一种用于视频分析中的动作识别方法与流程
本发明涉及视频分析技术领域,尤其是一种用于视频分析中的动作识别方法。
背景技术:
随着多媒体时代的到来,共享视频变得更加普遍,网络上视频的传播与获取变得越来越便捷,使得视频数据的数量急剧上升。针对数量巨大的视频数据,如何分析和利用这些数据的内容成为计算机视觉领域内的一个具有重要意义和研究价值的难题。视频分析人体动作的目标是获取视频中的图像序列,训练学习并且分析理解其中人的行为动作的含义。因此动作识别在信息获取、视频监控、人机交互等各个领域有着广泛的应用价值。
由于卷积神经网络在计算机视觉领域内的图像应用上得到了很好的成果,由此,研究学者们将其应用于视频分析来进行动作识别中的特征提取。单是获取视频图像中的空间、纹理、背景等静态信息对于复杂的识别任务是不够的,所以需要捕捉更多的动态信息,光流能够对视频中的时间信息有效地提取,被广泛地应用于视频分析任务中。
视频分析动作识别的重要研究内容之一是如何充分利用视频中的图像信息以及运动信息,同时这也是研究过程中亟需解决的难题。动作识别的主要目标是通过学习视频图像中人物的运动模式,将其与动作类别之间建立对应关系,从而实现理解人物的动作。因此首先需要解决如何充分提取融合视频中的图像和运动特征信息这一难点,才能够以此为基础进行后续的学习训练和分类识别。由此本发明增加了卷积融合层将提取到的时空特征融合并进行3d池化,同时不截断时间流,将训练后得到的融合时空流以及时间流再次融合,从像素水平对空间信息和时间信息建立起对应关系,从而实现更有效的特征融合。
技术实现要素:
本发明所要解决的技术问题在于,提供一种用于视频分析中的动作识别方法,能够在有限的时间规模内,尽量多的获取视频中的信息,从而增加网络的鲁棒性以及提高识别的准确率。
为解决上述技术问题,本发明提供一种用于视频分析中的动作识别方法,包括如下步骤:
(1)获取动作视频,将其处理成静止视频帧,计算叠加光流图;
(2)采用步骤(1)中获得的静止图像帧数据以及光流图作为输入分别进行训练,学习特征;
(3)对于步骤(2)中卷积层的时空特征进行卷积计算进行融合,并且进行3d池化。同时光流网络不截断,进行3d池化后继续提取特征;
(4)将步骤(3)中得到的融合特征与光流特征进行平均计算融合;
(5)根据损失函数对网络迭代训练,直至模型结果收敛。
优选的,步骤(1)中,计算叠加光流图具体包括如下步骤:
(11)首先计算光流图的光流矢量;对于连续帧t和t+1,它们之间的一组位移矢量场表示为dt,在第t帧的像素点(u,v)处的位移矢量使用dt(u,v)表示,它表示该像素点从第t帧移动到第t+1帧的对应像素点的位移矢量;
(12)将长度为l的连续帧矢量场的水平分量
其中,u=[1,w],v=[1,h],k=[1,l],w和h为视频的宽度和高度,对于任意像素点(u,v),叠加光流矢量表示为iτ(u,v,c),c=[1,2l]是对长度为l的帧序列中该像素点运动信息的编码。
优选的,步骤(3)中,对于步骤(2)中卷积层的时空特征进行卷积计算进行融合,并且进行3d池化,同时光流网络不截断,进行3d池化后继续提取特征具体包括如下步骤:
在时间t融合两个网络中的特征图
(31)首先在通道d上的相同空间位置i,j堆叠两个特征图:
(32)对于步骤(31)中得到的堆叠后的特征图ycat=fcat(xa,xb),将其与过滤器
yconv=ycat*f+b,
其输出结果的通道数为d,过滤器的维度是1×1×2d,其中1≤i≤h,1≤j≤w,1≤d≤d,同时,xa,xb,
(33)对于步骤(31)中得到的融合后的时空特征图进行3d池化,将时间t=1...t上的时空特征图叠加起来,得到输入
(34)对于卷积融合前的光流特征进行3d池化,同步骤(33),将2d池化扩展到时间域。
本发明的有益效果为:本发明将视频中的图像特征与运动特征结合起来用于识别,采用光流图提取的运动信息对于视频图像的rgb通道的缩放、更改有着不变性,能够更好地提取视频中运动物体的边缘以及中间区域的运动信息,避免网络仅被图像信息主导;卷积融合加3d池化的方式能够根据空间和时间特征的对应关系,从像素级别融合时空信息,在有限的时间规模内,尽量多地获取视频中的信息,从而增加网络的鲁棒性以及提高识别的准确率。
附图说明
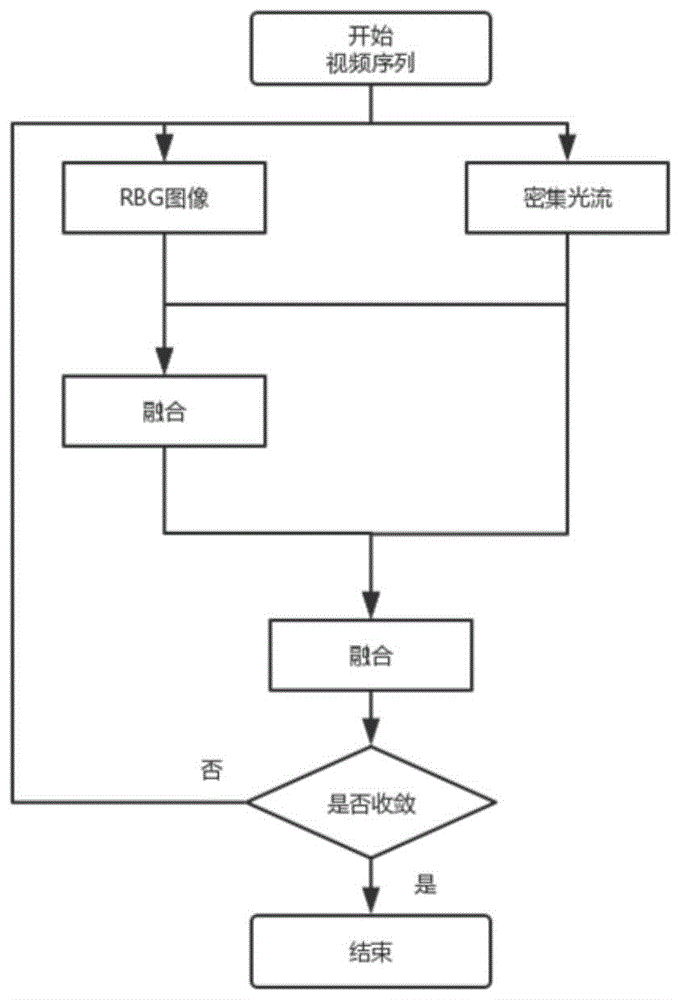
图1为本发明的方法流程示意图。
图2为本发明的网络结构示意图。
具体实施方式
如图1所示,一种用于视频分析中的动作识别方法,包括如下步骤:
步骤1:获取动作视频,将其处理成静止视频帧,计算叠加光流图。计算叠加光流图具体包括以下步骤:
步骤101:首先计算光流图的光流矢量。对于连续帧t和t+1,它们之间的一组位移矢量场表示为dt。在第t帧的像素点(u,v)处的位移矢量使用dt(v,v)表示,它表示该像素点从第t帧移动到第t+1帧的对应像素点的位移矢量。
步骤102:将长度为l的连续帧矢量场的水平分量
其中,u=[1,w],v=[1,h],k=[1,l],w和h为视频的宽度和高度。对于任意像素点(u,v),叠加光流矢量iτ(u,v,c),c=[1,2l]是对长度为l的帧序列中该像素点运动信息的编码。
步骤2:采用步骤1中获得的静止图像帧数据以及光流图作为输入分别提取特征。特征提取包括三层卷积和池化交替,紧接着三层卷积层以及relu激活函数。
步骤3:对于步骤2中卷积层的时空特征进行卷积计算进行融合。同时光流网络不截断,进行3d池化后继续提取特征。具体包括以下步骤:
在时间t融合两个网络中的特征图
步骤301:首先在通道d上的相同空间位置i,j堆叠两个特征图:
步骤302:对于步骤201中得到的堆叠后的特征图ycat=fcat(xa,xb),将其与过滤器
步骤303:对于步骤301中得到的融合后的时空特征图进行3d池化。将时间t=1...t上的时空特征图叠加起来,得到输入
步骤304:对于卷积融合前的光流特征进行3d池化,同步骤303,将2d池化扩展到时间域。
步骤4:将步骤3中得到的融合特征与光流特征进行平均计算融合。
步骤5:根据损失函数对网络迭代训练,直至模型结果收敛。
损失函数采用交叉熵损失函数:e(a,y)=-∑jajlogyj,其中aj表示目标标签值,yj表示输出值。
网络融合能够更加充分地利用时空信息,简单的平均、相加或是最大融合对时序信息并不敏感,这说明融合过程中没有获得很多的时序信息。而卷积融合加3d池化的方式能够根据空间和时间特征的对应关系,从像素级别融合时空信息,在有限的时间规模内,尽量多地获取视频中的信息,避免网络仅被图像信息主导,从而增加网络的鲁棒性以及提高识别的准确率。同时不因为时空特征的融合而截断光流网络的特征,3d池化并用于最后的分类融合,能够将2d扩展到3d池,在长时间间隔内捕捉到同一物体的特征,进一步提高识别的准确率。
- 还没有人留言评论。精彩留言会获得点赞!