一种基于深度学习的安全帽佩戴检测系统及方法与流程
本发明涉及一种图像识别技术领域,尤其涉及一种基于深度学习的安全帽佩戴检测系统及方法。
背景技术:
在工地,车间,码头等地方,工人们需要佩戴安全帽以防止物品掉落导致工人受伤,但往往工人们会因为各种原因而未佩戴安全帽,为了提高生产安全性,保护工人的生命安全,需要具有一种有效的监控和管理方法来监督工人们佩戴安全帽。
现有技术中,通常采用以下方法对工人是否佩戴安全帽进行自动识别检测:
现有技术中存在的安全帽检测系统采用卷积神经网络直接对获取到的监控图片中的工人、安全帽和安全带进行检测,而后根据安全帽、安全带与人体之间的相互关系判断是否正确佩戴安全帽以及是否系好安全带。这种方法直接从图像中检测安全帽,由于安全帽较小,同时无丰富的纹理信息,安全帽检测的准确率较低。另外,监控设备一般向下俯拍,有些时候因为受到外部因素干扰,拍摄的人体头部并不明显,或者人体头部完全被安全帽遮挡,此时采用卷积神经网络通过计算人体头部和安全帽的重叠率,由此判断工人是否将安全帽佩戴到头部位置显然已无法实现。
技术实现要素:
为了解决以上技术问题,本发明提供了一种基于深度学习的安全帽佩戴检测系统,本检测系统综合人体目标检测方法和安全帽颜色信息检测方法,可对监控图像中的工人是否合规佩戴安全帽进行有效检测,可以有效降低监控图像中因存在人体遮挡时或人群中人与人之间存在虚检时对安全帽的漏检。
本发明所解决的技术问题可以采用以下技术方案实现:
一种基于深度学习的安全帽佩戴检测系统,包括:
一数据获取模块,用于于监控设备处获取监控图像;
一人体检测模块,连接所述数据获取模块,于所述人体检测模块中预设有一人体目标检测模型和一人体骨骼关键点检测模型,所述人体检测模块用于基于所述人体目标检测模型对所述监控图像进行人体目标检测,并得到一人体目标检测结果;
所述人体检测模块还用于基于所述人体骨骼关键点检测模型对所述人体目标检测结果中存在的人体图像进行人体骨骼关键点检测,并得到一人体骨骼关键点检测结果;
人体检测结果分析模块,连接所述人体检测模块,用于结合所述人体目标检测结果和所述人体骨骼关键点检测结果,经综合分析得到一人体检测结果;
图像分割模块,连接所述人体检测结果分析模块,用于将存在于所述人体检测结果中的各个人体图像分割为关联于各所述人体图像的多张人体区域图片并保存;
一安全帽检测模块,连接所述图像分割模块,用于根据预设的安全帽检测模型对每一张所述人体区域图片中是否存在安全帽进行识别检测,并得到一安全帽检测结果;
一预警模块,连接所述安全帽检测模块,用于根据所述安全帽检测结果进行相应的提示报警。
优选的,所述安全帽佩戴检测系统还包括一模型训练模块,分别连接所述人体检测模块和所述安全帽检测模块,用于训练形成所述人体目标检测模型、所述人体骨骼关键点检测模型和所述安全帽检测模型,并将所述目标检测模型和所述人体骨骼关键点检测模型更新于所述人体检测模块中,以及将所述安全帽检测模型更新于所述安全帽检测模块中。
优选的,所述安全帽检测模块中具体包括:
第一安全帽识别单元,用于基于所述安全帽检测模型对各所述人体区域图片进行安全帽检测,以识别各所述人体区域图片中是否存在疑似安全帽;
第二安全帽识别单元,连接所述第一安全帽识别单元,用于对所述人体区域图片中的所述疑似安全帽所在的区域进行进一步的图片颜色信息计算,得到一对应所述疑似安全帽所在区域图片的颜色信息计算结果;
安全帽检测结果形成单元,连接所述第一安全帽识别单元和所述第二安全帽识别单元,用于综合所述第一安全帽识别单元识别得到的所述疑似安全帽区域识别结果和所述第二安全帽识别单元识别得到的对应所述疑似安全帽区域的所述颜色信息计算结果得到对安全帽的最终检测结果作为所述安全帽检测结果并输出。
优选的,所述人体目标检测为对各个所述人体图像在所述监控图像中的坐标进行坐标位置检测,所述人体骨骼关键点检测为对各所述人体图像上的各个所述人体骨骼关键点位于对应的所述人体图像上的坐标进行坐标位置检测。
本发明提供了一种基于深度学习的安全帽佩戴检测方法,通过所述安全帽佩戴检测系统实现,包括如下步骤:
步骤s1,所述安全帽佩戴检测系统于所述监控设备处获取所述监控图像;
步骤s2,所述安全帽佩戴检测系统对所述监控图像进行人体目标检测,并得到所述人体目标检测结果;
步骤s3,所述安全帽佩戴检测系统对存在于所述人体目标检测结果中的各所述人体图像进行安全帽识别检测,以判断各所述人体图像中是否存在安全帽,并得到所述安全帽检测结果。
优选的,所述步骤s2中具体包括如下步骤:
步骤s21,所述安全帽佩戴检测系统基于预设的目标检测模型对所述监控图像进行人体目标检测,并得到所述人体目标检测结果;
步骤s22,所述安全帽佩戴检测系统基于预设的人体骨骼关键点检测模型,对所述人体目标检测结果中存在的各所述人体图像进行人体骨骼关键点检测,并得到所述人体骨骼关键点检测结果;
步骤s23,所述安全帽佩戴检测系统根据所述人体目标检测结果和所述人体骨骼关键点检测结果,经综合分析得到所述人体检测结果。
优选的,所述步骤s3中具体包括如下步骤:
步骤s31,所述安全帽佩戴检测系统将存在于所述人体检测结果中的各所述人体图像分割为关联于各所述人体图像的多张所述人体区域图片并保存;
步骤s32,所述安全帽佩戴检测系统基于所述安全帽检测模型对各所述人体区域图片进行安全帽检测,以识别各所述人体区域图片中是否存在疑似安全帽;
步骤s33,所述安全帽佩戴检测系统对所述人体区域图片中的所述疑似安全帽所在的区域进行进一步的图片颜色信息计算,得到一对应所述疑似安全帽区域的颜色信息计算结果;
步骤s34,所述安全帽佩戴检测系统结合步骤s32中得到的疑似安全帽区域识别结果和步骤s33中得到的对应疑似安全帽区域的颜色信息计算结果得到对安全帽的最终检测结果作为所述安全帽检测结果输出。
优选的,所述步骤s21中的所述安全帽佩戴检测系统对所述监控图像进行人体目标检测为对所述监控图像中存在的各所述人体图像在所述监控图像中的坐标进行坐标位置检测。
优选的,所述步骤s22中的所述安全帽佩戴检测系统对各所述人体图像进行人体骨骼关键点检测为对各个所述人体骨骼关键点位于对应的所述人体图像上的坐标进行坐标位置检测。
优选的,所述步骤s33中的所述安全帽佩戴检测系统对所述人体区域图片中的所述疑似安全帽区域进行所述图片颜色信息计算包括对所述疑似安全帽区域中的各像素点的对比度信息计算、和/或色度信息计算、和/或亮度信息计算。
其有益效果在于:
本方法先通过检测人体再进行安全帽检测,可以在安全帽较小时,可以先通过人体检测把安全帽区域一起提取出来,降低漏检;同时结合人体目标检测和人体骨骼关键点检测,可以降低人体被遮挡时对人体目标的漏检,降低多人重叠时的虚检,提高人体检测的准确率;以及利用目标检测网络检测安全帽,并结合安全帽区域的颜色信息以及安全帽的形状信息,提高安全帽检测的准确率。
附图说明
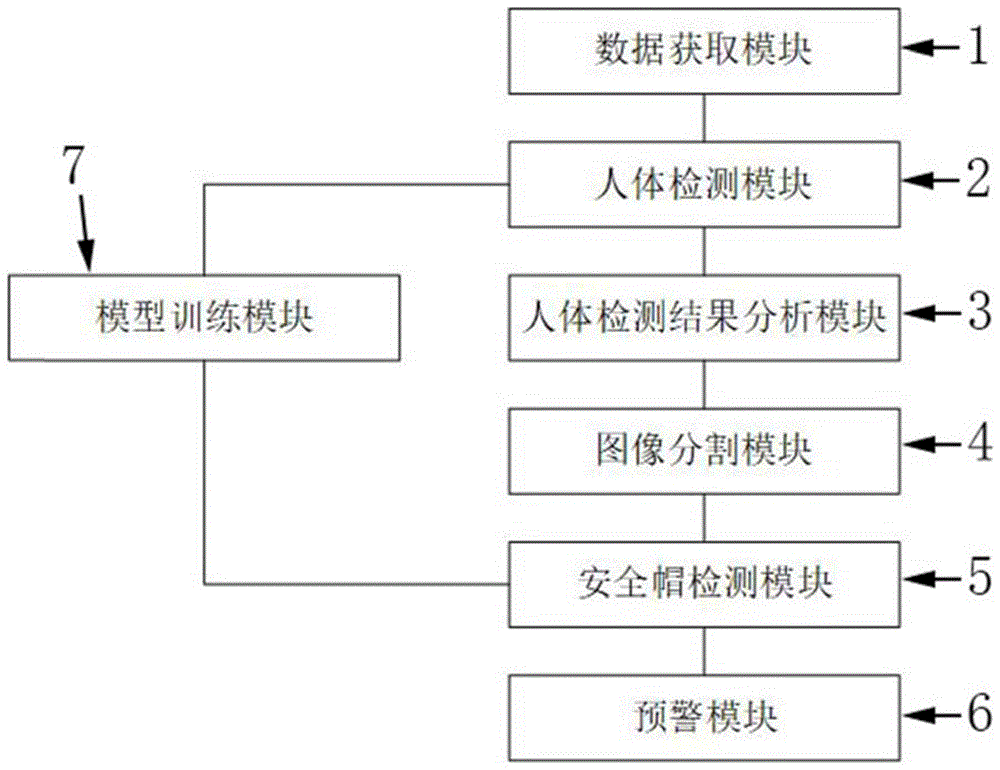
图1为本发明提供的一种基于深度学习的安全帽佩戴检测系统结构图;
图2为本发明提供的安全帽检测模块结构图;
图3为本发明提供的一种基于深度学习的安全帽佩戴检测方法步骤图;
图4为图3步骤s2的一种具体实施例子步骤图;
图5为图3步骤s3的一种具体实施例子步骤图;
图6为本发明提供的安全帽佩戴检测系统检测安全帽的整个流程框图;
图7为本发明提供的安全帽佩戴检测系统检测人体目标的流程框图;
图8为本发明提供的安全帽检测系统在检测完人体目标后对安全帽进行检测的检测框图;
图中:
1、数据获取模块,2、人体检测模块,3、人体检测结果分析模块,4、图像分割模块,5、安全帽检测模块,6、预警模块,7、模型训练模块,8、第一安全帽识别单元,9、第二安全帽识别单元,10、安全帽检测结果形成单元。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
请参照图1,本发明提供的一种基于深度学习的安全帽佩戴检测系统结构图;包括:
一数据获取模块1,用于于监控设备处获取监控图像;
一人体检测模块2,连接数据获取模块1,于人体检测模块2中预设有一人体目标检测模型和一人体骨骼关键点检测模型,人体检测模块2用于基于人体目标检测模型对监控图像进行人体目标检测,并得到一人体目标检测结果;
人体检测模块2还用于基于人体骨骼关键点检测模型对人体目标检测结果中存在的人体图像进行人体骨骼关键点检测,并得到一人体骨骼关键点检测结果;
人体检测结果分析模块3,连接人体检测模块2,用于结合人体目标检测结果和人体骨骼关键点检测结果,经综合分析得到一人体检测结果;
图像分割模块4,连接人体检测结果分析模块3,用于将存在于人体检测结果中的各个人体图片分割为关联于各人体图片的多张人体区域图片并保存;
一安全帽检测模块5,连接图像分割模块4,用于根据预设的安全帽检测模型对每一张人体区域图片中是否存在安全帽进行识别检测,并得到一安全帽检测结果;
一预警模块6,连接安全帽检测模块5,用于根据安全帽检测结果进行相应的提示报警。
上述技术方案中,需要说明的是,人体目标检测模型和人体骨骼关键点检测模型可以是事先训练好的模型,人体目标检测模型通过一深度卷积神经网络训练而得,该深度卷积神经网络采用的网络结构可以是现有的yolo神经网络架构,也可以是其他现有的ssd或faster-rcnn神经网络架构。人体骨骼关键点检测模型同样通过一深度卷积神经网络训练而得,该深度卷积神经网络采用的网络结构可以是现有的maskrcnn或fcn等神经网络架构。由于人体目标检测模型和人体骨骼关键点检测模型的训练过程采用的是现有的卷积神经网络结构,而且两个模型的训练过程也并非本发明要求专利保护的范围,所以两个模型的训练过程在此不作详细阐述。
另外需要说明的是,安全帽检测模型同样通过一深度卷积神经网络训练而得,该深度卷积神经网络的网络结构可以采用现有的faster-rcnn+mobilenet或tiny-yolo等轻量级网络结构。
优选情况下,本发明提供的安全帽佩戴检测系统还包括:
一模型训练模块7,分别连接人体检测模块2和安全帽检测模块5,用于训练形成人体目标检测模型、人体骨骼关键点检测模型和安全帽检测模型,并将目标检测模型和所述人体骨骼关键点检测模型更新于人体检测模块2中,以及将安全帽检测模型更新于安全帽检测模块5中。
这里需要强调的是,模型训练模块7的作用除了训练人体目标检测模型、人体骨骼关键点检测模型和安全帽检测模型外,其另外一个主要作用是将新训练形成的模型自动更新到对应的人体检测模块2或安全帽检测模块5中。举例而言,将安全帽检测结果中存在的存有安全帽图像信息的各人体区域图片输入到该模型训练模块7中,模型训练模块7根据预设的训练方法,比如应用tiny-yolo深度卷积神经网络最终训练形成新的安全帽检测模型,模型训练模块7在新的安全帽检测模型训练完成后将自动将该新训练而成的模型更新到安全帽检测模块5中。也就是说,安全帽检测模型、人体目标检测模型和人体骨骼关键点检测模型不是固定不变的,系统将自动对各个模型进行重新训练更新,以提高本系统的安全帽佩戴检测的准确率。
图2为本发明提供的安全帽检测模块结构图,请具体参照图2,安全帽检测模块5中具体包括:
第一安全帽识别单元8,用于基于安全帽检测模型对各人体区域图片进行安全帽检测,以识别各人体区域图片中是否存在疑似安全帽;
第二安全帽识别单元9,连接第一安全帽识别单元8,用于对人体区域图片中的疑似安全帽所在的区域进行进一步的图片颜色信息计算,得到一对应疑似安全帽所在区域图片的颜色信息计算结果;
安全帽检测结果形成单元10,连接第一安全帽识别单元8和第二安全帽识别单元9,用于综合第一安全帽识别单元8识别得到的疑似安全帽区域识别结果和第二安全帽识别单元9识别得到的对应疑似安全帽区域的颜色信息计算结果得到对安全帽的最终检测结果作为安全帽检测结果并输出。
这里需要说明的是,第二安全帽识别单元9计算的图片颜色信息包括关联于对应的人体区域图片的对比度信息、和/或色度信息、和/或亮度信息计算。由于安全帽的颜色通常为单一颜色,为全红色或全黄色或全蓝色,所以安全帽与人体的其他部位的颜色存在明显区别,本发明通过计算每一张人体区域图片对应的图片颜色信息,并将该图片颜色信息与预设的安全帽对应的标准图片颜色信息进行图片信息数据比对,能够容易的判断出人体区域图片中是否存在安全帽,并可初步确认该人体区域图片中是否存在安全帽。
但有些时候,若工人所穿的衣服颜色跟安全帽颜色完全相同,这种情况下,系统将很难通过判断人体区域图片的图片颜色信息进而判断人体区域图片中是否存在安全帽。为了解决这个问题,本发明另外提供了一种安全帽检测方法,也就是通过对每一张人体区域图片进行疑似安全帽形状检测,并通过将检测出来的疑似安全帽形状与一预设的安全帽标准形状图像进行图像数据比对,以最终确认该人体区域图片中是否存在安全帽。
系统最终根据对人体区域图片的图片颜色信息检测结果也就是上面所述的第一安全帽检测结果,以及根据对人体区域图片的安全帽形状检测结果也就是上面所述的第二安全帽检测结果,最终形成对人体区域图片的安全帽检测结果。
这里需要说明的是,最终的安全帽检测结果的形成过程可以包括以下几种方式:
一、系统根据图片颜色信息检测结果确认对应的人体区域图片中存在安全帽,并且系统根据安全帽形状检测结果确认对应的该人体区域图片中存在安全帽,则判定该人体区域图片中存在安全帽,否则判定该人体区域图片中不存在安全帽。
二、系统若根据图片颜色信息检测结果确认对应的人体区域图片中存在安全帽,但根据安全帽形状检测结果未发现该人体区域图片中存在安全帽,则系统判定该人体区域图片中不存在安全帽。
三、系统若根据图片颜色信息检测结果确认对应的人体区域图片中不存在安全帽,但根据安全帽形状检测结果确认该人体区域图片中存在安全帽,则系统同样判定该人体区域图片中不存在安全帽。
系统的上述安全帽检测方法能够确保对安全帽检测的准确率,尽可能避免误检测情况的发生。
另外需要说明的是,上述的人体目标检测为对监控图像中存在的人体图像在监控图像中的具体坐标进行坐标位置检测。人体图像坐标位置检测的方法为现有技术中常用的坐标定位方法,而且该坐标定位方法也并非是本发明要求权利保护的范围,所以系统对于人体图像坐标位置的定位方法在此不作阐述。
由于人体部位比如脑部、手足等的结构、形状均不相同,所以系统通过在检测到的人体图像上检测出各人体骨骼关键点,以实现在人体图像上最终检测出是否存在安全帽。具体而言,系统对于人体骨骼关键点的检测为对人体图像上的各人体骨骼关键点位于对应的人体图像上的坐标进行坐标位置检测。这里需要说明都是,系统对于人体骨骼关键点的坐标定位采用的方法为现有技术中存在的坐标定位方法,而且该坐标定位方法也并非是本发明要求权利保护的范围,所以系统对于人体骨骼关键点的坐标定位方法在此不作阐述。
本发明还提供了一种基于深度学习的安全帽佩戴检测方法,通过所述的安全帽佩戴检测系统实现,请参照图3,具体包括如下步骤:
步骤s1,安全帽佩戴检测系统于监控设备处获取监控图像;
步骤s2,安全帽佩戴检测系统对监控图像进行人体目标检测,并得到人体检测结果;
步骤s3,安全帽佩戴检测系统对存在于人体目标检测结果中的各人体图像进行安全帽识别检测,以判断各人体图像中是否存在安全帽,并得到一安全帽检测结果。
请参照图6所示的具体实施例流程图,首先监控设备先采集需要的人体图像,然后通过人体检测对人体图像使用目标检测网络和骨骼关键点检测网络进行人体以及骨骼关键点的检测,并综合检测结果对检测结果进行修正,得到精确的人体检测结果;之后将分割好的人体图像输入到安全帽检测流程,利用目标检测网络进行安全检测并对安全帽区域颜色信息进行计算,得到最终的安全帽检佩戴测结果,进而得到监控区域的安全帽佩戴检测结果。
请参照图4,步骤s2中具体包括如下步骤:
步骤s21,安全帽佩戴检测系统基于预设的人体目标检测模型对监控图像进行人体目标检测,并得到人体目标检测结果;
步骤s22,安全帽佩戴检测系统基于预设的人体骨骼关键点检测模型,对人体目标检测结果中存在的各人体图像进行人体骨骼关键点检测,并得到人体骨骼关键点检测结果;
步骤s23,安全帽佩戴检测系统根据人体目标检测结果和人体骨骼关键点检测结果,经综合分析得到人体检测结果。,
上述技术方案中,需要说明的是,安全帽佩戴检测系统基于人体目标检测结果和人体骨骼关键点检测结果,综合得到人体检测结果的方法如下:
请参照图7,当系统检测到监控图像中存在人体图像也就是存在人体目标后,系统将进一步对人体图像进行人体骨骼关键点检测。由于人体的主要部位比如头部、手足的形状外观都不同,所以系统可以根据预设的人体标准头部的形状、尺寸,以及手足等各个人体骨骼关键点对应的形状、尺寸,检测出人体图像中是否存在相应的人体骨骼。同时,由于头部、手足等人体关键部位在人体上的位置并不一样,所以系统可根据现有的坐标定位法,对检测到的人体骨骼关键点进行坐标定位,进而判断系统检测到的人体图像是否为真正的人体图像,以进一步提升人体图像检测的准确率。
请参照图5,步骤s3中还具体包括如下步骤:
步骤s31,安全帽佩戴检测系统将存在于人体检测结果中的各人体图像分割为关联于各人体图像的多张人体区域图片并保存;
步骤s32,安全帽佩戴检测系统基于安全帽检测模型对各人体区域图片进行安全帽检测,以识别各人体区域图片中是否存在疑似安全帽;
步骤s33,安全帽佩戴检测系统对人体区域图片中的疑似安全帽所在的区域进行进一步的图片颜色信息计算,得到一对应疑似安全帽区域的颜色信息计算结果;
步骤s34,安全帽佩戴检测系统结合步骤s32中得到的疑似安全帽区域识别结果和步骤s33中得到的对应疑似安全帽区域的颜色信息计算结果得到对安全帽的最终检测结果作为安全帽检测结果输出。
如上所述,优选情况下,步骤s21中的安全帽佩戴检测系统对监控图像进行人体目标检测的为对监控图像中存在的各人体图像在监控图像中的坐标进行坐标位置检测。该坐标位置检测方法为现有技术中存在的坐标定位方法,其具体定位过程在此不作阐述。
进一步地,步骤s22中的安全帽佩戴检测系统对各人体图像进行人体骨骼关键点检测为对各个人体骨骼关键点位于对应的人体图片上的坐标进行坐标位置检测。该坐标位置检测采用的检测方法同样为现有技术中存在的坐标定位方法,其具体定位过程在此不作阐述。
请参照图8,系统对单个人体区域图像进行疑似安全帽区域检测后,得到疑似安全帽区域检测结果及检测准确率得分,然后根据检测得分高低,进一步对疑似安全帽区域的图像颜色信息进行检测,最终得到安全帽检测结果。
这里需要说明的是,系统对每一单个人体区域图像上的疑似安全帽区域进行检测后得到的检测准确率得分是通过以下方法进行的:
系统根据预设的评价方法对疑似安全帽区域检测结果进行评分,比如当系统检测到存在人体区域图像中存在疑似安全帽区域的检测概率大于0.3,则判定该人体区域图像中疑似存在安全帽,否则判定该人体区域图像中不存在安全帽;然后系统进一步对疑似安全帽区域的图像颜色信息进行检测,最后结合检测概率和疑似安全帽区域的颜色信息综合判定该人体区域图像中的个人是否正确佩戴了安全帽。
进一步地,步骤s33中的安全帽佩戴检测系统对人体区域图片中的疑似安全帽区域进行图片颜色信息计算包括对疑似安全帽区域中的各像素点的对比度信息计算、和/或色度信息计算、和/或亮度信息计算。
综上,本发明通过先检测人体目标再进行安全帽检测,可以在安全帽较小时,可以先通过人体目标检测把安全帽区域一起提取出来,降低漏检;同时结合人体目标检测和骨骼关键点检测,可以降低人体被遮挡时的漏检,降低多人重叠时的虚检,提高人体目标检测的准确率;以及同时利用目标检测网络检测安全帽,并结合安全帽区域的图像颜色信息和安全帽形状信息对安全帽进行检测,提高了安全帽检测的准确率。
以上所述仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书及图示内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!