一种人脸数据库快速检索技术的制作方法
本发明涉及人工智能领域,具体提供一种人脸数据库快速检索技术。
背景技术:
随着人工智能和深度学习技术的发展,深度神经网路模型在人脸识别任务中得到广泛应用,并大幅度提高了人脸识别的准确率。被训练好的人脸识别模型计算得到所有人员的人脸特征向量,并存储在数据库中,当进行识别某个员工时,在模型计算中计算待识别人脸的特征向量,然后,计算该向量与数据库中所有特征向量的距离,如果其中距离最小值小于预先设定的阈值δ,则判断为同一个人;反之,判定该人员不在数据库中。
在这种方法下,许多人脸识别场景需要实时的识别性能,但是当人脸数据库中的人员过多时,查找最小距离的过程会消耗过长的时间,从而导致应用的实时性下降,甚至不可接受。
技术实现要素:
本发明是针对上述现有技术的不足,提供一种实用性强的人脸数据库快速检索技术。
本发明解决其技术问题所采用的技术方案是:
一种人脸数据库快速检索技术,在人脸识别模型输出的人脸特征向量为多维向量,其中,每一维均为浮点数值标量,人脸特征向量组成的空间认为是rn空间。其特征在于,包括如下步骤:
步骤1、对人脸数据库建立有序分割,保证划分的每个子区间有序;
步骤2、基于划分的子区间,在人脸识别时对人脸特征向量进行对比,根据特征向量与中心向量的距离判断分区。
进一步的,步骤1-1、得到中心向量;
步骤1-2、划分到不同的子集合;
步骤1-3、构建一级分区;
步骤1-4、构建二级分区。
进一步的,在步骤1-1中由人脸识别模型和人脸图像得到所有人员的人脸特征向量,计算每一个维度的平均值,得到中心向量,中心向量用o表示,将中心向量o作为中心点。
进一步的,在步骤1-2中以两倍的阈值为增量建立有序数列,阈值用δ来表示,任意相邻的两个有序数对组成一个子区间的划分,将特征向量按照所述划分分配到不同的子集合中。
进一步的,在步骤1-3中,若一个特征向量与中心点的距离在某个有序数对的区间内,则这个特征向量被分配到对应的有序数对分割的子集合中,这样的子集合构成一级分区。
进一步的,在步骤1-4中,对每个子集合继续划分为两个子集合,同样按照特征向量与中心点的距离远近划分,分割点为一级分区两个边界的中点,对每个一级分区划分为两个二级分区。
进一步的,在步骤2中,对于一张待识别的人脸图像,输入到人脸识别模型中,得到所述人脸图像的特征向量。然后,进行如下步骤:
步骤2-1、计算人脸图像的特征向量与中心点的距离,进行分区;
步骤2-2、判断待识别人脸图像是否在数据库中。
进一步的,在步骤2-1中,计算所述人脸图像的特征向量与所述中心点的距离,根据距离远近得到对应的一级分区,如果该距离与一级分区的上边界差值超过阈值δ,则返回该一级分区和下一个一级分区的前二级分区;
否则,返回该一级分区和上一个一级分区的后二级分区。
进一步的,步骤2-2中,如果返回分区中不含有任何特征向量,则判定待识别人脸图像对应的人员不在数据库中;否则,计算人脸图像的特征向量与返回的分区中所有特征向量的距离,距离最小者即为对应的人员,判定为同一个人。
本发明的人脸数据库快速检索技术和现有技术相比,具有以下突出的有益效果:
(1)本发明提出的一种根据距离远近对数据库中的人脸记录事先进行分区存储的方法,适当建立索引,在识别人脸时能够大大减小需要查找的候选记录,增加对比速度。
(2)当在人脸数据库中的人员过多时,查找的时间也会相对的减少时间,实用性和实时性提高,提高工作的效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
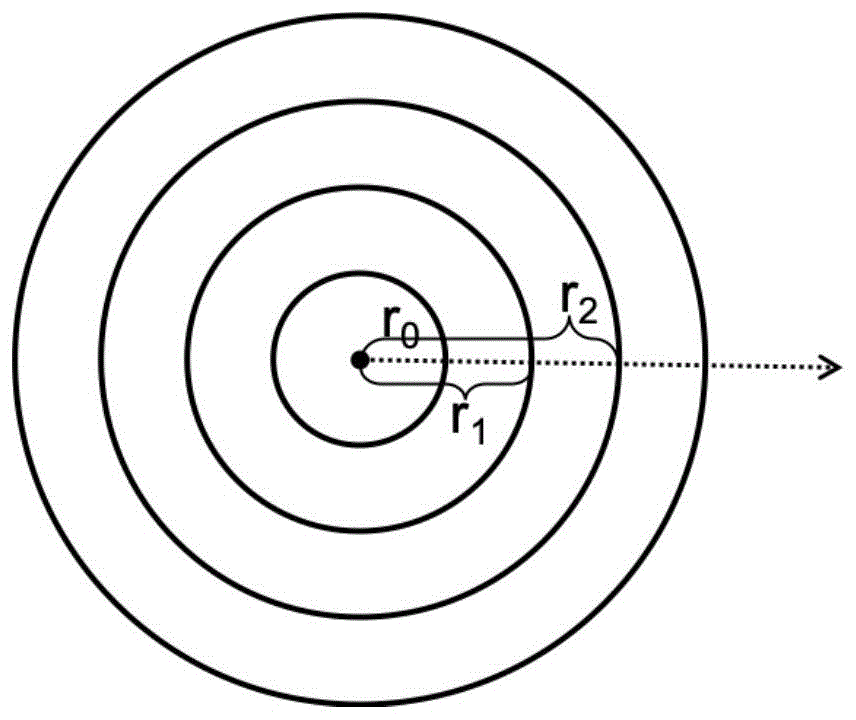
附图1是本发明数据库索引分表示意图;
附图2是本发明待识别样本位置示意图。
具体实施方式
为了使本技术领域的人员更好的理解本发明的方案,下面结合具体的实施方式对本发明作进一步的详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例都属于本发明保护的范围。
下面给出一个最佳实施例:
如图1、2所示,本实施例中首先提出一种对人脸数据库建立有序分割的方法,该方法保证划分的每个子区间有序;然后,基于该划分的子区间,提出了一种在人脸识别时对人脸特征向量进行快速对比的方法。
(1)对人脸数据库建立有序分割,保证划分的每个子区间有序:
首先,进行预处理。确定训练后的人脸识别模型,假设为m,识别阈值设置为δ。为所有需要识别的人员分配唯一的id,将所有人员的脸部图像输入到模型m中,输出人脸特征向量v,每一个人员的(id,v)组成数据库的一条记录,假设m用128维向量表示人脸特征,则向量v为128维。
然后,划分数据库。根据人脸特征向量v组成的特征空间,计算每一维的平均值,得到中心向量o,计算与o相距最大的向量距离为t。从零开始,以两倍的阈值2*δ为增量生成有序数列r0,r1,r2,...,rm,其中,rm-1≤t<rm。[r0,r1)构成第一个一级分区的区间,与中心向量o的距离在该区间的所有向量被分配到该一级分区中,同时,与中心向量o的距离小于r0+δ的所有向量继续被分配到该一级分区的前二级分区中,剩余向量被分配到该一级分区的后二级分区中。
最后,按照该方法,依次分配剩余m-1个一级分区,和每个一级分区中的前、后二级分区。一级分区的示意图参阅图1。对所有一级分区和二级分区建立树形索引,根据索引可以在常数时间内查找到每个分区。每个二级分区内存储所有被分配到该分区的(id,v)记录。
(2)基于划分的子区间,在人脸识别时对人脸特征向量进行对比,根据特征向量与中心向量的距离判断分区:
在进行人脸识别时,将人脸图像输入到人脸识别模型m中,得到输出特征向量u,计算u与中心向量o的距离d,计算距离d与增量δ的整除商k。
当k为偶数时,返回第k/2个一级分区和第
原理为:
在rn空间中,以任意一点o为中心,设其子空间dλ,β表示与中心点o的距离不小于λ,且小于β的向量集合,λ>0,β>0。那么,对任意一组正有序数列r0<t1<…<ri<…,集合
1)对任意的两个子空间集合,
2)
上述性质表明,空间rn可以被任意一组正有序数列划分为多个互不相交,但可以完全覆盖该空间的子空间集合。
上述具体的实施方式仅是本发明具体的个案,本发明的专利保护范围包括但不限于上述具体的实施方式,任何符合本发明的人脸数据库快速检索技术权利要求书的且任何所述技术领域普通技术人员对其做出的适当变化或者替换,皆应落入本发明的专利保护范围。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!