一种通讯协议隐蔽通道检测方法与流程
本发明涉及一种检测方法,具体涉及一种通讯协议隐蔽通道检测方法,属于通讯协议检测技术领域。
背景技术:
随着网络在现代生活的地位越来越重要,人们使用网络的范围也越来越大,但其实在网络给生活带来巨大便利的同时,也蕴含着重大风险,这些风险主要表现在如下几个方面:
1.无处不在的个人信息泄漏,使人们在生活种受到频繁骚扰,严重者甚至危及生命;
2.广泛存在的计算机勒索,特别是一些“臭名昭著”的勒索木马,如“永恒之蓝”、“永恒冠军”、“永恒浪漫”等永恒系列,以及入gandcrab等具有“传统”的勒索软件;
3.无孔不入的挖矿木马,即利用个人计算机的算力,在互联网世界挖掘各类电子货币,如比特币、莱特币等等。
上述列举的例子仅是“冰山一角”,而且相对于大量的各类恶意软件(木马、勒索、蠕虫等),各类杀毒软件或类似防护措施总是在各种黑客手段种丧失效能,从而任由这些恶意软件出入自由。
一般而言,特别是一些主流的恶意软件都需要和其命令结点进行通信,这类行为被称作“回连”,其实“回连”的目的主要包括两种,其一是接收命令结点的指示,其二则是将一些敏感数据传出至外网;而现代恶意软件为了隐蔽自身行为一般都会采用一些隐匿措施,如使用动态生成域名与命令结点通讯,或者使用协议隐写方法传递一些敏感数据,而后者则被称作使用隐蔽通道进行通讯或数据的传递。
协议隐写或使用隐蔽通道传递数据(主要用在数据泄漏方面)主要会依赖于一些可以轻易穿透防火墙的应用协议,如icmp或dns协议等,对于这类的数据传递合法性检测一般手段是无法适用的,因为它们会被各类网关或安全设备认为是合法的,从而会造成敏感数据泄漏或非法指令的传递。
市面上主流的检查手段一般只是使用这些数据的部分特征,应用权重方法评估数据的传递是否合法,但存在较大的局限性,主要体现在如下方面:
1.主流的检查方法一般是每种协议都需要单独解析,缺乏通用性,从而造成非常难于扩展;
主流的检查方法缺乏一定的智能性,对于非常隐蔽的手段很难发现和定位。
因此,迫切的需要一种新的方案解决上述技术问题。
技术实现要素:
本发明正是针对现有技术中存在的问题,提供一种通讯协议隐蔽通道检测方法,该技术方案克服了现有技术中的不足,建立一个较为通用的方法来融合不同通讯应用协议可能作为隐蔽通道来传输泄漏数据或非法指令,而且这种方法应具有足够的智能处理手段,当被检查数据存在明显的偏离时,可以提示使用者当前存在的风险。
为了实现上述目的,本发明的技术方案如下,一种通讯协议隐蔽通道检测方法,所述方法包括以下步骤:
步骤一:建立数据接收模块,将收集的相关网络协议数据进行回放,接收模块即第一处理模块根据不同协议的特征对相关数据进行抽取,形成第一特征数据,
步骤二:建立数据合法性特征抽取模块,即第二数据处理模块,其数据输入为第一数据处理模块,即数据接收模块所输出的相关数据,此处需要支持较多种类的数据特征抽取处理函数,
步骤三:利用上述定义的相关处理函数等,编写合适的、特征抽取脚本,
步骤四:将步骤三中形成的相关特征向量输入到bp神经网络,其中每个特征代表一个神经元,建立网络数据特征训练模块,在此模块中需要对第二特征数据进行训练,形成第三特征数据(仅包含一些数字特征),用于检验实际数据,此模块被称作第三模块;第三特征数据是最终形成的特征数据;
步骤五:将步骤四生成的第三特征数据进行保存并作为在实际系统中使用的内容,即通过在现场生成具有同样结构和权重的神经网络,对相关流量数据进行检查,如出现反向数据则直接进行报警,其输出值(介入0和1之间)可以做作为相关置信度数据放入报警中。
作为本发明的一种改进,所述步骤一中,抽取的规则按照如下方式进行定义:
■协议名称:如dns、icmp等;
■描述:非强制填写;
■协议匹配和抽取规则以及字段名称:匹配和抽取规则主要依赖于正则进行处理非定长数据;当然,它也兼容了一般的匹配和抽取规则用以抽取定长数据(一般为二进制数据,形式类似如:起始偏移(可选),正则表达式(必填),抽取长度,最大匹配深度,最大匹配长度,是否忽略大小写;其中正则表达式支持使用二进制方式匹配,以处理非纯文本情况;抽取完的数据会相应地将数值赋给某个字段,形成元数据;另外,对于特别难于用正则处理的数据支持使用基于lua的脚本进行编程处理,在lua脚本中可以对相关字段进行赋值并输出;
■数据转换:提供一定的函数,对相关需要进行内容转换的字段进行基础处理或变换,比如可将ip地址根据地理信息位置转换国别、省、市等;
■形成第一特征数据,作为第二处理模块的输入。
作为本发明的一种改进,所述步骤二中,建立数据合法性特征抽取模块,即第二数据处理模块,其数据输入为第一数据处理模块,即数据接收模块所输出的相关数据,此处需要支持较多种类的数据特征抽取处理函数,如下:
■支持字符串长度特征抽取处理;
■支持字符串大小写分布特征抽取处理;
■支持字符串字符和数字分布特征抽取处理;
■支持字符串香农信息熵特征计算处理;
■n-gram平均转移概率特征抽取;
■支持ip地址位置国别分布特征抽取处理;
■支持获取指定时间段内某对象访问次数;
■支持获取指定时间段内某对象访问流量大小;
■支持获取指定时间段内某对象访问数据包数量;
另外,针对特定协议,如dns协议等,还可以获取诸如域名的排名(是否在常见域名的前一千万名以内等)、元音分布特征获取、辅音分布特征获取、连续辅音分布特征等等。
作为本发明的一种改进,所述步骤三中,利用上述定义的相关处理函数等,编写合适的、特征抽取脚本,具体如下,针对dns隐蔽通道数据传输的特点,一般需要如下特征:
■域名长度特征:因为一般黑客利用dns传输数据会将相关信息放在域名中,然后利用dns请求的相关特性,将此信息发送出去,为了能快速的将数据传送出去,一般此域名会很长,这有别于一般的域名,但其顶级域名(tld)一般是固定的;
■顶级域名排名特征:可以对顶级域名的排名情况进行检查,如不在常见的topn域名排名内则将其设置为相应的特征值;
■域名组成特征:通过对域名拼写特征的检查,抽取相关特征,这些包括域名的熵值、连续辅音组成特征、元音分布特征、3-gram字符平均转移概率(即连续三个字符在正常域名中三字母平均转移概率);
■dns请求和响应比例:对于利用dns隐蔽通道传输敏感数据而言,黑客的目的仅是为了将这些数据传送到接收服务端,故此比例一般偏高,即请求数据包的数量一般远远高于响应数据包的数量;
■单位时间dns流量吞吐特征:对于黑客而言,因为需要通过此类方式传输大量的敏感数据,而利用dns的域名进行泄漏时,一次不可能传输太多数据,因为根据dns协议约定,域名不能设置过长,所以需要多个dns请求数据方能将相关数据传输完成;
然后,将标识为正常以及异常的数据输入到第二模块,根据定义的相关特征抽取脚本,对特征进行城区,在高维空间形成相关向量。
作为本发明的一种改进,所述步骤四中,具体如下,本发明使用三层神经网络,其中输出采用两个神经元,一个为正向(即正常数据),另一个为反向(即异常数据),中间隐层采用96个神经元,系统采用交叉熵的方法评估误差,结束条件为迭代次数设定为2000次或误差在0.0001内;为了避免欠拟合或过拟合的发生,本发明采用平方正则化方法,其误差评估公式如下:
在上面的公式中,第一部分为基于交叉熵的误差评估,而后一部分则为平方正则化部分(平方正则化即基于二范数的正则化);公式中的循环变量i和k分别表示本层内的神经元个体和其它连接层的神经元数量,而上标l则表示层数,在本发明中l取3,n为神经元的总体数量,λ则为正则化系数,一般为一个小于5大于1的参数;而w则为各个神经元的连接权重系数,也就是通过学习需要获得的最终结果;相应地,经过学习后,可以将神经网络结构以及各个神经元的连接权重进行保存,形成第三特征数据;
作为本发明的一种改进,所述步骤五中,将步骤4生成的第三特征数据进行保存并作为在实际系统中使用的内容,即通过在现场生成具有同样结构和权重的神经网络,对相关流量数据进行检查,如出现反向数据则直接进行报警,其输出值(介入0和1之间)可以做作为相关置信度数据放入报警中。
相对于现有技术,本发明具有如下优点,该技术方案使用较为通用的方法对不同类型的网络通讯协议(主要是应用协议)的特征进行抽取和建模,如针对dns协议的隐蔽通道的检测和icmp协议的隐蔽通道的检测几乎比较类似;该方案能弥补基于特征码的方式检测隐蔽通道所带来的不足,具备更好的灵活性和广泛性;该方案使用经过训练过的前馈神经网络用于检测可能存在隐蔽通道通讯,具有更好的识别率,而且由于采用神经网络方法,系统一般也无需使用数量庞大的特征库(一般动辄数量达上千万的特征库),从而减少了应用的内存占用。统一的网络应用通讯协议特征抽取框架,能适用不同的常见协议以及一些私有协议,而一般无需编制二进制代码;提供了广泛的特征抽取方法,这些特征抽取方法涵盖了数据包内容特征以及流量统计特征方面;对于无法由框架提供的脚本而完成的特征抽取工作,则提供内嵌的lua以弥补相关功能的缺失;对于不同网络通讯协议特征建立机制以及使用基于前馈神经网络的机器学习机制。
附图说明
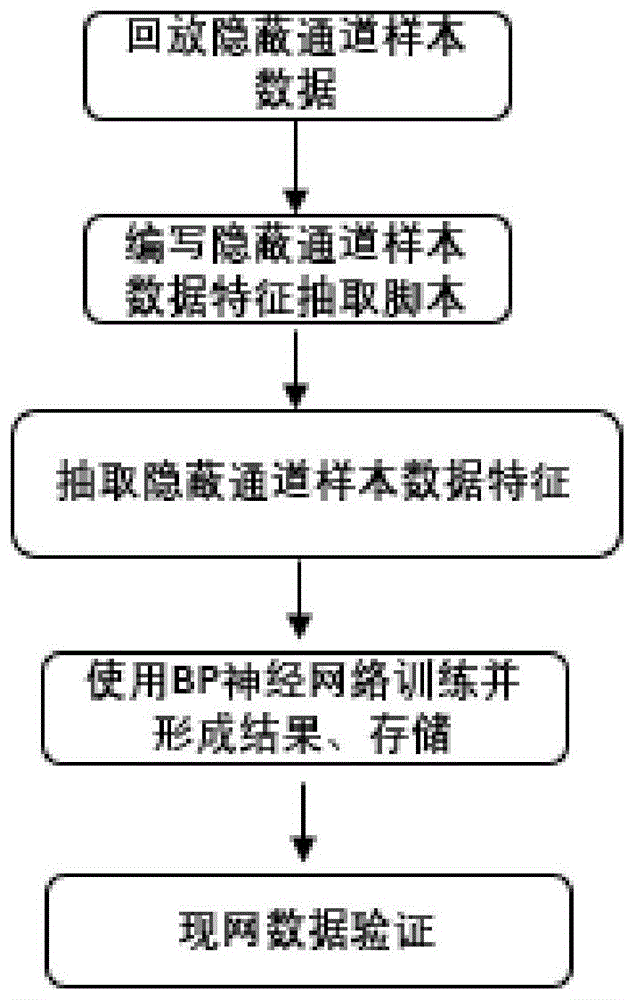
图1为本发明整体流程示意图。
具体实施方式:
为了加深对本发明的理解,下面结合附图对本实施例做详细的说明。
实施例1:一种通讯协议隐蔽通道检测方法,所述方法包括以下步骤:
步骤一:建立数据接收模块,将收集的相关网络协议数据进行回放,接收模块即第一处理模块根据不同协议的特征对相关数据进行抽取,形成第一特征数据;
步骤二:建立数据合法性特征抽取模块,即第二数据处理模块,其数据输入为第一数据处理模块,即数据接收模块所输出的相关数据,此处需要支持较多种类的数据特征抽取处理函数;
步骤三:利用上述定义的相关处理函数等,编写合适的、特征抽取脚本;
步骤四:将步骤三中形成的相关特征向量输入到bp神经网络,其中每个特征代表一个神经元,建立网络数据特征训练模块,在此模块中需要对第二特征数据进行训练,形成第三特征数据(仅包含一些数字特征),用于检验实际数据,此模块被称作第三模块;第三特征数据是最终形成的特征数据;
步骤五:将步骤四生成的第三特征数据进行保存并作为在实际系统中使用的内容,即通过在现场生成具有同样结构和权重的神经网络,对相关流量数据进行检查,如出现反向数据则直接进行报警,其输出值(介入0和1之间)可以做作为相关置信度数据放入报警中。
所述步骤一中,抽取的规则按照如下方式进行定义:
协议名称:如dns、icmp等;
描述:非强制填写;
协议匹配和抽取规则以及字段名称:匹配和抽取规则主要依赖于正则进行处理非定长数据;当然,它也兼容了一般的匹配和抽取规则用以抽取定长数据(一般为二进制数据,形式类似如:起始偏移(可选),正则表达式(必填),抽取长度,最大匹配深度,最大匹配长度,是否忽略大小写;其中正则表达式支持使用二进制方式匹配,以处理非纯文本情况;抽取完的数据会相应地将数值赋给某个字段,形成元数据;另外,对于特别难于用正则处理的数据支持使用基于lua的脚本进行编程处理,在lua脚本中可以对相关字段进行赋值并输出;
数据转换:提供一定的函数,对相关需要进行内容转换的字段进行基础处理或变换,比如可将ip地址根据地理信息位置转换国别、省、市等;
形成第一特征数据,作为第二处理模块的输入。
所述步骤二中,建立数据合法性特征抽取模块,即第二数据处理模块,其数据输入为第一数据处理模块,即数据接收模块所输出的相关数据,此处需要支持较多种类的数据特征抽取处理函数,如下:
■支持字符串长度特征抽取处理;
■支持字符串大小写分布特征抽取处理;
■支持字符串字符和数字分布特征抽取处理;
■支持字符串香农信息熵特征计算处理;
■n-gram平均转移概率特征抽取;
■支持ip地址位置国别分布特征抽取处理;
■支持获取指定时间段内某对象访问次数;
■支持获取指定时间段内某对象访问流量大小;
■支持获取指定时间段内某对象访问数据包数量。
另外,针对特定协议,如dns协议等,还可以获取诸如域名的排名(是否在常见域名的前一千万名以内等)、元音分布特征获取、辅音分布特征获取、连续辅音分布特征等等。
所述步骤三中,利用上述定义的相关处理函数等,编写特征抽取脚本,具体如下,针对dns隐蔽通道数据传输的特点,包括获取如下特征:
■域名长度特征:因为一般黑客利用dns传输数据会将相关信息放在域名中,然后利用dns请求的相关特性,将此信息发送出去,为了能快速的将数据传送出去,一般此域名会很长,这有别于一般的域名,但其顶级域名(tld)一般是固定的;
■顶级域名排名特征:可以对顶级域名的排名情况进行检查,如不在常见的topn域名排名内则将其设置为相应的特征值;
■域名组成特征:通过对域名拼写特征的检查,抽取相关特征,这些包括域名的熵值、连续辅音组成特征、元音分布特征、3-gram字符平均转移概率(即连续三个字符在正常域名中三字母平均转移概率);
■dns请求和响应比例:对于利用dns隐蔽通道传输敏感数据而言,黑客的目的仅是为了将这些数据传送到接收服务端,故此比例一般偏高,即请求数据包的数量一般远远高于响应数据包的数量;
■单位时间dns流量吞吐特征:对于黑客而言,因为需要通过此类方式传输大量的敏感数据,而利用dns的域名进行泄漏时,一次不可能传输太多数据,因为根据dns协议约定,域名不能设置过长,所以需要多个dns请求数据方能将相关数据传输完成;
然后,将标识为正常以及异常的数据输入到第二模块,根据定义的相关特征抽取脚本,对特征进行城区,在高维空间形成相关向量。
所述步骤四中,具体如下,本发明使用三层神经网络,其中输出采用两个神经元,一个为正向(即正常数据),另一个为反向(即异常数据),中间隐层采用96个神经元,系统采用交叉熵的方法评估误差,结束条件为迭代次数设定为2000次或误差在0.0001内;为了避免欠拟合或过拟合的发生,本发明采用平方正则化方法,其误差评估公式如下:
在上面的公式中,第一部分为基于交叉熵的误差评估,而后一部分则为平方正则化部分(平方正则化即基于二范数的正则化);其中
■总体流程:
算法:训练隐蔽通道检测反向传播神经网络
输入:规格化后的n个通讯采样数据
输出:隐蔽通道检测反向传播神经网络(主要是各层连接边的权值及其偏置)
初始化各层的相关参数,即对于层变量l=2,3...,l而言,用随机数初始化
while(t<tor|e|>e){
for(xk∈x){
正向传递计算;
计算误差并累计至中间变量;
反向传播;
结束。
■正向训练
正向训练算法伪代码如下:
算法:基于隐蔽通道检测的反向传播神经网络正向计算
输入:一个样本点及l层带权神经网络
输出:神经网络输出向量
在上述算法中,neuron是神经元,value是神经元的值,而bias是神经元的偏置,σ(x)是激活函数,使用sigmoid函数,其导数就是1-σ(x)。
■反向传播
反向传播算法伪代码如下:
算法:基于隐蔽通道检测的反向传播神经网络逆向反馈计算
输入:一个样本点及l层带权神经网络
输出:待调整参数偏差累计和(对于一个样本点而言暂时不会调整各个参数)
在上述公式中delta_weight_sum是权重累计变化值,而delta_bias_sum则是偏置累计变化值。
最后的训练结果在数组w中。
所述步骤五中,将步骤4生成的第三特征数据进行保存并作为在实际系统中使用的内容,即通过在现场生成具有同样结构和权重的神经网络,对相关流量数据进行检查,如出现反向数据则直接进行报警,其输出值(介入0和1之间)做作为相关置信度数据放入报警中。
该方案使用经过训练过的前馈神经网络用于检测可能存在隐蔽通道通讯,具有更好的识别率,而且由于采用神经网络方法,系统一般也无需使用数量庞大的特征库(一般动辄数量达上千万的特征库),从而减少了应用的内存占用。
需要说明的是上述实施例仅仅是本发明的较佳实施例,并没有用来限定本发明的保护范围,在上述技术方案的基础上做出的等同替换或者替代,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!