基于级联深度残差网络的视频去噪方法与流程
本发明涉及计算机视觉领域,特别涉及一种基于级联深度残差网络的视频去噪方法。
背景技术:
视频监控系统的摄像机在视频采集过程中会引入各种类型的噪声,视频噪声不仅会降低视觉意义上的图像质量,而且会对后续视频编码系统施加很大的压力。从叠加了噪声的视频信号中去除或者抑制噪声信号,恢复出未受噪声污染的理想视频信号,对于hevc、h.264等编码系统和目标检测、跟踪、识别系统而言具有重要意义。所以,视频噪声去除或者抑制一直受到学术界和产业界的广泛关注。
近年来,随着深度学习在基于图像的目标检测、识别、超分辨率分析等各个领域取得极大的成功,启发了人们将其应用于图像去噪,文献“beyondagaussiandenoiser:residuallearningofdeepcnnforimagedenoising”(zhangkaietal,ieeetransactionsonimageprocessing,2017.6)提出了一种用于单帧图像去噪的卷积神经网络模型:dncnn,针对加性高斯噪声训练权值参数。中国专利201610729038.1提供了的基于深度递归神经网络的视频去噪模型包含两层递归神经网络,分别获取初级和高级特征,最后由输出层解码重构这些特征输出估计所得的去噪视频。
技术实现要素:
本发明的目的在于解决现有技术中存在的问题,并提供一种基于级联深度残差网络的视频去噪方法。
本发明具体采用的技术方案如下:一种基于级联深度残差网络的视频去噪方法,包括以下步骤:
(1)获取待去噪的视频,设待去噪的视频中的第t帧图像为it,得到图像序列{it-k,…,it,…,it+k},其中it-i和it+i分别为位于t时刻之前和之后,与第t帧图像相隔i帧的图像,k可取值为1、2或3;
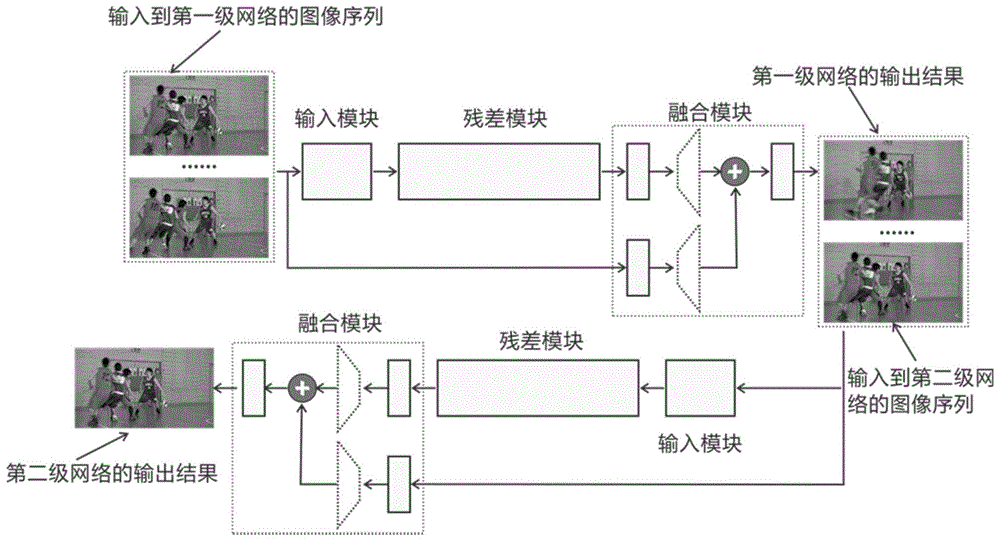
(2)构建第一级和第二级深度残差网络;第一级和第二级深度残差网络具有相同的网络结构,第一级和第二级深度残差网络均包括输入模块、残差模块和融合模块;所述输入模块包括一个卷积层,该卷积层具有ninput个3×3×(2k+1)大小的卷积核;所述残差模块包含nblock个残差块,每个残差块中包含卷积层conv_k01、prelu层和卷积层conv_k02;所述融合模块包含卷积层conv_b01、卷积层conv_b02和卷积层conv_b03;
(3)将步骤(1)中的图像序列输入到第一级深度残差网络,图像序列中的每幅图像被当作一个二维矩阵,依次排列这些矩阵形成一个三阶张量,与输入模块中的ninput个卷积核进行步长为1的卷积运算,产生包含ninput个通道的特征图,输入到残差模块中;
(4)残差模块中的第一残差块的输入为输入模块输出的特征图,除第一残差块之外的任意第k个残差块以第k-1个残差块的输出为输入,设某个残差块的输入为x,前向传播时的数据流向依次为卷积层conv_k01、prelu层、卷积层conv_k02,通过卷积层conv_k01、prelu层和卷积层conv_k02将输入x映射为f(x),最后以f(x)和输入x之和f(x)+x作为残差块的输出;
(5)融合模块有两个输入,其中的一个来自残差模块的输出,将其输入到融合模块的卷积层conv_b01,经卷积运算后产生一个包含4dout个通道的特征图,其中dout为输出图像的通道数目;融合模块的另一个输入来自于步骤(3)中依次排列输入图像对应的矩阵所形成的三阶张量,将其输入到融合模块的卷积层conv_b02,经卷积运算后产生一个包含4dout个通道的特征图;
(6)将融合模块的卷积层conv_b01和conv_b02的输出经像素重排,将特征图变换成长宽方向分别为输入图像长和宽的2倍,通道数等于输出图像通道数目的特征图;
(7)将融合模块两个经像素重排后的特征图进行加运算,运算结果作为卷积层conv_b03的输入,经步长为2的卷积运算后得到第一级深度残差网络的输出结果为图像序列
(8)将第一级深度残差网络输出的结果图像序列作为第二级深度残差网络中输入模块的输入,重复步骤(3)-(7)的过程,输出最终的结果图像。
进一步地,所述第一级深度残差网络各个层次的参数以学习的方式确定,包括如下步骤:
步骤a、准备训练样本:采集用于训练的视频,设f是其中的一帧图像,按下式叠加幅度值符合高斯分布、泊松分布或者均匀分布的噪声信号z,形成包含噪声的图像g:
g=f+z
分别对原始视频中的图像和对应的加噪后的图像依次标号,形成参考图像序列和对应的含噪图像序列,作为训练样本集;
训练样本集中的一个样本可表示为(ui,vi),若vi∈rm×n为来自参考图像序列的第t帧ft的图像块,且左上角点位于像素(m,n),图像块大小为m×n,则ui∈rm×n×(2k+1)是一个由2k+1个图像块组成的三阶张量,其中的第1、2、...、2k+1个图像块依次来自含噪图像序列g的第t-k、t-k+1、...、t+k帧,k取值为1、2或3,每个图像块的大小均为m×n,左上角点坐标位于各自对应图像的像素(m,n)位置;
步骤b、初始化参数:第一级深度残差网络中的所有卷积层,其参数被初始化为符合均值为0,标准差为
步骤c、训练:批量加载训练样本集中的样本,对每个训练样本(ui,vi)按下式计算损失函数:
其中m和n是训练样本集中图像的高和宽,
以最小化所有训练样本的损失函数累加和为目标,以adam优化算法更新深度残差网络各层的权值,学习率的初始值可置为0.005~0.01之间的值,以分段下降的方式调整学习率,具体地,将总的训练周期数分为四个阶段,后一个阶段的学习率等于前一个阶段的学习率的三分之一。
进一步地,第一级深度残差网络的训练完成以后,再进行第二级深度残差网络的训练;
用与第一级深度残差网络相同的方式形成参考图像序列f和含噪图像序列g,对于含噪图像序列g中的任一帧图像gk由训练所得的第一级深度残差网络输出对应的去噪后图像
进一步地,所述的输入模块中卷积核的数量ninput可取值32。
进一步地,所述的残差模块中残差块的数量nblock可取介于8到16之间的整数;所述第k个残差块中的卷积层conv_k01具有4倍于卷积层conv_k02的卷积核数量,conv_k01的卷积核数目可取为128,conv_k02的卷积核数目可取为32;conv_k01的卷积核大小为3×3×c1,conv_k02的卷积核大小为3×3×c2,c1和c2分别为输入到对应卷积层的特征图的通道数目;为了保证去噪后图像具有与输入图像相同的尺寸,残差模块中的所有卷积层的卷积步长为1。
进一步地,所述融合模块中的卷积层conv_b01的卷积核大小为3×3×c3,conv_b02的卷积核大小为3×3×c4,c3和c4分别为输入到对应卷积层的特征图的通道数目,为了保证去噪后图像具有与输入图像相同的尺寸,两个卷积层的卷积步长都为1。
进一步地,所述融合模块中的卷积层conv_b01和conv_b02的输出经像素重排,将特征图变换成长宽方向分别为输入图像长和宽的2倍,通道数等于输出图像通道数目的特征图,具体为:设输出图像的通道数为dout,卷积层conv_b01和conv_b02分别输出一个通道数目为4dout、大小为h×w的特征图,依次取这些通道(m,n)位置的值形成一个2×2×dout的三阶张量,将其置于(2m,2n)位置,将形成一个大小为2h×2w,通道数为dout的输出特征图。
进一步地,所述输入和输出图像,可为视频图像的亮度分量、红色或蓝色色度分量。
本发明的有益效果:本发明采用级联的两个深度残差网络能够有效的对视频图像的噪声去除或抑制,提高视频图像质量,将其作为编码器的预处理步骤,可有效的提高编码器的性能;或将其作为目标检测器的预处理步骤,则能有效的提高检测器的准确率,降低误检率。
附图说明
图1为本发明级联深度残差网络结构示意图;
图2为残差块网络结构示意图;
图3为融合模块示意图;
图4为像素重排上采样示意图;
图5为应用本发明级联深度残差网络进行视频去噪的结果示意图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步阐述,以便本领域技术人员更好地理解本发明的实质。
如图1所示,本发明提供的一种基于级联深度残差网络的视频去噪方法,包括以下步骤:
(1)获取待去噪的视频图像,设待去噪的视频中的第t帧图像为it,得到图像序列{it-k,…,it,…,it+k},其中it-i和it+i分别为位于t时刻之前和之后,与第t帧图像相隔i帧的图像,k可取值为1、2或3;
(2)构建第一级和第二级深度残差网络;第一级和第二级深度残差网络具有相同的网络结构,第一级和第二级深度残差网络均包括输入模块、残差模块和融合模块;所述输入模块包括一个卷积层,该卷积层具有ninput个3×3×(2k+1)大小的卷积核;所述残差模块包含nblock个依次相连的残差块,残差块的数量nblock可取介于8到16之间的整数,每个残差块中包含卷积层conv_k01、prelu层和卷积层conv_k02;所述融合模块包含卷积层conv_b01、卷积层conv_b02和卷积层conv_b03;
(3)所述第一级深度残差网络各个层次的参数以学习的方式确定,包括如下步骤:
步骤a、准备训练样本:采集用于训练的视频,设f是其中的一帧图像,按下式叠加幅度值符合高斯分布、泊松分布或者均匀分布的噪声信号z,形成包含噪声的图像g:
g=f+z
分别对原始视频中的图像和对应的加噪后的图像依次标号,形成参考图像序列和对应的含噪图像序列,作为训练样本集;
训练样本集中的一个样本可表示为(ui,vi),若vi∈rm×n为来自参考图像序列的第t帧ft的图像块,且左上角点位于像素(m,n),图像块大小为m×n,则ui∈rm×n×(2k+1)是一个由2k+1个图像块组成的三阶张量,其中的第1、2、...、2k+1个图像块依次来自含噪图像序列g的第t-k、t-k+1、...、t+k帧,k取值为1、2或3,每个图像块的大小均为m×n,左上角点坐标位于各自对应图像的像素(m,n)位置;
步骤b、初始化参数:第一级深度残差网络中的所有卷积层,其参数被初始化为符合均值为0,标准差为
步骤c、训练:批量加载训练样本集中的样本,对每个训练样本(ui,vi)按下式计算损失函数:
其中m和n是训练样本集中图像的高和宽,
以最小化所有训练样本的损失函数累加和为目标,以adam优化算法更新深度残差网络各层的权值,学习率的初始值可置为0.005~0.01之间的值,以分段下降的方式调整学习率,具体地,将总的训练周期数分为四个阶段,后一个阶段的学习率等于前一个阶段的学习率的三分之一。
(4)第一级深度残差网络的训练完成以后,再进行第二级深度残差网络的训练;
用与第一级深度残差网络相同的方式形成参考图像序列f和含噪图像序列g,对于含噪图像序列g中的任一帧图像gk由训练所得的第一级深度残差网络输出对应的去噪后图像
(5)将步骤(1)中的图像序列输入到第一级深度残差网络,图像序列中的每幅图像被当作一个二维矩阵,依次排列这些矩阵形成一个三阶张量,与输入模块中的ninput个卷积核进行步长为1的卷积运算,产生包含ninput个通道的特征图,输入到残差模块中;所述的输入模块中卷积核的数量ninput可取值32。
(6)残差模块中的第一残差块的输入为输入模块输出的特征图,除第一残差块之外的任意第k个残差块以第k-1个残差块的输出为输入,如图2所示,设某个残差块的输入为x,前向传播时的数据流向依次为卷积层conv_k01、prelu层、卷积层conv_k02,通过卷积层conv_k01、prelu层和卷积层conv_k02将输入x映射为f(x),最后以f(x)和输入x之和f(x)+x作为残差块的输出;所述第k个残差块中的卷积层conv_k01具有4倍于卷积层conv_k02的卷积核数量,conv_k01的卷积核数目可取为128,conv_k02的卷积核数目可取为32;conv_k01的卷积核大小为3×3×c1,conv_k02的卷积核大小为3×3×c2,c1和c2分别为输入到对应卷积层的特征图的通道数目;为了保证去噪后图像具有与输入图像相同的尺寸,残差模块中的所有卷积层的卷积步长为1。
(7)如图3所示,融合模块有两个输入,其中的一个来自残差模块的输出,将其输入到融合模块的卷积层conv_b01,经卷积运算后产生一个包含4dout个通道的特征图,其中dout为输出图像的通道数目;融合模块的另一个输入来自于步骤(5)中依次排列输入图像对应的矩阵所形成的三阶张量,将其输入到融合模块的卷积层conv_b02,经卷积运算后产生一个包含4dout个通道的特征图;所述融合模块中的卷积层conv_b01的卷积核大小为3×3×c3,conv_b02的卷积核大小为3×3×c4,c3和c4分别为输入到对应卷积层的特征图的通道数目,为了保证去噪后图像具有与输入图像相同的尺寸,两个卷积层的卷积步长都为1。输入和输出的图像,可为视频图像的亮度分量、红色或蓝色色度分量,本发明的实施例对亮度和色度图像分别处理,所以dout=1;
(8)所述融合模块中的卷积层conv_b01和conv_b02的输出经像素重排上采样,如图4所示,将特征图变换成长宽方向分别为输入图像长和宽的2倍,通道数等于输出图像通道数目特征图,具体为:设输出图像的通道数为dout,卷积层conv_b01和conv_b02分别输出一个通道数目为4dout、大小为h×w的特征图,依次取这些通道(m,n)位置的值形成一个2×2×dout的三阶张量,将其置于(2m,2n)位置,将形成一个大小为2h×2w,通道数为dout的输出特征图;
(9)将融合模块两个经像素重排上采样后的特征图进行加运算,运算结果作为卷积层conv_b03的输入,其中conv_b03的卷积核数目等于dout,卷积核大小为3×3×4dout,卷积步长为2,经卷积运算后得到第一级深度残差网络的输出结果为图像序列
(10)将第一级深度残差网络输出的结果图像序列作为第二级深度残差网络中输入模块的输入,重复步骤(5)-(9)的过程,输出最终的结果图像。
如图5所示,为本发明实施例提供的方法对添加了高斯噪声的hevc标准测试视频racehorses进行去噪的结果,图5第一行中从左到右依次为原始视频中的第30、40、50和60帧;第二行为上述各帧叠加了均值为0,方差为大于24.0小于50.0之间的随机值的高斯噪声后形成的图像;第三行则为采用本发明提供的方法去噪处理后形成的结果图像。通过原始视频图像、含有噪声的图像以及采用本发明方法进行去噪处理后的视频图像之间的对比可知,本发明方法能够明显去除或抑制视频中的噪声,提高视频图像的质量,为后续的视频编码具有重要意义。
以上所述仅为本发明的较佳实施例,但本发明的保护范围并不局限于此,凡在本发明的精神和原则之内,所做的任何修改或替换等,都应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!