还用于采用双向长短时记忆网络bi-lstm模型对所述特征向量提取上下文特征表示;确定模块602,用于根据提取的所述上下文特征表示,确定所述上下文特征表示对应的语义编码;处理模块603,用于对所述上下文特征表示对应的语义编码进行最大池化处理,并将最大池化处理后的多个语义编码进行拼接,得到拼接后的特征表示;对所述拼接后的特征表示进行分类处理,获取所述文本数据对应的情感类别。在一种可能的实现方式中,所述提取模块601具体用于:将所述词向量输入卷积层得到如下的特征矩阵:其中,f矩阵中每一行表示不同大小的卷积窗口对所述文本数据中的词向量进行卷积后生成的特征向量;其中每一行中的cij=relu(sjf+θ),其中relu为激活函数,f∈rk×d表示卷积层长度为k的过滤器在d维词向量上的卷积操作,θ表示偏移量,sj表示所述文本数据中第i个词开始的连续k个词组成的词向量矩阵sj=[wj,wj+1,…,wj+k-1],其中,wj∈rd表示所述文本数据中第j个单词的词向量,维度是d维,i取值范围为1到m;m为卷积窗口的种类个数,j的取值范围为1到n,n为文本数据分词后的词个数。在一种可能的实现方式中,所述提取模块601具体用于:根据如下公式(2),确定所述特征向量对应的上文特征表示;根据如下公式(3),确定所述特征向量对应的下文特征表示;根据上文特征表示以及所述下文特征表示,利用如下公式(4),得到所述特征向量对应的上下文的特征表示;其中,ht为所述文本数据中第t个单词对应的隐藏状态,ht=ot⊙tanh(ct),ot=δ(wo·x+bo),ct=ft⊙ct-1+it⊙tanh(wc·x+bc),ft=δ(wf·x+bf),,it=δ(wi·x+bi);其中,wf、wi、wo、wc为lstm的权重矩阵,bf、bi、bo、bc为lstm的偏置量,w1t为所述f矩阵的第t列的列向量;δ(·)为激活函数;⊙为矩阵的点乘操作;n为词向量的个数,t的取值范围为1到n。在一种可能的实现方式中,所述确定模块602具体用于:根据所述bi-lstm模型提取的上下文的特征表示,以及概率权重,利用如下公式(5),确定所述上下文的特征表示对应的语义编码;其中outt是所述上下文的特征表示,alt表示第t个特征表示的重要程度,即第t个特征表示的概率权重,alt由如下公式(6)计算得出:其中,rt=vttanh(waoutt+b),wa为参数矩阵,b为偏执项,vt为随机处室矩阵v的转置。在一种可能的实现方式中,所述处理模块603具体用于:使用预设的滑动窗口选取所述滑动窗口内的语义编码中前k个最大的语义编码,得到多个滑动窗口对应的前k个最大的语义编码;对所述多个滑动窗口对应的前k个最大的语义编码进行拼接得到所述拼接后的特征表示。在一种可能的实现方式中,所述处理模块603具体用于:利用预设的分类函数对所述拼接后的特征表示进行分类处理,得到所述文本数据对应的情感类别。本实施例的装置,可以用于执行上述方法实施例的技术方案,其实现原理和技术效果类似,此处不再赘述。图7为本发明提供的电子设备实施例的结构图,如图7所示,该电子设备包括:处理器701,以及,用于存储处理器701的可执行指令的存储器702。可选的,还可以包括:通信接口703,用于实现与其他设备的通信。上述部件可以通过一条或多条总线进行通信。其中,处理器501配置为经由执行所述可执行指令来执行前述方法实施例中对应的方法,其具体实施过程可以参见前述方法实施例,此处不再赘述。本发明实施例中还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现前述方法实施例中对应的方法,其具体实施过程可以参见前述方法实施例,其实现原理和技术效果类似,此处不再赘述。本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本发明旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本
技术领域:
中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求书指出。应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求书来限制。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1