一种冬小麦叶片氮含量估算模型的建立方法与流程
本发明涉及一种冬小麦叶片氮含量估算模型的建立方法。
背景技术:
小麦是重要的粮食作物,在全球范围内广泛分布。我国作为小麦的主产国之一,小麦的生产效率就显得尤为重要。提高小麦的生产效率,可以解决我国的粮食储备安全问题,进而实现我国的粮食战略目标。氮素是作物生长的重要养分,影响作物产量,但过量施氮会污染农田生态坏境。对作物及时准确做出营养诊断,并根据诊断结果,制定施肥管理措施,有助于提高肥料利用率,改善农田生态环境,对农业的可持续发展有着重要的意义。
目前,作物氮营养无损诊断方法为多光谱及遥感方法。基于作物冠层的多光谱反射率的航空以及卫星遥感技术适用于监测大尺度下的作物长势和氮素营养状态,且受时空分辨率的限制,导致操作难度大,成本高。基于光谱学原理的地面遥感技术中,便携式叶绿素仪(soilandplantanalyzerdevelopment,spad)虽然快速无损测定叶绿素相对含量,但对作物的氮饱和状态不敏感,且测定结果受到品种、生长期等因素较大的影响。植物冠层光谱仪greenseeker、asd等获取的冠层光谱数据是包含背景因素的混合光谱,而背景因素影响作物冠层光谱的准确获取。作物的叶片会根据自身不同的营养状态,呈现差异性的颜色和形态,以此反映自身生理状况。有研究表明,基于连续投影算法提取光谱数据的波长位置,大部分位于可见光区域,光谱数据对叶片氮含量(leafnnitrogenconcentration,lnc)最有研究意义的前两个波段均在可见光区域。由此可见,可见光区间对lnc较为敏感。
相关研究成果显示,不同作物,与之营养参数相关的图像参数各不相同。李红军[1]和白金顺[2]的研究发现,与拔节期小麦和灌浆期玉米氮素营养相关性较好的是作物冠层的红光标准值(normalizedrednessintensity,nri)。karcher等试验发现,hsv空间下深绿指数(darkggreencolorindex,dgci)与草地氮素水平、玉米叶片含氮量存在线性相关性。wang[3]等分析发现hsv颜色空间的h分量和颜色空间的分量与水稻叶片氮含量存在显著相关性。王方永[4]等研究表明hsi空间的s分量以及颜色空间的分量分别与棉花的氮素浓度、spad值的相关关系明显。rigon[5]分析了rgb、hsb和空间下各颜色分量估算spad的线性模型,认为nri、s以及分量与spad值线性关系最强。
可见,作物生长状况受品种、生育期等多个因素的影响,表征作物营养信息的图像参数随之变化。而任何一种颜色分量的变化都会引起作物冠层叶色不同程度的改变,冠层叶色又与氮含量密切相关。上述研究或利用图像单一颜色分量与作物营养指标拟合线性回归方程,未考虑剩余颜色分量对营养检测的影响;或研究单一颜色空间下构建的颜色指数与营养指标的关系,未对比其他颜色空间下构建的营养评价指标。su[6]和riccardi[7]综合考虑rgb空间下的各颜色分量,基于最小二乘法建立了估算微藻和藜麦叶绿素含量的多元线性回归(multivariatelinearregression,mlr)模型,均取得了较好的效果。在此基础上,agarwal研究了多个颜色空间下估算菠菜spad的线性模型,指出空间下的mlr算法模型优于其他颜色空间下的。为提高估算精度,梁亮等比较了线性回归方法和支持向量回归(supportvectorregression,svr)算法遥感反演小麦冠层叶绿素的效果,发现支持向量回归显著提高了反演精度。王丽爱等比较了遥感估算小麦叶片spad值的3种机器学习算法模型效果,提出较支持向量回归和人工神经网络,随机森林(randomforest,rf)算法的学习和回归预测能力在小麦多个生育期估算效果最优。
大量研究基于高光谱,利用机器学习算法进行农学参数估算,缺少对不同算法泛化性能的比较。另外,基于冠层图像可见光颜色分量来估算农学参数的研究较少。
参考文献:
[1]李红军,张立周,陈曦鸣,张玉铭,程一松,胡春胜.应用数字图像进行小麦氮素营养诊断中图像分析方法的研究[j].中国生态农业学报,2011,19(01):155-159.
[2]白金顺,曹卫东,熊静,曾闹华,志水胜好,芮玉奎.应用数码相机进行绿肥翻压后春玉米氮素营养诊断和产量预测[j].光谱学与光谱分析,2013,33(12):3334-3338.
[3]estimatingricechlorophyllcontentandleafnitrogenconcentrationwithadigitalstillcolorcameraundernaturallight[j].plantmethods,2014,10(1):36.
[4]王方永,王克如,李少昆等.利用数码相机和成像光谱仪估测棉花叶片叶绿素和氮素含量[j].作物学报,2010,36(11):1981-1989.
[5]rigonjpg,capuanis,fernandesdm,etal.anovelmethodfortheestimationofsoybeanchlorophyllcontentusingasmartphoneandimageanalysis[j].photosynthetica,2016,54(4):559-566.
[6]such,fucc,changyc,etal.simultaneousestimationofchlorophyllaandlipidcontentsinmicroalgaebythree-coloranalysis[j].biotechnology&bioengineering,2010,99(4):1034-1039.
[7]riccardim,meleg,pulventoc,etal.non-destructiveevaluationofchlorophyllcontentinquinoaandamaranthleavesbysimpleandmultipleregressionanalysisofrgbimagecomponents[j].photosynthesisresearch,2014,120(3):263-272.
技术实现要素:
本发明的目的是针对现有技术中存在的不足,提供一种冬小麦叶片氮含量估算模型的建立方法,发明人通过分析不同品种、不同种植方案(不同种植密度水平、不同施氮水平)下各基础图像参数对叶片含氮量的表征能力,在各颜色空间内通过各算法构建模型,并通过衡量指标分析比较算法模型的拟合能力与泛化性能。最终确定在3个常用颜色空间(rgb、hsv、l*a*b*空间)融合的多颜色空间下,借助径向基核函数构建ε-svr模型,具有较高的预测精度,有着更好的泛化性能。基于本发明冬小麦叶片氮含量估算模型可对小麦叶片氮含量进行快速无损检测。
本发明的目的是通过以下技术方案实现的:
一种建立冬小麦叶片氮含量估算模型的方法,包括如下步骤:
步骤(1)、取样:采集小麦冠层图像,测定小麦叶片氮含量;
步骤(2)、利用冠层图像h分量的k均值聚类方法分割小麦冠层图像,提取分割处理后冠层图像的非0像素值的r、g、b、h、s、v、l*、a*、b*分量,分别计算其平均像素值作为基础颜色分量,构建融合三个常用颜色空间的多颜色空间,多颜色空间的基础颜色分量为3种颜色空间下的9种基础颜色分量;
步骤(3)、以图像在多颜色空间下的基础颜色分量作为模型自变量,以叶片氮含量作为模型因变量,选用径向基核函数,建立ε-svr模型。
步骤(1)中,小麦冠层图像的获取方法:在小麦拔节期,采用单反相机奥林巴斯e-620,相机设置为自动白平衡;在晴朗天气下,距小麦冠层1m高度、与地面90°拍摄采样。
叶片氮含量的测定方法:小麦冠层图像拍摄当天选择20株长势相近植株进行破坏性取样,采用凯氏定氮法测定小麦的叶片氮含量lnc。
样本点采自不同年份、不同品种、不同种植密度、不同施氮水平。
步骤(2)中,三个常用颜色空间为hsv颜色空间、l*a*b*颜色空间、rgb颜色空间。
步骤(3)中,对于训练样本d={(x1,y1),(x2,y2),…,(xi,yi),…,(xm,ym)},xi是由图像在多颜色空间下的基础颜色分量组成的向量,yi是小麦叶片氮含量;发明人希望能够学习到一个f(x)使得其与y尽可能的接近:f(x)=ωtx+b;
其中,ω和b是待求解的模型参数。在这个模型中,只有当f(x)与y之间完全相同时,损失才为零。
假设能容忍模型输出f(x)与真实输出y最多有ε的偏差,也就是当模型输出和真实输出差别的绝对值大于ε时,才会计算损失。
那么,支持向量回归问题可转化为下式:
其中,c是正则化常数,低的c值使分界面平滑,高的c值通过增加模型自由度以选择更多支持变量来确保所有样品都被正确分类,lε是关于ε的不敏感损失函数,如下式所示:
引入松弛变量ξi、
引入拉格朗日乘子μi≥0,
对ω和b求偏导数,令其为零,可得:
将其带入拉格朗日函数
从而得到支持向量回归的对偶问题,如下式:
该过程需要满足kkt条件,即:
可以解得支持向量回归模型为:
其中:
若考虑将样本映射到高维特征空间,则支持向量回归基础式可化为:
f(x)=ωtφ(x)+b;
其中φ(x)表示样本x映射到高维空间后的特征向量。
求解该式会涉及到φ(xi)tφ(xj),这是样本xi和xj映射到高维空间的内积,由于特征空间的维度较高,通常直接计算该值较为困难。要避开这个困难,通常假设k(xi,xj)满足:
k(xi,xj)=φ(xi)tφ(xj);
k(xi,xj)即为核函数。本发明使用径向基核函数:
k(xi,xj)=exp(-γ||xi-xj||2),γ>0;
其中,γ是自由参数,定义了单个训练样本的影响大小,可看做被模型选中作为支持向量的样本的影响半径的倒数,值越大影响越小,值越小影响越大。
从而可以得到在高维空间下的ε-svr模型:
其中:
正则化常数c与核函数参数γ的范围均从0.01到100,以步长10变化;最佳参数以10折交叉验证和网格搜索法确定。
本发明的另一个目的是提供一种冬小麦叶片氮含量估算的方法,包括以下步骤:
步骤(1)、获取待测田块的小麦冠层图像,用基于h分量的k均值聚类方法分割提取小麦冠层图像,计算9种颜色分量r、g、b、h、s、v、l*、a*、b*的平均像素值作为基础颜色分量,将rgb、hsv、l*a*b*这3种常用颜色空间融合为多颜色空间,其基础颜色分量为3种颜色空间下的9种基础分量;
步骤(2)、以多颜色空间下的基础颜色分量作为模型自变量,以叶片氮含量作为模型因变量,借助径向基核函数,构建ε-svr模型;
步骤(3)、以多颜色空间的基础颜色分量作为模型自变量,以叶片氮含量作为模型因变量,将步骤(1)中获得的小麦冠层图像在多颜色空间下的9种颜色基础分量作为自变量代入到ε-svr模型中,得到预测的小麦叶片氮含量。
本发明法中所有参数的定义及计算方法同上述一种小麦叶片氮含量估算模型的建立方法。
本发明的有益效果:
1、本发明方法通过对不同品种、不同种植密度水平、不同施氮水平,在三种基础颜色空间与融合的多颜色空间下,多元线性回归、支持向量回归和随机森林三种不同的算法建立的模型得到的小麦叶片氮含量预测值与实际值的拟合程度进行分析,表明在多颜色空间下的支持向量回归算法具有较高的预测精度;
2、采样数码相机进行图像的数据采样,方法简便,设备(相机)费用低,方便实际大田环境下的应用;
3、对作物叶片含氮量进行量化评价,可指导农民进行合理施肥,即保证植物所需的氮肥,又可避免过量施肥,提高产量,避免过量施肥污染环境;
4、估计模型的构建方法可以适用于其他作物,但需要参照该方法对不同作物的图像采样数据进行分割并提取其基础颜色分量,从而构建多颜色空间。
附图说明
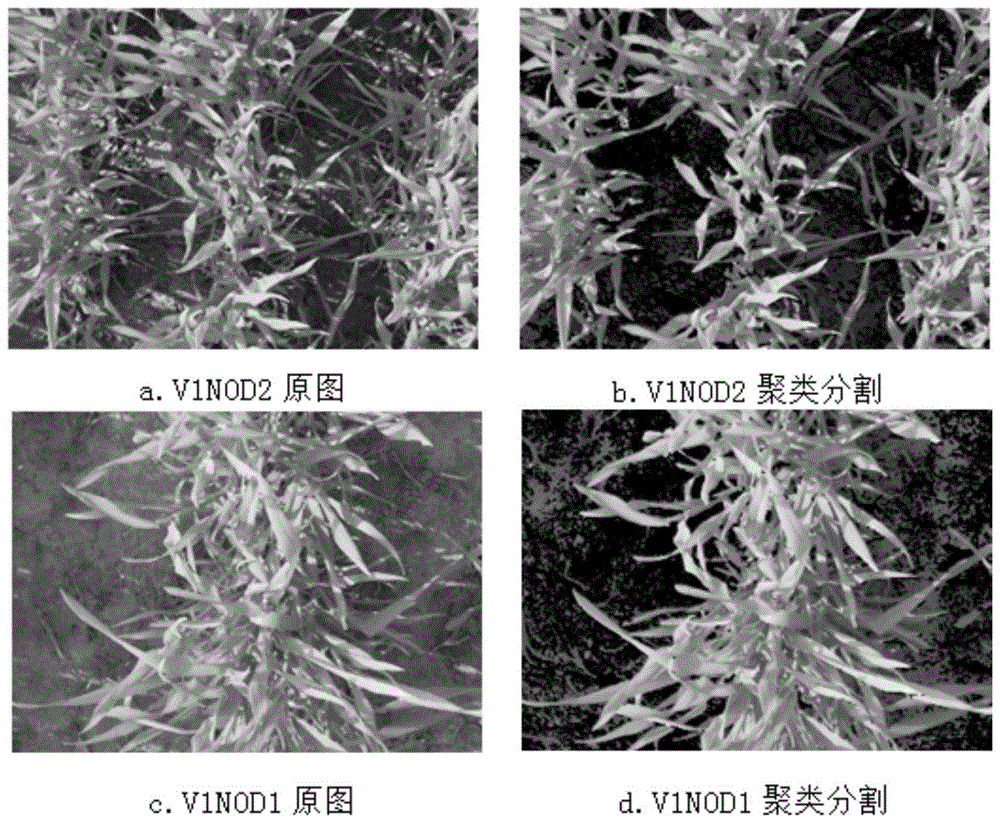
图1为小麦冠层图像分割效果图;其中,v1n0d2是生选6号、不施氮、行距20cm(3.0×106株/hm2)的试验小区冠层图像;v1n0d1是生选6号、不施氮、行距40cm(1.5×106株/hm2)的试验小区冠层图像。
具体实施方式
1实验与数据
1.1实验设计
2012-2014年,于国家信息农业中心如皋(北纬32°~32°30′、东经120°20′~120°50′)试验基地稻麦轮种田,采用随机裂区设计,12个处理方案,重复3次,共36个试验小区。小区面积35m2(7m×5m),条播,总面积约1080m2。2个供选品种:生选6号(v1)、扬麦18号(v2);2个密度处理:d1(行距40cm,1.5×106株/hm2)、d2(行距20cm,3.0×106株/hm2),株距不变;3个氮肥水平:不施氮(n0)、纯氮150kg·hm-2(n1)、纯氮300kg·hm-2(n2),其中氮肥50%作为基肥施于播种时,50%在拔节期追施(3月中旬)。
1.2数据采集与处理
1.2.1冠层图像采集
拔节期是小麦开花、结实积累养分的重要阶段,此时小麦快速生长,是监测氮素的重要时期。试验取样日期选择了2013年:3月14日(拔节中期),3月22日(拔节中期),4月1日(拔节后期);2014年:3月8日(拔节中期),3月31日(拔节后期),4月15日(拔节后期)。采用单反相机奥林巴斯e-620,相机设置为自动白平衡。在晴朗天气下,距小麦冠层1m高度、与地面90°拍摄采样。每区每次取样1次,36个小区取样36张小麦冠层图像。
1.2.2叶片氮含量的测定
小麦氮含量化学测定与冠层图像采集同期进行。拍摄当天,每个小区选择20株长势相近植株进行破坏性取样,采用凯氏定氮法测定小麦的叶片氮含量lnc。
1.2.3冠层图像处理
大田环境下背景复杂,表现为植株相互遮挡有阴影、光斑,土壤、石砾、杂草造成干扰。这些因素会造成误分割现象。为提高分割精度,利用冠层图像h分量的k均值聚类方法(黄芬,于琪,姚霞等.小麦冠层图像h分量的k均值聚类分割[j].计算机工程与应用,2014,(3):129-134.)分割小麦冠层图像。小麦冠层图像分割效果见图1,h分量的k均值聚类方法将相互遮挡有光斑的叶片与土壤较好分割开,同时叶片边缘细节得以较好地处理。分别计算提取分割处理后冠层图像的非0像素值的r、g、b、h、s、v、l*、a*、b*分量的平均像素值作为基础颜色分量;构建融合三个常用颜色空间(hsv颜色空间、l*a*b*颜色空间、rgb颜色空间)的多颜色空间。
1.3模型的构建
为评估模型的泛化性能,使用嵌套交叉验证:内层交叉验证用来选取模型参数,外层交叉验证用来估计模型泛化性能。嵌套交叉验证中,外层循环遍历数据分为训练集和测试集的所有划分,这样可以减少算法结果对于数据划分的依赖。对于外层循环的每种划分都运行一次网格搜索,每种划分下内层搜索得到的可能是不同的最佳参数。最后,对于外层循环的每种划分,利用最佳参数的模型得到测试集上的评价指标。嵌套交叉验证得到的评价指标可以衡量在网格搜索找到的最佳参数下模型的泛化能力。
1.3.1模型构建方法
采用3种不同的算法建立模型:多元线性回归、支持向量回归和随机森林。模型的自变量为颜色空间的基础颜色分量,因变量为叶片氮含量。
多元线性回归是描述多个自变量与一个因变量的线性模型。其模型参数通过最小二乘法来求取,使得该回归直线到样本的残差平方和最小。
对于训练样本d={(x1,y1),(x2,y2),…,(xi,yi),…,(xm,ym)},yi∈r,传统的回归模型,希望能够学习到一个f(x)使得其与y尽可能的接近:
f(x)=ωtx+b;
其中ω和b是待求解的模型参数。在这个模型中,只有当f(x)与y之间完全相同时,损失才为零。
与传统回归模型不同,支持向量回归假设能容忍模型输出f(x)与真实输出y最多有ε的偏差,也就是当模型输出和真实输出差别的绝对值大于ε时,才会计算损失。
那么,支持向量回归问题可转化为下式:
其中,c是正则化常数,低的c值使分界面平滑,高的c值通过增加模型自由度以选择更多支持变量来确保所有样品都被正确分类,lε是关于ε的不敏感损失函数,如下式所示:
引入松弛变量ξi、
引入拉格朗日乘子μi≥0,
对ω和b求偏导数,令其为零,可得:
将其带入拉格朗日函数
从而得到支持向量回归的对偶问题,如下式:
该过程需要满足kkt条件,即:
可以解得支持向量回归模型为:
其中:
若考虑将样本映射到高维特征空间,则支持向量回归基础式可化为:
f(x)=ωtφ(x)+b;
其中,φ(x)表示样本x映射到高维空间后的特征向量。
求解改式会涉及到φ(xi)tφ(xj),这是样本xi和xj映射到高维空间的内积,由于特征空间的维度较高,通常直接计算该值较为困难。要避开这个困难,通常假设k(xi,xj)满足:
k(xi,xj)=φ(xi)tφ(xj);
k(xi,xj)即为核函数。本发明使用径向基核函数:
k(xi,xj)=exp(-γ||xi-xj||2),γ>0;
其中,γ是自由参数,定义了单个训练样本的影响大小,可看做被模型选中作为支持向量的样本的影响半径的倒数,值越大影响越小,值越小影响越大。
从而可以得到在高维空间下的ε-svr模型式:
其中:
随机森林算法是决策树的集成,通过自助法从训练集中采样出n个子集来构建n棵树,每棵树的分裂节点从含有d个属性的集合中随机选取一个包含k个属性的子集,然后从这个子集中选择一个最优属性用于划分;训练好的n棵回归树,每棵树单独预测,对n个预测值的简单平均作为最终结果;自助采样使得剩下未被抽中的样本组成袋外数据,用于对泛化性能的袋外估计。
1.3.2模型评价标准
选取以下指标衡量算法模型得到的lnc预测值和小麦lnc实际值的拟合程度:
1)决定系数r2:相关系数的平方值,表明预测值解释实际值变差的程度,计算公式为:
式中yi为样本i的测量值,
2)均方根误差rmse(rootmeansquareerror):检验预测值和实测值的符合精度,计算公式为:
式中,yi是标准仪器方法测定的实际值,
2结果与分析
2.1颜色分量与氮营养指标相关性
表1为2012-2014年实验实测的小麦叶片氮含量与基础颜色分量之间的相关性分析结果。表1显示,除基础颜色分量a*,其余基础颜色分量与叶片氮含量均显著相关。每个颜色空间中的分量,两个与lnc呈负相关的颜色分量,一个呈正相关。按相关程度来看,颜色分量b*与lnc相关性最高,相关系数绝对值为0.69,b、h、s分量绝对值也都大于0.45,达到显著水平。
表1.颜色分量与叶片氮含量的相关系数
注:“**”表示该颜色变量与叶片氮含量在0.1水平上显著相关。
2.2叶片氮含量估算模型的构建与验证
以冠层图像基础颜色分量为自变量,小麦lnc为因变量,在3个常用颜色空间下构建估算模型。
支持向量回归(svr)模型的主要参数设置如下:核函数类型为径向基核函数;正则化常数c与核函数参数γ的范围均从0.01到100,以步长10变化;最佳参数以10折交叉验证和网格搜索法确定。
随机森林(rf)模型的回归树数目候选值为{100,200,400,800},用于划分回归树节点的k个属性,其候选值为
表2显示,l*a*b*颜色空间下,mlr、svr、rf训练集的r2分别为0.6803、0.8554和0.8748,较rgb颜色空间下,分别提高10.03%,6.58%和4.55%;mlr、svr、rf训练集的rmse分别为0.5006,0.3312和0.3131,较rgb空间下分别降低8.48%,15.49%和12.47%。hsv颜色空间下,mlr、svr、rf训练集的r2分别为0.7108、0.8773和0.8914,较rgb颜色空间下,分别提高14.96%、9.31%和6.54%;rmse分别为0.4761、0.3100和0.2916,较rgb空间下分别降低12.96%、20.90%和18.48%。结果表明,hsv颜色空间下,各算法训练集的r2最高,rmse最低;rgb空间下,各算法的r2最低,rmse最高。
由此可知,hsv颜色空间里各算法模型的学习能力优于l*a*b*颜色空间,l*a*b*颜色空间下模型的学习能力优于rgb颜色空间。分析认为,本实验数据包含高氮和缺氮水平的小麦lnc状况。高氮水平下小麦叶片叶绿素含量较高,导致导致植物冠层可见光波段的反射特征“绿峰”和“红边”的位置受到影响,表现为绿峰向蓝光方向偏移,波长变短,红边向长波方向移动。这导致了相关性较强的长波段红光反射率降低,相关性弱的短波段蓝光反射率升高。当小麦缺氮时,由于氮素的易运转特性,冠层老叶片的氮素会转向新叶片中,表现为植株下部的叶片先退绿黄化,逐渐扩展到上部叶片。以上因素可能造成rgb空间下,叶色信息的获取存在偏差。hsv和l*a*b*颜色空间通过对rgb基础颜色分量的非线性转换,一定程度上矫正了rgb颜色空间下叶色偏差。同时,rgb空间中包含亮度信息,而大田环境里,光照条件复杂,冠层图像受到土壤、杂草等干扰影响,hsv颜色空间下与小麦冠层叶色相关的基础颜色分量h、s与亮度v分离,l*a*b*颜色空间中色度a*、b*与亮度l*分离,因而减弱了大田复杂背景对冠层反射光谱的影响。
由表2可知,3个颜色空间下rf,训练集上的r2均大于svr,rmse均小于svr,可见rf学习能力优于svr。分析认为,rf是基于决策树的集成学习模型,该模型不对训练数据做出假设,且该模型参数很多,扩大了模型的自由度,易于紧密拟合训练数据。测试集上,3个颜色空间下svr的r2均大于rf,rmse均小于rf,表明svr算法的泛化能力优于rf,且rf算法有过拟合的情况。分析认为rf虽然在构建每棵树的分裂节点时引入了随机属性来避免过拟合,但是输入变量小于等于3的情况造成rf会生成一些差异度较小的树,从而降低了算法的泛化性能。svr是基于最小化结构风险的算法模型,可以得到全局最优解。
结合表2中评价指标的标准差可知,mlr模型在3个颜色空间下,测试集上r2和rmse浮动区间均包含训练集上的区间,可能出现测试集上评价指标优于训练集。分析认为,缺氮和过氮可能导致小麦生理状态异常,影响了小麦lnc测量的准确性,形成了噪声数据,而基于最小二乘的mlr算法模型对噪声数据比较敏感。svr模型在rgb空间下,测试集上的评价指标的浮动区间也包含训练集上的区间,说明svr也受到了噪声数据的干扰,反观rf在3个颜色空间下均没有受到噪声数据的影响,说明其有很好的抗噪能力,可能是rf自助法抽样建立决策树和从输入变量集合中随机抽取变量来分裂树的节点,这两个随机性的引入使得rf对噪声不敏感。
表2.主要颜色空间下叶片氮含量估算模型交叉验证结果
衡量模型泛化误差的两个方面分别是偏差与方差,偏差用于描述模型的拟合能力,方差用于描述稳定性。训练误差主要是由偏差造成的,而方差通常是由于模型的复杂度相对训练集过高导致,通常体现在测试误差相对训练误差的增量上。mlr测试误差相对训练误差的增量较小,而训练误差较大,造成测试误差相对训练误差的增量与训练误差的比值较小,3个颜色空间下分别为1.97%、0.88%、2.00%;svr和rf的测试误差相对训练误差的增量较大,而训练误差较小,致使两者的比值较大,分别为17.53%、28.52%、30.65%和47.11%、49.07%、47.24%。由此可知,mlr模型方差的比重小于模型的偏差,即mlr的拟合能力不足,泛化误差主要由偏差造成,而rf模型方差的比重接近于模型的偏差,考虑数据本身噪声也会造成偏差,可认为rf模型的方差主导了泛化误差。svr模型方差的比重小于模型的偏差,且两者的比值小于rf,但svr模型的测试集上的评价指标均优于rf,说明rf模型过拟合,svr模型的正则化常数c对模型的正则化效果优于rf的正则化超参数。
多颜色空间为rgb、hsv、l*a*b*这3种常用颜色空间的融合,其基础颜色分量为3种颜色空间下的9种基础分量。由表3可知,多颜色空间下,mlr、svr、rf训练集上的r2分别为0.7807、0.8813和0.9152,较hsv颜色空间下分别提高9.83%、0.46%和2.67%;rmse分别为0.4146、0.3027和0.2578,较hsv颜色空间下分别降低12.92%、2.35%和11.59%。分析认为,品种、光照强度、生育期以及施肥等因素的变化,作物的生长状况和营养状况也会随着改变,导致冠层图像指标对作物的营养状况表达能力的差异,多颜色空间的基础颜色分量包含的信息多于单一颜色空间。
rf测试集上r2为0.7930,高于hsv颜色空间下的0.7372;rmse为0.3899,低于hsv颜色空间下的0.4347。显然多颜色空间下,rf泛化性能得到提高,其原因可能是rf有多个输入属性值,生成了差异度较大的决策树,使得其泛化性能得到提高。svr在测试集上的r2略低于rf,且rmse高于rf,但测试误差相对训练误差的增量为0.092小于rf的0.1321,说明svr方差小于rf,即svr比rf要稳定。结合评价指标的方差可知,mlr测试集上r2和rmse浮动区间均包含训练集上的区间,可能出现测试集上评价指标优于训练集,说明mlr受到噪声数据的干扰。
表3.多颜色空间下叶片氮含量估算模型交叉验证结果
以上研究结果显示,在hsv颜色空间中,各算法模型的估算效果均优于另外两种颜色空间中的效果。融合了rgb、hsv和l*a*b*3种颜色空间的多颜色空间中,各算法模型估算效果优于hsv颜色空间中的效果。
在融合3个颜色空间的多颜色空间下,多元线性回归模型拟合能力不强,偏差主导了泛化误差;随机森林模型拟合能力最强,方差主导了泛化误差;支持向量回归模型正则化常数对模型正则化程度超过随机森林的超参数对模型自身的正则化程度,使得支持向量回归模型有着更好的泛化性能。所以,多颜色空间下的svr算法模型具有较高的预测精度,可对小麦lnc进行快速无损检测。
- 还没有人留言评论。精彩留言会获得点赞!