一种基于多维特征图的木马检测方法与流程
本发明涉及一种基于多维特征图的木马检测方法,属于恶意代码检测领域。
背景技术:
恶意代码检测技术是指使用一种分析技术对未知文件进行识别,识别其是否为正常文件或者为恶意文件,分析技术有很多种,主要有静态检测技术和动态检测技术。
静态检测技术主要是分析文件本身,或者分析对文件进行简单处理后的文件,常见的就是分析pe文件,pe文件中包含了很多信息,比如文件头信息,dll列表信息,api调用信息等等,分析这些信息,找出其中的信息规律,就能够识别其文件是否为恶意文件。
动态检测技术是一种非常实用的检测技术,但是该检测技术操作难度大,并且对试验环境要求高,这样的高要求使得检测的准确率非常高,该检测技术主要工作是将未知文件放入虚拟环境中进行运行,并且该环境需要与外界隔离,但是隔离的同时也需要尽量保证是一种真实的环境,这样的作法主要是为了防止未知文件识别出该环境为虚拟环境,将未知文件放入虚拟环境中运行,监测该未知文件的运行过程的信息,最后将这些信息进行对比,使用一些规则方法提取,用于识别未知文件是否为恶意文件。
shultz在2001年从恶意文件中提取了dll相关信息作为特征,首次使用数据挖掘技术用于恶意代码检测,使用签名方法进行比较,该方法的准确率明显高于签名扫描方法的准确率。johannes在2005年将ctl语义规则进行了创新,并首次将该方法用于恶意代码检测中,实现了一种高效的恶意代码检测模型。戴敏在2006年使用pe文件进行特征提取,将pe文件信息进行了重要性划分,然后根据pe文件特征的重要性使用决策树进行特征筛选,该方法通过实验证明了其有效性。杨彦在2008年提取了pe文件中的api函数调用序列作为特征模型,并首次使用扩展攻击树将恶意文件与正常文件的api函数调用集合进行对比,通过实验表明,在一定程度上能够识别恶意程序。tang在2009年使用了各种分类器算法,对pe文件信息进行提取,然后判断该pe文件是否为恶意代码的pe文件。tian在2010提取了恶意软件运行是的api调用序列和调用日志作为特征,然后使用分类学习算法进行识别,试验表明该方法在一定程度上能够识别恶意代码。jin在2010年使用pe文件信息作为特征,首次使用动态攻击树模型将恶意软件和正常软件进行对比,找出两者之间的不同之处。rieck在2011年提出一种使用机器学习来分析恶意程序的方法。该框架可以识别具有相似行为的恶意软件,并提供恶意软件的类别列表。将聚类算法和分类算法相结合,形成了一个恶意代码检测模型,处理速度快,并且有较好的分类准确率。baldangombo在2013年通过提取pe文件信息作为特征,使用信息增益算法对这些特征进行特征筛选,然后使用pca主成分分析对筛选出来的特征向量进行降维,最后使用j48分类器构建一个恶意代码分类系统。梁光辉在2016年通过搭建虚拟环境,获得恶意代码运行时的api函数调用序列,使用这些序列构建了api函数关系链,并且根据这个关系链,计算出了恶意程序与正常文件之间的差异与相似,在一定程度上能够识别恶意代码。huang等人在2016年基于神经网络构建了一个恶意代码家族分类模型。该模型对450万个样本进行训练,并用200万个样本进行测试,恶意代码分类的准确率高达97.06%。
技术实现要素:
本发明针对目前特洛伊木马种类繁多,形态各异,给检测技术带来困扰的问题,提出一种基于多维特征图的木马检测方法。
本发明通过以下技术方案实现:
一种基于多维特征图的木马检测方法,包括:
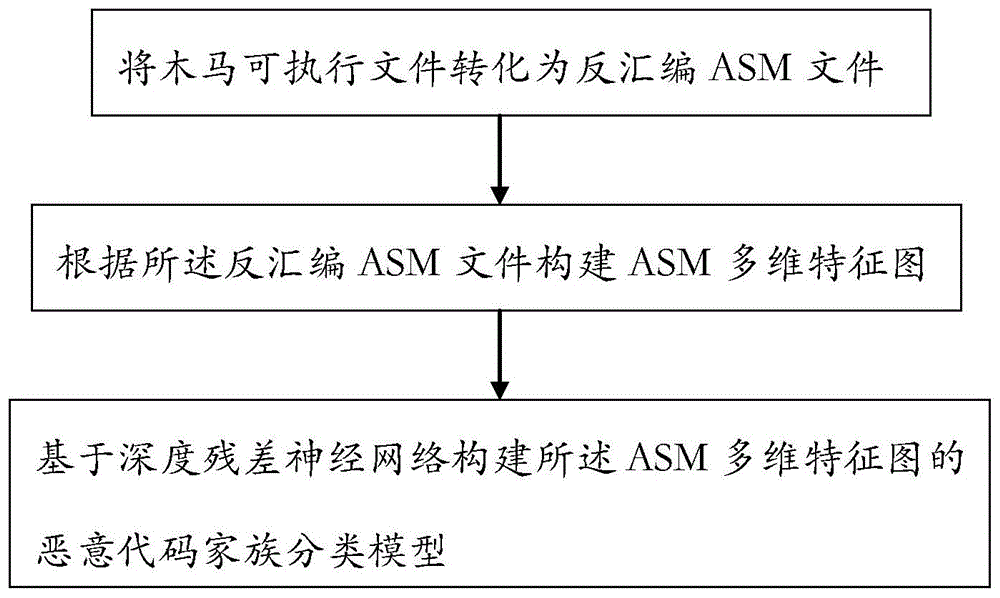
将木马可执行文件转化为反汇编asm文件,根据所述反汇编asm文件构建asm多维特征图,基于深度残差神经网络构建所述asm多维特征图的恶意代码家族分类模型。
所述构建asm多维特征图具体包括:
对所述反汇编asm文件中的操作码opcode序列进行k序列去重操作,生成多维特征图的第一维特征;
根据去重的操作码opcode序列构建n-gram序列,生成多维特征图的第二维特征;
以所述去重的操作码opcode序列作为基础,找出操作码opcode序列对应的n-gram序列,然后进行赋值,作为多维特征图的第三维特征。
本发明的有益效果:
1、相比于常规方法对操作码opcode序列进行n-gram处理提取n-gram频率序列的等提取文本统计特征的方式,本发明提出了从恶意代码反汇编asm文件中提取操作码opcode序列,通过操作码opcode序列构建asm多维特征图,保留了操作码opcode序列的相对完整性,并将asm文件可视化,作为图像进行进一步处理。
2、本发明在上述多维特征图的基础上,改进了恶意代码家族的神经网络分类器,根据木马的多维特征图特性与尺寸设计深度神经网络模型,构建了基于残差神经网络和木马多维特征图的恶意代码家族分类器。
附图说明
图1为本发明实施例中基于多维特征图的木马检测方法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。
本发明的实现思想:在恶意代码反汇编asm文件中,操作码opcode序列是一个非常重要的特征,虽然操作码是非常重要的特征,但是该特征无法直接使用,该序列需要经过一些处理与分析。本发明从恶意代码反汇编asm文件中提取了操作码opcode序列,通过对该操作码opcode序列构建多维特征图的方法,保留操作码opcode序列的相对完整性。
如图1所示,本实施例中基于多维特征图的木马检测方法,具体包括:
步骤一、将木马可执行文件转化为反汇编asm文件;
在本实施例中,将所述木马可执行文件转化为反汇编asm文件之前先进行加壳检测,如果程序加壳,则进行脱壳处理。
所述asm文件,是汇编语言源程序的扩展名。它是面向机器的程序设计语言,是一种利用计算机所有硬件特性并能直接控制硬件的语言。
所述加壳,是指对程序以一种特定的方式进行打包。现在绝多数恶意代码都会使用加壳器,所述加壳器能够使恶意代码逃避检测,使得对恶意代码分析变得非常困难,并且会使得恶意代码体积缩小。现有的分析技术无法对加壳后的恶意代码起作用,所以对恶意代码分析时,先对恶意代码进行脱壳处理。本实施例中使用ollydbg软件采用单步跟踪法进行脱壳。
本实施例中经过脱壳的恶意代码再进行反汇编分析,以脱壳后的可执行文件作为输入,反汇编asm文件作为输出。
本实施例使用idapro软件进行反汇编,所述idapro软件是交互式反汇编器的专业版(interactivedisassemblerprofessional)。
步骤二、根据所述反汇编asm文件构建asm多维特征图;
在本实施例中,所述构建asm多维特征图具体包括:
一、对所述反汇编asm文件中的操作码opcode序列进行k序列去重操作,生成多维特征图的第一维特征;
恶意代码为了掩盖自己真正的行为,往往会在其中增加很多多余的功能,这些功能在操作码序列中就是一些垃圾指令,但是这些指令影响了传统的数据挖掘技术,会得到许多垃圾的指令信息,导致对恶意代码分析出错。这些垃圾指令有两个明显的特点:大量和连续,这样的会使得恶意代码的操作码序列非常的冗长。根据恶意代码的上述特点,本发明对操作码opcode序列进行k序列去重操作,用于生成多维特征图的第一维特征。下面是具体生成流程:
1、对每个所述反汇编asm文件提取操作码opcode序列;
2、对所述操作码opcode序列进行k序列去重;
3、对去重后的操作码opcode序列包含的操作码进行数字化,得到多维特征图的第一维特征。
所述对所述操作码opcode序列进行k序列去重,具体包括:
①定义k序列:表示由k个操作码组成的序列;
②判断所述操作码opcode序列中是否存在连续且相同的k序列,且存在数量大于m,则说明k序列重复;
③保留m个序列,去除其余重复k序列;
④重复步骤①至③,直到序列中不存在连续且相同的k序列。
所述对去重后的操作码opcode序列所包含的操作码进行数字化,具体包括:
①统计所述去重后的操作码opcode序列中的不同操作码出现的次数,并按照次数进行大小排序;
②取前22n的操作码进行编号1~22n,保留0位,每一个操作码对应一个数,该数在1~22n之间;不是前22n的操作码统一为0。实验证明,通过统计了所有的操作码,前255的操作码数量占总数量超过99%。
③根据步骤②的编号规则,将操作码数字化。
二、根据所述的k序列去重的操作码opcode序列构建n-gram序列,作为多维特征图的第二维特征;
在本实施例中,所述n-gram是指给定的一段文本或语音中n个项目的序列,它是计算机语言学和概率论中的概念。通常n-gram来自文本或者语料库。
在本实施例中,所述根据所述的k序列去重的操作码opcode序列构建n-gram序列,具体包括:
(1)对每个k序列去重后的操作码opcode序列提取操作码n-gram序列;
(2)统计每个操作码n-gram序列出现的次数,并将所述次数放入map中保存;
(3)对所述map中所有的次数进行归一化处理,乘以255,将结果作为多维特征图的第二维特征。
所述保存的格式为:(key,value),其中key表示所述操作码n-gram序列,value表示所述操作码n-gram序列出现的次数。
三、以所述k序列去重的操作码opcode序列作为基础,找出操作码opcode序列对应的n-gram序列,然后进行赋值,作为多维特征图的第三维特征。
所述找出操作码opcode序列对应的n-gram序列,然后进行赋值,具体包括:在k序列去重后的操作码opcode中以n为窗口大小,提取出每个n元组,与所述map中的key进行比对:
①如果存在,则记录连续n个value作为特征,窗口步长为n;
②如果不存在,则记录一个0作为特征,窗口步长为1。
步骤三、基于深度残差神经网络构建所述asm多维特征图的恶意代码家族分类模型;
本实施例所述的恶意代码家族分类模型,具体为:
第一层为输入层;第二层为卷积层;第三层、第四层、第五层为一个整体结构,是整个神经网络的第一个残差结构;第六层、第七层为一个整体结构,是整个神经网络的第二个残差结构;第八层、第九层、第十层为一个整体结构,是整个神经网络的第三个残差结构;第十一层、第十二层为一个整体结构,是整个神经网络的第四个残差结构;第十三层为平均池化层;第十四层、第十五层为深度卷积神经网络结构的全连接层,为输出层。
在本实施例中,恶意代码家族分类模型具体设计为:
(1)第一层
第一层为输入层,该层是为了将输入数据导入深度神经网络中,本实施例中,多维特征图的大小取48×48×3,因此该层使用48×48×3特征矩阵神经元来接收输入数据。
(2)第二层
第二层为卷积层,将所述输入层的48×48×3特征矩阵转换为单层矩阵48×48×1,便于后面卷积操作和池化操作;提取所述输入层48×48×3特征矩阵中的细粒度数据,并使用64个卷积核进行操作,得到64个不同的特征图,增加特征图的特征多样性。
该层包含64个尺寸为2×2×3的卷积核,采用64个卷积核对48×48×3的特征矩阵向量细粒度扫描提取:卷积操作的步长为2。
(3)第三层、第四层、第五层
第三层、第四层、第五层为一个整体结构,是整个神经网络的第一个残差结构。本实施例中所述残差结构由四个卷积层和四个批量标准层构成,分为两部分,第一部分看做3个卷积层做卷积操作,其中卷积核尺寸分别为1×1,3×3,1×1。本实施例中使用两个1×1的卷积核有下面几个原因:
1、通过改变卷积核的数量,实现通道数大小的放缩。
2、1×1卷积核的卷积过程相当于全连接层操作,由于加入非线性激活函数,网络中非线性增加,使得网络具有很强的表达能力。
3、可以减少大量参数。使用1×1确保效果的同时,减少了计算量。
虽然传统的梯度下降法训练神经网络非常高效,但是这种高效是有前提的,必须有适合的参数,这些参数的选择直接影响了整个神经网络的运行效率。假如,我们不需要调整参数的话,神经网络学习起来就会更加简单,本实施例中使用批量标准层完美的解决了这个问题。
(4)第六层、第七层
第六层、第七层为一个整体结构,是整个神经网络的第二个残差结构。由三个卷积层和三个批量标准层构成。该结构可以分为两部分,第一部分可以看做为两个卷积层做卷积操作;第一个卷积核尺寸为3×3,256个卷积核,步长为1,为了卷积操作之后的特征矩阵尺寸与原输入尺寸相同,将每层的像素填充一个像素;第二个卷积核尺寸为3×3,256个卷积核,与第一个卷积核不同的是,它的步长为2,卷积操作之后使得输出的特征矩阵尺寸减半,尺寸变成12×12×256。
由于第一部分的尺寸输出减半,相应的第二部分也会尺寸减半。第二部分的卷积核尺寸为3×3,256个卷积核,步长为2。
(5)第八层、第九层、第十层
第八层、第九层、第十层为一个整体结构,是整个神经网络的第三个残差结构。由四个卷积层和四个批量标准层构成,该残差结构与第一个结构相同,分为两个部分,第一部分有三个卷积核,第一个卷积核尺寸为1×1,个数为256,步长为1,不需要填充;第二个卷积核尺寸为3×3,个数为256,步长为1,每层需要填充一个像素;第三个卷积核尺寸为1×1,个数为1024,步长为1,不需要填充;第二部分有一个卷积核,卷积核尺寸为1×1,个数为1024,步长为1,不需要填充。
(6)第十一层、第十二层
第十一层、第十二层为一个整体结构,这里将残差结构和inception结构相结合。由五个卷积层和三个批量标准层构成。该结构也分为两个部分,第一部分有四个卷积核,前三个卷积核是一个inception结构。其他卷积操作类似于第二个残差结构卷积操作。
所述inception结构所含三个卷积核的卷积尺寸尺寸分别是1×1,3×3,5×5。inception结构没有明显的增加网络深度,达到的增加网络深度和宽度的效果,解决了传统神经网络增加深度和宽度之后的过拟合、计算复杂度变大、梯度弥散等问题。
该结构的第一部分的第四个卷积核尺寸为3×3,512个,步长为2,所以输出的矩阵大小会减少一半,为6×6×1024,该结构的第二部分也是相同的卷积核,由于输入和输出的尺寸变化,所以shortcutconnections(捷径连接)为虚线连接。
(7)第十三层
第十三层为平均池化层,目的是将输入矩阵拉直,并且控制输出向量维度,优化计算,方便训练。将输出矩阵尺寸为6×6×1024转化为尺寸1×1×1024的输出矩阵。具体的池化公式如下:
式中,xij为上一层输入的矩阵向量,average()函数表示取平均值操作,y输出表示一次池化操作的输出。
(8)第十四层、第十五层
第十四层、第十五层都是本实例网络结构的全连接层,该全连接层为输出层。第十四层利用256个神经元将1024维向量转化为256维向量。转化规则公式为:
其中w和b表示网络参数,xi表示第i处的向量值,activation_func为该层节点所用的激活函数。
第十五层与第十四层类似,具体的设定为:利用9个神经元将256维向量转化为9维向量,转化公式与十四层类似。本实例是将恶意代码按家族分为九大类,输出层的激活函数使用softmax函数。
为了得到实验的最优解,本实施例中网络内部参数设置如下:
(1)激活函数选择
本实验选用了relu激活函数作为激活函数。
(2)参数初始化选择
因为使用了批量标准层,所以对于参数初始化而言,不需要做太多处理,网络模型的参数初始化采用区间均匀随机取值的方式。
(3)优化器算法选择
网络模型使用adam优化器算法,该优化器算法同样也会记录一阶梯度变化率,并且会更进一步记录二阶梯度变化率,然后使用这些变化率来修正权重偏差,进而更新权重。
- 还没有人留言评论。精彩留言会获得点赞!