一种基于层次注意力神经网络模型的争议焦点自动识别方法与流程
本发明涉及一种基于层次注意力神经网络模型的争议焦点自动识别方法。
背景技术:
法律服务是一个传统的行业,但也是具有巨大潜能的行业。为提升法律服务的效率,改革传统的法律服务形式,利用人工智能技术辅助识别文书争议焦点,以帮助人们更快更好地判断和理解案件的争议焦点。
然而,一方面,为自动识别文书争议焦点,需要为各个领域建立争议焦点体系,但争议焦点体系的构建依赖于领域专家,构建过程费时费力,不利于大范围扩展;另一方面,在法律文书中,不同的词和句子含有不同程度的“信息量”,对判断争议焦点有不同的作用,在构建争议焦点自动识别模型时需关注不同的词和句子所起的作用。
鉴于此,我们一方面基于已有的文书来构建争议焦点体系,然后再提出基于层次注意力神经网络模型的争议焦点自动识别方法,来自动识别文书的争议焦点。
技术实现要素:
本发明的目的在于提供一种基于层次注意力神经网络模型的争议焦点自动识别方法,从而方便人们更快更好地判断和理解案件的争议焦点。
本发明解决其技术问题采用的技术方案如下:一种基于层次注意力神经网络模型的争议焦点自动识别方法,包括以下步骤:
1)争议焦点体系的构建:从含有法院归纳的争议焦点的文书中提取出法院对案件归纳得到的争议焦点语句。使用tf-idf算法从争议焦点语句中提取文本特征,将句子表示为向量形式,再使用层次聚类算法将所有的争议焦点语句进行聚类,得到争议焦点体系。
2)数据集构建:利用步骤1)中得到的争议焦点体系,判断该文书的争议焦点类别,并表达成一个二值向量,作为该文书的标签向量;每个文书文本拥有唯一的标签向量,将所有文书文本及其标签向量作为数据集用于训练层次自注意力神经网络模型;
3)构建层次自注意力神经网络模型:所述层次自注意力神经网络模型包括词编码层、词自注意力层、句编码层、句自注意力层、全连接层和softmax层;将文书文本进行分词、去停用词等预处理之后,作为词编码层的输入,词编码层通过word2vec模型以及双向门控循环单元对文书文本中每个词汇进行编码,得到每个词汇的词向量。将词向量输入到词自注意力层,采用自注意力机制得到不同词向量在句子中的权重,加权求和后得到句子的编码,即句向量。将句向量输入到句编码层,利用双向门控循环单元对句向量进行编码,将编码后的句向量输入到句自注意力层,使用自注意力机制得到不同句向量在文本中的权重,加权求和得到文本的向量形式表示。最后通过全连接层和softmax层得到该文书文本属于不同争议焦点类别的概率分布,再选取其中概率值大于0.1的争议焦点类别作为最终的预测结果。
4)识别争议焦点:利用步骤2)构建的数据集训练步骤3)所建的神经网络模型,得到文本分类器,将任一篇文书进行分词、去停用词等预处理后,作为输入传入文本分类器,文本分类器将输出识别出的该文书的争议焦点所属的类别。
进一步地,所述步骤1)具体为:
从选定领域中含有法院归纳的争议焦点的文书中提取出法院对案件归纳的争议焦点语句,然后对语句进行分词和去停用词处理。使用tf-idf算法,即用每个词的词频和逆文档频率的乘积作为该词在该句中的权重,将句子表示为向量形式,向量的每一个分量表示一个词在该句中的tf-idf权重;使用层次聚类算法将所有争议焦点语句进行聚类;句子之间的相似度利用向量空间的余弦相似度计算,簇与簇之间的相似度以两个簇中所有点的平均相似度计算。将簇与簇之间的相似度大于等于0.95的两个簇聚类,最终得到争议焦点的分类体系。
进一步地,所述步骤2)中将争议焦点所属类别表达成一个二值向量,即在该文书所属争议焦点类别的分量上为1,其它分量上为0,该二值向量作为该文书的标签向量;从而将文书争议焦点的自动识别问题转化成多标签多分类的文本分类问题。
进一步地,所述步骤3)具体为:
层次注意力网络模型的网络结构由五个部分组成,前四部分分别是词编码层、词自注意力层、句编码层、句自注意力层;通过该四部分可得到文书文本的向量表示,再通过一层全连接层和softmax层得到文本属于不同焦点类别的概率分布。具体步骤如下:
3.1)将文书的文本进行切词、去停用词等预处理之后作为词编码层的输入,词编码层是利用word2vec模型和双向门控循环单元对词进行编码。在双向门控循环单元中,有两个门,分别是更新门zt和重置门rt。更新门用于控制t-1时刻的状态信息被带入到t时刻状态中的程度,更新门的值越大说明t-1时刻的状态信息带入越多。重置门用于控制忽略t-1时刻的状态信息的程度,重置门的值越小说明忽略得越多。双向门控循环单元中的传播方式可以表示为:
zt=σ(wzxt+uzht-1+bz)
rt=σ(wrxt+urht-1+br)
其中,ht代表t时刻的状态向量,xt为t时刻的输入向量,每个时刻处理一个词,因此,xt为第t个词通过word2vec预训练得到的词向量。wz、wh、wr、uz、uh、ur、bz、bh和br是需要训练的参数,在层次自注意力神经网络模型训练过程中得到,σ表示激活函数,⊙表示矩阵对应位置元素相乘。将每一个词自左向右编码得到的状态向量
3.2)将编码后的词向量输入到词自注意力层,词自注意力层用于突出一句话中对于句意表达更加重要的词。其过程如下所示:
uit=tanh(wwhit+bw)
对于第i句话中的第t个单词,uit为隐藏层的第i句话中的第t个单词的向量,hit表示第i句话中的第t个词单词的词向量,αit为第i句话中的第t个单词在第i句话中的权重,t表示转置符号,uw为单词级别的上下文向量。上下文向量可以使一句话中的词与其他词语之间存在上下文关系,该向量在层次自注意力神经网络模型训练过程中得到;si表示第i句的句向量。
3.3)句编码层的原理与词编码层相同,利用步骤3.2)得到的句向量和双向门控循环单元对句子进行编码。公式如下:
3.4)将编码后的句向量输入到句自注意力层,用于提升对于文本语意而言更加重要的句子的权重,其原理与词的注意力层原理相同,公式如下:
ui=tanh(wshi+bs)
ui为隐藏层向量,hi表示编码后的句向量,βi为第i句话在文书文本中的权重,t表示转置符号,us为句子级的上下文向量。该上下文向量可以使得文档中的句子与其他句子之间存在上下文关系,该向量在层次自注意力神经网络模型训练过程中得到;v表示文书文本的向量表示。
3.5)得到文书文本表示向量之后,将文书文本向量输入到全连接层及softmax层,使用softmax算法得到文书属于不同争议焦点类别的概率分布,再选取其中概率值大于0.1的争议焦点类别作为最终的预测结果。
本发明方法与现有技术相比具有的有益效果:
1.本方法依靠聚类方法构建争议焦点体系,减少人工工作,更加系统、科学。
2.本方法的流程可以依靠机器学习自动完成,无需人工干预,减轻用户负担。
3.本方法在神经网络中引入分层结构和注意力机制,充分利用单词构成句子,句子构成文章的文本结构和不同单词、语句对于句子、文章的语义表达的重要程度不同的语言特点。
4.本方法预测准确率较高,能够准确识别、判断文书的争议焦点。
5.本方法具有良好的可扩展性,针对其它领域,只需收集其它领域的文书,构建相应的争议焦点体系,并将文书文本作为输入训练分类器,即可实现在其它领域自动识别文书的争议焦点。
附图说明
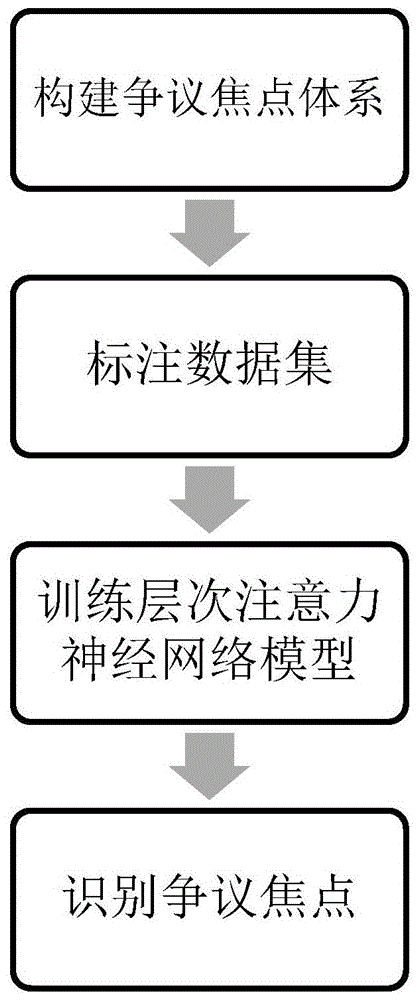
图1是本发明的总体流程图;
图2是本发明的神经网络模型结构;
图3是本发明在测试集上识别争议焦点的准确率;
图4是实施例中未标注争议焦点文书的部分截图。
具体实施方式
以下结合附图对本发明具体实施方式作进一步详细说明。
如图1所示,本发明提供一种基于层次注意力神经网络模型的争议焦点自动识别的方法。
包括以下步骤:
1)争议焦点体系的构建:从选定领域中含有法院归纳的争议焦点的文书中提取出法院对案件归纳的争议焦点语句,然后对语句进行分词和去停用词处理。使用tf-idf算法,即用每个词的词频和逆文档频率的乘积作为该词在该句中的权重,将句子表示为向量形式,向量的每一个分量表示一个词在该句中的tf-idf权重;使用层次聚类算法将所有争议焦点语句进行聚类;句子之间的相似度利用向量空间的余弦相似度计算,簇与簇之间的相似度以两个簇中所有点的平均相似度计算。将簇与簇之间的相似度大于等于0.95的两个簇聚类,最终得到争议焦点的分类体系。
2)数据集构建:利用步骤1)中得到的争议焦点体系,判断该文书的争议焦点类别,并表达成一个二值向量,即在该文书所属争议焦点类别的分量上为1,其它分量上为0,作为该文书的标签向量;每个文书文本拥有唯一的标签向量,从而将文书争议焦点的自动识别问题转化成多标签多分类的文本分类问题,将所有文书文本及其标签向量作为数据集用于训练层次自注意力神经网络模型;
3)构建层次自注意力神经网络模型:所述层次自注意力神经网络模型包括词编码层、词自注意力层、句编码层、句自注意力层、全连接层和softmax层;将文书文本进行分词、去停用词等预处理之后,作为词编码层的输入,词编码层通过word2vec模型以及双向门控循环单元对文书文本中每个词汇进行编码,得到每个词汇的词向量。将词向量输入到词自注意力层,采用自注意力机制得到不同词向量在句子中的权重,加权求和后得到句子的编码,即句向量。将句向量输入到句编码层,利用双向门控循环单元对句向量进行编码,将编码后的句向量输入到句自注意力层,使用自注意力机制得到不同句向量在文本中的权重,加权求和得到文本的向量形式表示。最后通过全连接层和softmax层得到该文书文本属于不同争议焦点类别的概率分布,再选取其中概率值大于0.1的争议焦点类别作为最终的预测结果。具体步骤如下:
3.1)将文书的文本进行切词、去停用词等预处理之后作为词编码层的输入,词编码层是利用word2vec模型和双向门控循环单元对词进行编码。在双向门控循环单元中,有两个门,分别是更新门zt和重置门rt。更新门用于控制t-1时刻的状态信息被带入到t时刻状态中的程度,更新门的值越大说明t-1时刻的状态信息带入越多。重置门用于控制忽略t-1时刻的状态信息的程度,重置门的值越小说明忽略得越多。双向门控循环单元中的传播方式可以表示为:
zt=σ(wzxt+uzht-1+bz)
rt=σ(wrxt+urht-1+br)
其中,ht代表t时刻的状态向量,xt为t时刻的输入向量,每个时刻处理一个词,因此,xt为第t个词通过word2vec预训练得到的词向量。wz、wh、wr、uz、uh、ur、bz、bh和br是需要训练的参数,在层次自注意力神经网络模型训练过程中得到,σ表示激活函数,⊙表示矩阵对应位置元素相乘。将每一个词自左向右编码得到的状态向量
3.2)将编码后的词向量输入到词自注意力层,词自注意力层用于突出一句话中对于句意表达更加重要的词。其过程如下所示:
uit=tanh(wwhit+bw)
对于第i句话中的第t个单词,uit为隐藏层的第i句话中的第t个单词的向量,hit表示第i句话中的第t个词单词的词向量,αit为第i句话中的第t个单词在第i句话中的权重,t表示转置符号,uw为单词级别的上下文向量。上下文向量可以使一句话中的词与其他词语之间存在上下文关系,该向量在层次自注意力神经网络模型训练过程中得到;si表示第i句的句向量。
3.3)句编码层的原理与词编码层相同,利用步骤3.2)得到的句向量和双向门控循环单元对句子进行编码。公式如下:
3.4)将编码后的句向量输入到句自注意力层,用于提升对于文本语意而言更加重要的句子的权重,其原理与词的注意力层原理相同,公式如下:
ui=tanh(wshi+bs)
ui为隐藏层向量,hi表示编码后的句向量,βi为第i句话在文书文本中的权重,t表示转置符号,us为句子级的上下文向量。该上下文向量可以使得文档中的句子与其他句子之间存在上下文关系,该向量在层次自注意力神经网络模型训练过程中得到;v表示文书文本的向量表示。
3.5)得到文书文本表示向量之后,将文书文本向量输入到全连接层及softmax层,使用softmax算法得到文书属于不同争议焦点类别的概率分布,再选取其中概率值大于0.1的争议焦点类别作为最终的预测结果。
4)识别争议焦点:利用步骤2)构建的数据集训练步骤3)所建的神经网络模型,得到文本分类器,将任一篇文书进行分词、去停用词等预处理后,作为输入传入文本分类器,文本分类器将输出识别出的该文书的争议焦点所属的类别。
实施例
下面结合本发明的方法详细说明本实施例实施的具体步骤,如下:
在本实施例中,将本发明的方法应用于商品房买卖纠纷领域的法院判决文书,自动识别文书中的争议焦点。
1)利用正则表达式对共约33.6万份裁判文书进行处理,从中抽取出法院对于案件争议焦点的总结和表述。其中,内容中含有对争议焦点的表述的文书越有1.5万份。从这1.5万份文书中,可以得到不重复的争议焦点表述语句共6418句。首先采用tf-idf算法对文本进行向量化。首先,对文本进行切词、去停用词等预处理,然后构建词袋空间。将所有的文档都读入到程序中,并按照上述过程为每句争议焦点切词并去除停用词。统计出所有文档的词的集合。对每一个文档,即争议焦点的语句,构建一个向量,向量的值是某个词语在本文档中出现的次数。最后用tf-idf算法,将单词出现次数的向量转化为权值向量。
将所有的文本进行向量化表示以后,采用自底向上的层次聚类方法对争议焦点进行聚类。聚类时,使用夹角余弦值来度量两个向量之间的距离,并使用两个簇中所有样本对的距离的平均值来作为两个簇之间的距离。设置阈值0.95,最后可得到类簇19个。结果如表1所示。
表1争议焦点体系
2)通过步骤1)的处理,筛选出含有有效争议焦点的法院文书共8303篇。接下来为这些文书进行标注。在标注的时候,逐句查看该文书的争议焦点语句,并判断焦点属于哪一个类别。以某篇文书为例,从该文书中能够抽取出两句争议焦点的句子,其中第一句“一、三被告是否存在逾期交楼”属于“逾期交房”的问题,第二句“违约金应如何计算”属于“违约金如何计付”的问题。因此,该篇文书的类别标签为“是否逾期交房”和“违约金如何计付”。为了用于训练,使用一个长度为19的向量来表示文书的类别,如果该文书包含某类争议焦点,则该分量为1,否则为0。因此,这篇文书的标注结果为向量(0,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0)。
3)按照图2所示结构搭建层次注意力神经网络模型,使用交叉熵函数作为损失函数训练模型。在本方法中,使用keras框架构建该网络模型,将所有标注的数据集以9:1的比例划分为训练集和验证集进行训练和验证。在对模型结果进行评估时,使用杰卡德距离作为评估标准。杰卡德距离定义为实际类别与预测类别的交集元素个数与并集元素个数之比,它可以较好地体现出两个向量之间的“重合度”,从而用来评估准确率。模型的准确率如附图3所示,其中,横轴为训练轮数,纵轴为以杰卡德距离为评估标准的准确率。
4)我们使用该模型对一篇没有法院归纳争议焦点的文书进行预测。该文书的部分内容如附图4所示。
将该部分文书输入到模型之后,模型预测给出的最有可能的三个争议焦点为:是否逾期交房,违约金如何计付,是否构成违约。结合图中划线语句,可以判断出模型给出的预测焦点结果比较正确。
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!