一种面向智能电表海量数据的多步聚合负荷预测方法与流程
本发明涉及电力系统负荷预测领域和大数据领域,特别涉及一种面向智能电表海量数据的多步聚合负荷预测方法。
背景技术:
随着智能电表大范围的部署,产生了海量的细粒度数据。这些数据包含了大量的用户用电行为信息,为提升聚合负荷预测精度提供了可能性。
但是当前获取的智能电表数据存在许多问题,难以直接利用。由于电表故障、通信故障、存储故障以及各种技术不成熟等情况常常带来数据异常、数据缺失、数据冗余等问题。因此,对数据进行有效的分析成为一个重要的课题。数据异常探测的方法包括时间序列分析、低秩矩阵和时间窗口等。缺失数据填充常使用插值法、固定值法,更进一步地,可以使用时间序列预测技术进行填充。
聚类技术属于一种无监督算法,其目的是根据某些特定的依据,把相似的数据归于一类。本发明涉及的聚类技术属于时间序列聚类。时间序列的相似性可以分为三种:时间相似性、形状相似性和变化相似性。时间相似性是指在两个序列相同的时间点的值是否接近;形状相似性是指两条曲线是否有相似的转折点;变化相似性是指两条曲线分别拟合一种时间序列分析技术时(如arma),是否具有相似的参数。根据本发明的特点,采用的是基于时间相似的判断标准。
分类技术包含大量的算法。当前常用的算法包括决策树、随机森林、梯度提升决策树、支持向量机等。最近几年,深度学习技术的发展提供了更多的优秀结构。例如,基于一维cnn的分类技术可以提取曲线的特征,多层的结构可以提取更加复杂和高级的特征,可以提供更加精确的分类结果。
电力负荷曲线预测在过去几十年被广泛研究,主要算法包括arima、svr、gbrt、lstm等等。
技术实现要素:
针对上述现有技术存在的不足,本发明提供一种面向智能电表海量数据的多步聚合负荷预测方法,其目的是为了通过利用海量数据和分多步处理,实现有效提升聚合负荷预测的精度的发明目的。
为了实现上述发明目的,本发明是通过以下技术方案来实现的:
一种面向智能电表海量数据的多步聚合负荷预测方法,包括以下步骤:
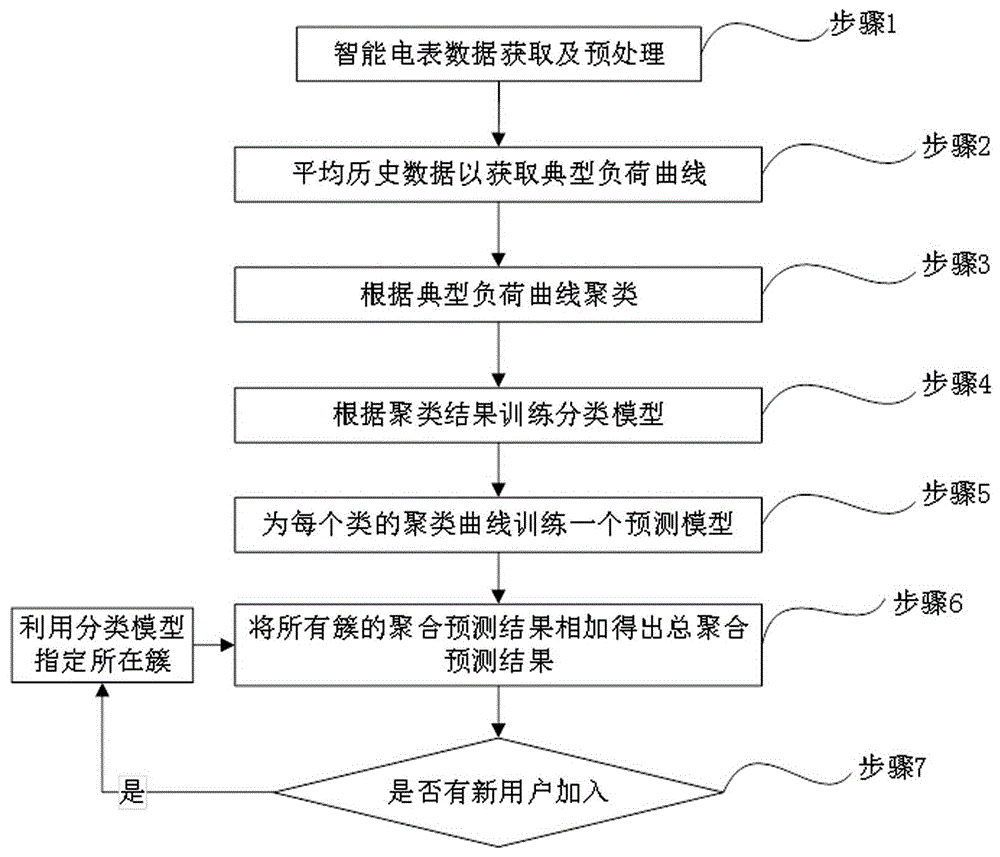
步骤1:智能电表数据获取及预处理;
步骤2:对每个用户的历史周数据进行平均,获取对应用户的典型负荷曲线;
步骤3:根据典型负荷曲线的相似性,对所有用户进行聚类;
步骤4:把聚类得到的簇号当作标签,把典型负荷曲线当作特征向量,训练一个分类模型;
步骤5:把一个簇中的用户负荷聚合,形成一个聚合曲线,为每一个聚合曲线训练一个预测模型;
步骤6:将所有簇的聚合负荷预测结果相加,得到总体的聚合负荷预测结果;
步骤7:新加入的用户采用步骤4训练的分类模型,分类到特定簇中,再重新计算此簇的聚合负荷预测值和总体的聚合负荷预测值。
所述步骤1智能电表数据获取及预处理,进一步包括:
步骤1.1:获取智能电表数据,包括但不限于电能值、电能量值、有功功率以及功率因数;
步骤1.2:对数据进行预处理,包括但不限于:坏数据探测、异常值替换、缺失值补充、冗余数据剔除以及非数值数据编码;
步骤1.3:格式化数据形成可用向量序列。
所述步骤3根据典型负荷曲线的相似性,对所有用户进行聚类,进一步包括:
步骤3.1:聚类算法按照特征曲线的同时间相似性进行聚类;
步骤3.2:曲线间和簇间的聚类度量方式为欧几里德距离;
步骤3.3:尝试多个不同的簇数,最后选择dbi指数最低的簇数。
所述步骤4把聚类得到的簇号当作标签,把典型负荷曲线当作特征向量,训练一个分类模型;进一步包括:分类的依据是典型负荷曲线,其中每个时刻的值被当作一个特征;分类的数量与簇的数量相等,簇号即是分类的类号。
所述步骤5把一个簇中的用户负荷聚合,形成一个聚合曲线,为每一个聚合曲线训练一个预测模型;进一步包括:每个簇中所有用户的负荷被加起来,形成一个聚合负荷;预测模型的输入即是被预测时刻之前的历史聚合曲线。
所述步骤3.3:尝试多个不同的簇数,最后选择dbi指数最低的簇数,包括:
计算多次聚类的结果的dbi指数,dbi指数定义如下:
其中:c表示簇,c是簇的质心,n是簇的数量,i和j表示任意一个簇的编号,d表示簇间聚类,
所述分类的依据是典型负荷曲线,其中每个时刻的值被当作一个特征;分类的数量与簇的数量相等,簇号即是分类的类号,具体包括:
把聚类得到的簇标记从1到64的数字,再转化为独热向量;使用一维cnn进行分类;输入的长度即用户的典型负荷曲线的长度。
本发明由于采用以上技术方案,具有以下优点效果
本发明通过聚类类似用户,使得一类用户可以被专用的预测模型预测,这相当于提升了预测阶段的专业性。通过分类算法,使得新加入的用户可被直接分如某一类,防止反复执行海量数据的聚类操作,大大节省了运行时间,提升了本发明实际操作的可能性。
附图说明
为了更清楚地说明本发明实施例的技术方案,下文中将对本发明实施例的附图进行简单介绍。其中,附图仅仅用于展示本发明的一些实施例,而非将本发明的全部实施例限制于此。
图1为本发明实施方式一种面向智能电表海量数据的多步聚合负荷预测方法。
具体实施方式
下面结合附图对本发明实施方式结合实例作进一步详细的说明。但是应当指出,本发明的实施方式及实施案例是为了解释目的的优选方案,并不是对本发明的限制。
本实施方式中采用的一种面向智能电表海量数据的多步聚合负荷预测方法,如图1所示。图1为本发明实施方式一种面向智能电表海量数据的多步聚合负荷预测方法,具体步骤如下:
步骤1:智能电表数据获取及预处理;
步骤1.1:采用某省电网智能电表数据,共计50万个用户。包括但不限于电能值、电能量值、有功功率以及功率因数;
步骤1.2:采用30分钟负荷数据,对冗余数据进行剔除、填补缺失数据,将个别严重缺失的用户剔除出数据集。包括但不限于:坏数据探测、异常值替换、缺失值补充、冗余数据剔除以及非数值数据编码;
步骤1.3:格式化数据形成可用向量序列。
步骤2:对每个用户的历史周数据进行平均,获取对应用户的典型负荷曲线。
步骤3:根据典型负荷曲线的相似性,对所有用户进行聚类;
步骤3.1:采用k-means算法按照特征曲线的同时间相似性进行聚类;
这里采用k-means算法进行聚类,k-means算法指聚类算法;首先需要确定聚类的簇数。我们选择2n个簇,作为簇数的待选集,并选择一个合适的上限,如1024,即{2,4,8,…,1024}。
步骤3.2:曲线间和簇间的聚类度量方式为欧几里德距离;
以负荷曲线间的欧几里德距离作为相似性的度量标准,分别在不同的簇数的情况下运行k-means算法,得倒多个聚类结果。
步骤3.3:尝试多个不同的簇数,最后选择dbi指数最低的簇数;dbi为聚类算法评价指标;
计算多次聚类的结果的dbi指数,dbi指数定义如下:
其中:c表示簇,c是簇的质心,n是簇的数量,i和j表示任意一个簇的编号,d表示簇间聚类,
步骤4:把聚类得到的簇号当作标签,把典型负荷曲线当作特征向量,训练一个分类模型;分类的依据是典型负荷曲线,其中每个时刻的值被当作一个特征;分类的数量与簇的数量相等,簇号即是分类的类号。
我们把聚类得到的簇标记从1到64的数字,再转化为独热向量。接着使用一维cnn进行分类。输入的长度即用户的典型负荷曲线的长度。本案例中,由于数据30分钟采集一次,所以输入长度为一周336个点。
接下来,我们使用梯度提升决策树对数据进行分类训练,树的数量为500,采用逻辑回归损失函数,学习率为0.1,二次抽样率0.9,最小分裂样本数为1000,最小叶子节点为500。
步骤5:把一个簇中的用户负荷聚合,形成一个聚合曲线,为每一个聚合曲线训练一个预测模型。每个簇中所有用户的负荷被加起来,形成一个聚合负荷;预测模型的输入即是被预测时刻之前的历史聚合曲线。
步骤6:将所有簇的聚合负荷预测结果相加,得到总体的聚合负荷预测结果;
步骤7:新加入的用户采用步骤4训练的分类模型,分类到特定簇中,再重新计算此簇的聚合负荷预测值和总体的聚合负荷预测值。
所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本公开的范围,包括权利要求,被限于这些例子;在本发明的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,步骤可以以任意顺序实现,并存在如上所述的本发明的不同方面的许多其它变化,为了简明它们没有在细节中提供。
本发明的实施例旨在涵盖落入所附权利要求的宽泛范围之内的所有这样的替换、修改和变型。因此,凡在本发明的精神和原则之内,所做的任何省略、修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!