一种多层感知机深度神经网络层间流水处理方法与流程
本发明主要涉及到深度神经网络(deepneuronnetwork,dnn)技术领域,特指一种多层感知机(multi-layerperceptions,mlp)深度神经网络层间流水计算方法。
背景技术:
从上个世纪80年代起,mlp就已经是相当流行的机器学习方法。mlp早已经被证明是一种通用的函数近似方法,可以被用来执行预测、函数近似拟合以及模式分类任务,应用范围曾涉及医学、工业勘探、消费电子等多种领域。mlp具备高度的非线性全局作用、良好的容错性、联想记忆功能等优点。随着dnn的推广,mlp在语音、图像以及机器学习等可利用近似拟合方法的领域广泛应用。据报道,google的数据中心有61%以上的任务负载是mlp类任务。
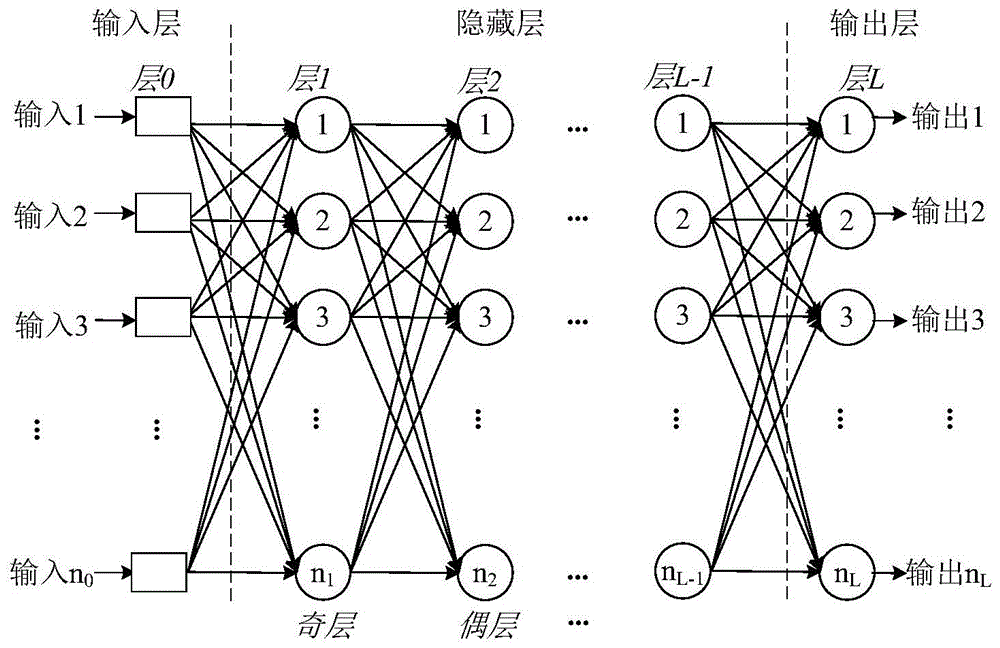
mlp是一种基于全连接(fully-connected,fc)前向结构的人工神经网络(artificialneuralnetwork,ann),其包含从十几个到成百上千不等的人工神经元(artificialneuron,an,下文简称神经元)。mlp将神经元组织为多层的结构,层间采用全连接方法,形成逐层连接的多权连接层的ann,其基本结构如图1所示。一般来讲,mlp包含一个输入层(该层实际不包含运算)、一个或者多个隐层层以及一个输出层。
图1是典型mlp的结构示意图。mlp是一种基于全连接(fully-connected,fc)前向结构的人工神经网络(artificialneuralnetwork,ann),其包含从十几个到成百上千不等的人工神经元(artificialneuron,an,下文简称神经元)。mlp将神经元组织为多个层的结构,层间采用fc连接方法,形成多层的ann。从中可以看出,多个全连接层逐层连接,形成了复杂结构的mlp。一般来讲,mlp包含一个输入层(该层实际不包含运算)、一个或者多个隐层以及一个输出层。
·将mlp各个包含计算的全连接层从1开始进行编号,总层数为l;
·输入层编号设置为0;
·将mlp的全连接层分为奇数层和偶数层两大类;
·i表示mlp的全连接层编号,第i层的神经元个数记为ni,i∈(0,1,…,l);
·xi为第i层的输入,yi为第i层的输出,由于上一层的输出是下一层的输入,则有xi=yi-1;
·wi为第i层的参数矩阵,bi为第i层的偏置向量
·输入层不包含运算,有:x0=y0=x1;
图1中mlp的第i个全连接层的计算方法如下面的公式所示。
其中yi是当前全连接层的输出神经元向量,xi是输入神经元向量,wi为权重矩阵(包含偏置在内),f为针对单个元素的激活函数。
mlp的前向推导过程是根据fc计算公式,逐层计算神经元,最终得到输出。现有的mlp硬件加速装置采取了很多数据重用和并行计算的方法来优化一个每一层内的计算,然后逐层调度和计算,这被称为逐层顺序调度方法。这种方法是目前所有结构所采取的调度方法。
逐层顺序调度考虑的是层内并行和数据重用,然而根据图1可知,mlp的某一层的输出正好是下一层的输入,这是一种天然存在的层间数据重用关系。而逐层顺序调度方法之所以不能有效开发mlp的这种天然属性,在于其采用的计算模式所带来的数据相关性:每一层的神经元都必须完全计算完成后,才能启动下一层的计算过程,这推迟了下一层的开始时间,增加了整体计算时间;同时,在等待当前层后续神经元计算完成期间,已经完成计算的神经元数据将重新写入到存储器中,使用的时候再重新读取,这增大了读写开销。
目前也有设计可以进行多任务流水,一般是在多个mlp任务之间进行层间流水。由于处理任务变大,这种方法需要大量的存储空间和带宽,任务延迟变大,并不适合于移动设备等电池受限、强调延迟的边缘计算。
技术实现要素:
本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种能够充分利用层间数据重用、利于单个mlp任务响应时间缩短、降低功耗开销的多层感知机深度神经网络层间流水处理方法,本发明的方法适用于边缘计算平台。
为解决上述技术问题,本发明采用以下技术方案:
一种多层感知机深度神经网络层间流水处理方法,假定该层编号为i,其步骤包括:
当mlp为奇数全连接层时,取参数矩阵wi的一行,与输入向量做点积运算,得到的结果再加上对应的偏置,通过非线性函数即得到最后的神经元yi;
当mlp为偶数全连接层时,执行以下流程:
步骤1:初始化部分和向量为该层对应的偏置向量bi;
步骤2:根据输入元素
步骤3:输入元素
步骤4:若所有的输入元素完毕,则在部分和向量的每个元素上执行非线性函数,得到该层的输出神经元yi;否则调准到步骤2。
作为本发明的进一步改进:当mlp为奇数全连接层时,处理的顺序为从前往后或从后往前。
作为本发明的进一步改进:多个神经元采用并行处理,当所有神经元计算完毕后得到整个神经元向量yi。
作为本发明的进一步改进:当mlp为偶数全连接层时,在所述步骤2和步骤3的执行过程中,并行处理多个输入元素。
作为本发明的进一步改进:所有的部分和在运算过程中执行累加;每个特定的输出神经元计算过程中,每个输入元素只参与一次运算。
作为本发明的进一步改进:所述mlp的奇数层的神经元与偶数层神经元是并行发生的,实现层间流水处理。
作为本发明的进一步改进:所述多层感知机深度神经网络层间流水处理包括以下周期:
第1个周期:利用输入x,计算mlp第1层神经元1;
第2个周期:利用输入x,计算mlp第1层神经元2,同时利用mlp第1层神经元1,并行完成并行计算mlp第2层神经元部分和向量的第1次累加;
第3个周期到第n1个周期重复上述过程;到第n1个周期,mlp第1层神经元全部计算完毕;
第n1+1个周期:利用mlp第1层神经元n1,计算mlp第2层神经元部分和向量的第n1次累加并得到最终结果y。令x=y。
第n1+2个周期开始,重复第1个周期到第n1+1个周期的计算,直到所有mlp层计算完毕。
与现有技术相比,本发明的优点在于:
本发明的多层感知机深度神经网络层间流水处理方法,具有能够充分利用层间数据重用、利于单个mlp任务响应时间缩短、降低功耗开销等优点。本发明在计算资源内部实现mlp层间数据复用,同时,该方法支持软件流水、硬件流水等各种层间流水方式,实现mlp层间运重叠,从而提高mlp的性能。
附图说明
图1是典型mlp的结构示意图。
图2是本发明的mlp奇数层处理的实例示意图。
图3是本发明的mlp偶数层处理的实例示意图。
图4是本发明处理方法在具体实施例中的示意图。
图5是本发明处理方法在多层感知机深度神经网络中流水线处理的示意图。
具体实施方式
以下将结合说明书附图和具体实施例对本发明做进一步详细说明。
如图1-图3所示,本发明的多层感知机深度神经网络层间流水处理方法,假定该层编号为i,那么该层输出神经元yi向量的步骤包括:
当mlp为奇数全连接层时,取参数矩阵wi的一行,与输入向量做点积运算,得到的结果再加上对应的偏置,通过非线性函数即得到最后的神经元;
当mlp为偶数全连接层时,执行以下流程:
步骤1:初始化部分和向量为该层对应的偏置向量bi;
步骤2:根据输入元素
步骤3:输入元素
步骤4:若所有的输入元素完毕,则在部分和向量的每个元素上执行非线性函数,得到该层的输出神经元yi;否则调准到步骤2。
在具体应用实例中,当mlp为奇数全连接层时,计算的顺序可以从前往后、从后往前等,并不强调顺序;并且多个神经元也可以并行计算。所有神经元计算完毕后得到整个神经元向量yi。
在具体应用实例中,当mlp为偶数全连接层时,所述步骤2和步骤3的执行过程中,可以并行处理多个输入元素;所有的部分和需要累加起来,可以在运算过程中执行累加,累加时机不限;输入元素的顺序没有要求;每个特定的输出神经元计算过程中,每个输入元素只参与一次运算。
如图4所示,为本发明方法在一个具体应用实例中的详细流程,基于本发明的上述方法,完成过程为:
步骤s1:mlp初始化。
1)令当前处理层编号i=-1;
2)从内存读取mlp的输入层:
3)获得y0=x0
步骤s2:层初始化。
1)令当前处理层神经元编号j=0;
2)层编号自增2,即i=i+2;
3)获得mlp第i层输入:xi=yi-1
步骤s3:层预处理。
1)神经元编号j自增1,即j=j+1
步骤s4:第i层和第i+1层神经元并行计算。
并行步骤4-1:
1)计算i层第j个神经元:
1)若i==l,空转;
2)若i≠l,计算i+1层所有输出神经元的部分和向量第j次累加结果:
a)若(j-1)==0,则初始化部分和向量:
b)否则:获得输入
步骤s5:判断是否结束当前层。
1)若j≠ni,跳转到步骤s3;
2)若j==ni且i≠l,继续计算偶层最终结果:
a)获得输入
b)
步骤s6:判断是否已经完成mlp计算。
1)若i+1==l,令y=yi+1=yl
2)若i==l,令y=yi=yl,
3)否则,跳转到步骤2
步骤s7:输出y。
在上述流程中,所述并行步骤4-1处理的是mlp的奇数层的神经元,所述并行步骤4-2处理的是mlp的偶数层神经元,这两个步骤是并行发生的,可实现层间流水处理。
在上述流程中,并行步骤4-1计算i层神经元的时候,并未限制按照从1到ni的顺序,此处只是为了叙述方便;也并未限制每次仅处理一个神经元,硬件或者软件实现可根据实际资源并行处理多个神经元或者一个神经元的一部分。
在上述流程中,并行步骤4-2计算i+1层输出神经元向量的时候,并未限制从1到ni的顺序,而实需要根据并行步骤4-1的前一次迭代输出的第i层神经元结果进行。
在上述流程中,并行步骤4-2计算i+1层输出神经元向量的时候,并未限制一次处理一个输入神经元,即完成一次输出神经元部分和的累加;可根据资源以及并行步骤4-1的前一次迭代输出的第i层神经元结果,处理多个神经元。
在上述流程中,并行步骤4-2计算i+1层输出神经元向量的时候,并未限制需要同时完成第i+1层所有神经元的部分和的累加;硬件或者软件实现可根据实际资源并行处理全部输出神经元或者部分神经元的部分和向量。
在上述流程中,步骤2的1)的输出立刻为步骤2的2)所利用,步骤2的3)的部分和中间结果在反复利用,步骤2的3)的最终计算结果被步骤2的1)立刻使用;这些重用数据均不会被替换出计算资源以外,降低了访存开销。特别对于嵌入式移动计算设备,可极大降低功耗。该方法所使用的技术与现有的其他技术属于正交关系,可以合理集成在一起,共同提高mlp的运算性能。
如图5所示,将本发明的方法具体应用在多层感知机深度神经网络进行流水线处理时,其步骤为:
第1个周期:利用输入x,计算mlp第1层神经元1;
第2个周期:利用输入x,计算mlp第1层神经元2,同时利用mlp第1层神经元1,并行完成并行计算mlp第2层神经元部分和向量的第1次累加;
第3个周期到第n1个周期重复上述过程;到第n1个周期,mlp第1层神经元全部计算完毕;
第n1+1个周期:利用mlp第1层神经元n1,计算mlp第2层神经元部分和向量的第n1次累加并得到最终结果y。令x=y。
第n1+2个周期开始,重复第1个周期到第n1+1个周期的计算,直到所有mlp层计算完毕。
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!