一种基于社区检测的增量聚类算法的制作方法
本发明涉及文本聚类技术领域,尤其是一种基于社区检测的增量聚类算法。
背景技术:
新闻是一种重要的信息来源,一篇新闻报道往往包含了一些特定的信息,例如对于特定企业或者人物的报道。因此,许多技术类公司或者研究员致力于从相关新闻报道中挖掘有价值的信息,从而服务于商业类信息分析或者数据挖掘。聚类是一种有效的将相关信息聚集成话题簇的手段,随着信息的爆炸式增长,传统的聚类方法在面对大规模的数据时会遭遇严重的性能瓶颈,并且随着新数据的到来,会将历史的数据进行重聚类,引起了不必要的性能开销。相较传统的聚类方法而言,增量聚类更适合这种新数据不断到来的聚类场景。
目前,增量聚类研究主要分为三个方面:1)基于密度的增量研究方法,以denstream、c-denstream、predeconstream为主要代表;2)基于层次的增量研究算法,以cobweb、clustream、hpstream为主要代表;3)基于划分的增量研究算法,以stream为主要代表。其中,基于层次的增量研究算法与基于划分的增量研究算法存在对大规模数据集适应性不够,计算开销比较大等问题而不适用于大规模数据的增量式聚类,而基于密度的增量研究方法具有处理大规模数据的能力。现有的增量聚类的研究方法仍然存在以下几点问题。
1、增量聚类算法的时间复杂度依然比较大
denstream采用了online-offline两阶段聚类的框架,在merging与pruning阶段存在较高的计算复杂度,带来了巨大的时间开销;c-denstream在denstream的基础上引入了事件级别的must-link与cannot-link限制改善了聚类结果,但是依然存在denstream计算复杂度较大的问题;predeconstream提升了在offline阶段的性能,但是依然存在在搜索最近相邻类时存在巨大的时间复杂度开销。
2、缺少将热点事件与持续报道事件区分开的能力
denstream在pruning阶段直接把outlier-microcluster内数据删除,意味着将低频热点事件与低频持续报道一并删除,引起了信息丢失的风险;c-denstream用半监督的方式对事件级别的新闻做类别限制,但是依然无法区分同一事件类别中热点新闻与持续报道新闻,仍会无法区分这两种事件;predeconstream没有对这种情况做处理,所以也缺少相应的事件区分能力。
综上所述,现有技术的增量聚类算法依然存在计算时间复杂度开销较大,缺少区分热点事件与持续报道事件的能力,相应的增量式文本聚类算法还未见有报道。
技术实现要素:
本发明的目的是针对现有技术的不足而设计的一种基于社区检测的增量聚类算法,采用community社区概念和online-offline两阶段框架并引入imc概念,可以有效地对目标语料进行增量式聚类,能够为某一领域但不局限于金融领域对数据进行分析挖掘,为后续的决策推断提供支撑,实现了区分热点事件与持续报道事件的功能,从而对新闻事件做了有效的聚类与事件级别的过滤,有效降低增量式聚类的计算时间复杂度,并具有区分热点事件与持续性报道事件的能力。
本发明的目的是这样实现的:一种基于社区检测的增量聚类算法,其特点该算法包括以下步骤:
s1:对全量的中文金融文本语料进行词向量预训练,生成词向量模型。
s2:对全量的中文金融文本语料使用布隆过滤器技术,进行文本去重筛选,并经过文本预处理后得到目标金融语料。
s3:对目标金融语料使用tf-idf技术得到每篇语料文档的top-k个关键词并构建关键词列表,对目标金融语料使用命名实体识别技术得到每篇语料文档的命名实体识别预测词,并构建命名实体识别预测词列表,同时对目标金融语料使用基于s1步骤中预训练的词向量模型生成文档的表征词向量。
s4:对文档的表征词向量计算相似度得到目标语料的表征词向量相似度矩阵,分别对文档的top-k个关键词和文档的命名实体识别预测词使用局部敏感哈希技术,得到对应的shingles向量,并分别计算相似度得到关键词相似度矩阵和命名实体识别预测词相似度矩阵。
s5:将s4步骤中得到的三个相似度矩阵进行加权拼接,并根据自定义条件筛选,最终得到所有文档的相似度图表示。
s6:将s5步骤中得到的相似度图,使用louvain算法得到初始化社区结果。
s7:将s6步骤中得到的初始化社区结果,使用自定义增量聚类算法进行增量式聚类。
上述s1步骤中所述全量中文金融文本语料由对各大金融门户网站的定时爬虫爬取构成;所述词向量模型由全量中文金融文本语料预训练而成,其训练方式为fasttext。
上述s2步骤中所述文本去重使用的技术采用bloomfilter,所述文本预处理包括去掉停用词与thualc分词。
上述s3步骤中所述top-k个关键词由每篇文档经tf-idf技术对文档分词结果所选取出词频-逆文档频率最高的k个词构成;所述关键词列表为所有文档的关键词的set集合;所述命名实体识别技术为bi-lstm+crf;所述命名实体识别预测词为对文档中上市公司(org-a)、非上市公司(org-o)、人名(per)、地点(loc)、时间(time)、金钱(money)和产品(prod)等词的预测;所述命名实体识别预测词列表为所有文档的命名实体识别预测词的set集合;所述词向量采用的表征方法为fasttext。
上述s4步骤中所述表征词向量相似度矩阵的相似度计算方法为cosine距离;所述top-k个关键词的shingles向量为关键词列表的bit-vector映射;所述关键词相似度矩阵为关键词列表的bit-vector拼接成的矩阵;所述命名实体识别预测词的shingles向量为命名实体识别预测词列表的bit-vector映射;所述命名实体识别预测词相似度矩阵为命名实体识别预测词列表的bit-vector拼接成的矩阵;所述bit-vector向量采用局部敏感哈希算法中的shingling方法。
上述s5步骤中所述自定义条件筛选为保留相似度大于等于某一阈值的文档对,剔除相似度小于某一阈值的文档对;所述文档的相似度图为将文档视为节点,文档对的相似度视为节点对的权重值边,由这些节点与边构成相似度图。
上述s6步骤中所述初始化社区结果为社区检测算法louvain中第一阶段中止的结果。
上述s7步骤中所述自定义增量聚类算法为基于社区检测的增量聚类算法;所述增量式聚类为在初始化社区结果上将依次到达的数据流,依据当前文档的特征与已有社区的相似性匹配度大小,直接分配到最匹配的社区或者创建一个新的社区,最终所有的社区被视为不同的类,从而实现增量式的聚类,其中自定义增量聚类算法主要步骤如下:
a、用louvain算法对相似度图做初始化社区检测,在louvain算法的第一阶段终止,得到初始化社区结果。
b、对初始化社区结果做分析,计算每个社区的一阶特征向量
其中:xi为每个社区中文档的fasttext向量;ti为每篇文档的时间戳timestamp;f(t)=2-λt为窗口衰减函数。
c、将满足w≥βμ,0<β≤1且r≤∈的社区簇定义为pmc(potential-microcluster);将满足w<βμ,0<β≤1且r>∈的社区簇定义为omc(outlier-microcluster);将满足w≥βμ,r>∈或w<βμ,r≤∈的社区簇定义为imc(inactive-microcluster);
d、对于增量式到达的数据p,使用lsh(localsensitivehash)在pmc簇中寻找最相似的社区簇,如果该社区簇加入p后新的半径r小于预设阈值∈,将点p加入该社区簇;否则在omc簇中寻找最相似的社区簇,如果该社区簇加入p后新的权重w大于等于预设阈值βμ,则将点p加入该社区簇;否则创建一个新的omc并加入p点。
e、待所有新到达的增量数据按d步骤处理完后,遍历所有在窗口衰减函数的作用下新的pmc簇,如果w<βμ或者r>∈,使用lsh在imc簇中寻找最相似的社区簇,若找到,则将该pmc加入imc簇;若未找到,则创建一个新的imc来保存pmc中的数据点。
f、待e步骤中所有的pmc簇遍历完成后,当聚类请求到达时,遍历所有的imc簇,如果该imc的权重大于等于预设阈值βμ,保留该imc;否则,删除该imc。
g、待f步骤处理完成后,计算所有pmc簇与imc簇的模块度
其中:m表示权重总和;wi表示第i个community的边权重;ci代表第i个community。
如果模块度降低则按模块度增益
本发明与现有技术相比具有在同等硬件条件下降低计算时间开销,从而能够更加快速的生成聚类结果,以便更好地服务于应用场景的上下游业务,做到及时响应,实现了区分热点事件与持续报道事件的功能,从而对新闻事件做了有效的聚类与事件级别的过滤。
附图说明
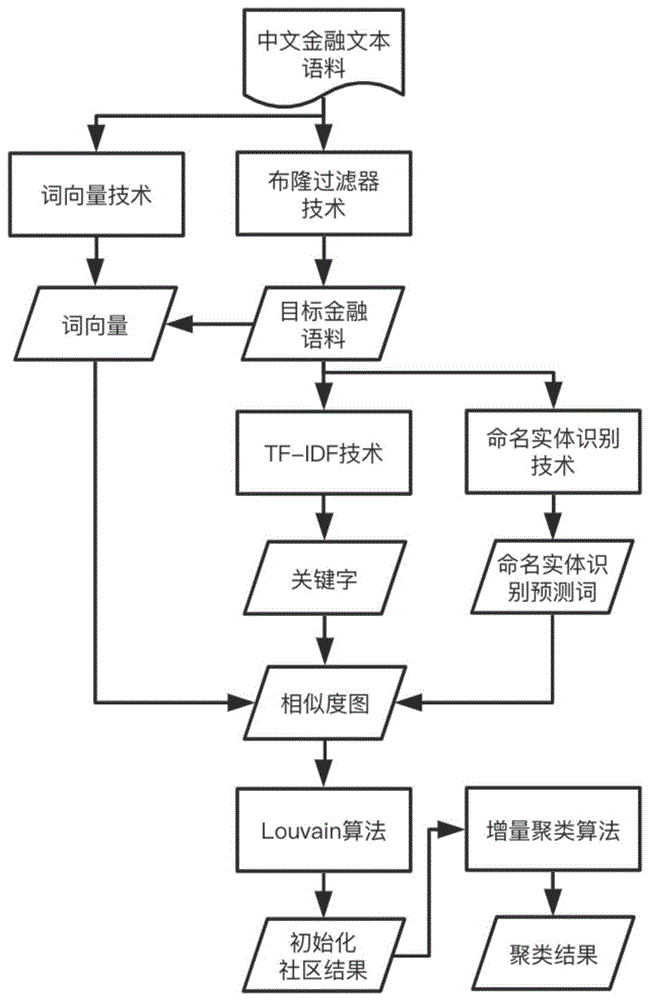
图1为本发明流程图;
图2为聚类簇生成过程示意图。
具体实施方式
本发明采用词向量技术对全量中文金融文本语料进行词向量训练得到文档表征词向量,然后使用布隆过滤器对中文金融文本语料进行筛选得到目标金融语料,对目标金融语料使用tf-idf技术得到文档的表征关键词,同时对目标金融语料使用命名实体识别技术得到文档的命名实体识别预测词,由文档表征词向量、文档的表征关键词与文档的命名实体识别预测词共同经相似度计算方法得到目标语料的相似度图,最后对相似度图先使用louvain算法得到初始化社区结果,并在初始化社区结果的基础上使用增量聚类算法得到最终的聚类结果。
通过以下具体实施例对本发明作进一步的详细说明。
实施例1
参阅附图1,按下述步骤进行基于社区检测的增量聚类算法:
s1:对全量的中文金融文本语料进行词向量预训练,生成词向量模型。所述全量中文金融文本语料由对各大金融门户网站的定时爬虫爬取构成;所述词向量模型由全量中文金融文本语料预训练而成,其训练方式为fasttext。
s2:对全量的中文金融文本语料使用布隆过滤器技术,进行文本去重筛选,并经过文本预处理后得到目标金融语料。所述文本去重使用的技术采用bloomfilter,所述文本预处理包括去掉停用词与thualc分词。
s3:对目标金融语料使用tf-idf技术得到每篇语料文档的top-k个关键词并构建关键词列表,对目标金融语料使用命名实体识别技术得到每篇语料文档的命名实体识别预测词并构建命名实体识别预测词列表,同时对目标金融语料使用基于步骤s1预训练的词向量模型生成文档的表征词向量。所述top-k个关键词由每篇文档经tf-idf技术对文档分词结果所选取出词频-逆文档频率最高的k个词构成;所述关键词列表为所有文档的关键词的set集合;所述命名实体识别技术为bi-lstm+crf;命名实体识别预测词为对文档中上市公司(org-a)、非上市公司(org-o)、人名(per)、地点(loc)、时间(time)、金钱(money)或产品(prod)等词的预测;所述命名实体识别预测词列表为所有文档的命名实体识别预测词的set集合;所述词向量采用的表征方法为fasttext。
s4:对文档的表征词向量计算相似度得到目标语料的表征词向量相似度矩阵,分别对文档的top-k个关键词与文档的命名实体识别预测词使用局部敏感哈希技术得到对应的shingles向量并分别计算相似度得到关键词相似度矩阵与命名实体识别预测词相似度矩阵。所述表征词向量相似度矩阵的相似度计算方法为cosine距离;top-k个关键词的shingles向量为关键词列表的bit-vector映射;所述关键词相似度矩阵为关键词列表的bit-vector拼接成的矩阵;所述命名实体识别预测词的shingles向量为命名实体识别预测词列表的bit-vector映射;所述命名实体识别预测词相似度矩阵为命名实体识别预测词列表的bit-vector拼接成的矩阵;所述bit-vector向量采用局部敏感哈希算法中的shingling方法。
s5:对基于步骤s4得到的三个相似度矩阵进行加权拼接,并根据自定义条件筛选,最终得到所有文档的相似度图表示。所述自定义条件筛选为保留相似度大于等于某一阈值的文档对,剔除相似度小于某一阈值的文档对;所述文档的相似度图为将文档视为节点,文档对的相似度视为节点对的权重值边,由这些节点与边构成相似度图。
s6:参阅附图2,基于步骤s5得到的相似度图,使用louvain算法得到类1~类5的初始化社区结果,该初始化社区结果为社区检测算法louvain中第一阶段中止的结果。
s7:基于步骤s6得到的初始化社区结果,使用自定义增量聚类算法进行增量式聚类,所述自定义增量聚类算法为基于社区检测的增量聚类算法,增量式聚类为在初始化社区结果上将依次到达的数据流,依据当前文档的特征与已有社区的相似性匹配度大小,直接分配到最匹配的社区或者创建一个新的社区,最终所有的社区被视为不同的类,从而实现增量式的聚类,其中自定义增量聚类算法主要步骤如下:
a、用louvain算法对相似度图做初始化社区检测,在louvain算法的第一阶段终止,得到初始化社区结果;
b、对初始化社区结果做分析,计算每个社区的一阶特征向量
其中:xi为每个社区中文档的fasttext向量;ti为每篇文档的时间戳timestamp;f(t)=2-λt为窗口衰减函数;
c、将满足w≥βμ,0<β≤1且r≤∈的社区簇定义为pmc(potential-microcluster);将满足w<βμ,0<β≤1且r>∈的社区簇定义为omc(outlier-microcluster);将满足w≥βμ,r>∈或w<βμ,r≤∈的社区簇定义为imc(inactive-microcluster);
d、对于增量式到达的数据p,使用lsh(localsensitivehash)在pmc簇中寻找最相似的社区簇,如果该社区簇加入p后新的半径r小于预设阈值∈,将点p加入该社区簇;否则在omc簇中寻找最相似的社区簇,如果该社区簇加入p后新的权重w大于等于预设阈值βμ,则将点p加入该社区簇;否则创建一个新的omc,加入点p;
e、待所有新到达的增量数据按d步骤处理完后,遍历所有在窗口衰减函数的作用下新的pmc簇,如果w<βμ或者r>∈,使用lsh在imc簇中寻找最相似的社区簇,若找到,则将该pmc加入imc簇;若未找到,则创建一个新的imc来保存pmc中的数据点;
f、待e步骤中所有的pmc簇遍历完成后,当聚类请求到达时,遍历所有的imc簇,如果该imc的权重大于等于预设阈值βμ,保留该imc;否则,删除该imc;
g、待f步骤处理完成后,计算所有pmc簇与imc簇的模块度
其中:m表示权重总和;wi表示第i个community的边权重;ci代表第i个community;
如果模块度降低则按模块度增益
综上所述,本发明采用community概念、online-offline两阶段框架、fasttext技术、lsh技术、bloomfilter技术和thulac分词等技术手段,提出了一种基于社区检测的增量聚类算法的框架,实现了文本的增量式聚类,可以在同等硬件条件下降低计算时间开销,从而能够更加快速的生成聚类结果,以便更好地服务于应用场景的上下游业务,做到及时响应,实现了区分热点事件与持续报道事件的功能,从而对新闻事件做了有效的聚类与事件级别的过滤。
以上仅是本发明的优选实施方式,本发明的保护范围并不局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进,应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!