针对卷积神经网络输入层的位解释的制作方法
以下内容总地涉及卷积神经网络,并且更具体地涉及卷积神经网络的第一层的二进制化(binarization)。
背景技术:
卷积神经网络(cnn)是一类深度前馈人工神经网络,其最通常被应用于包括计算机视觉和语音识别在内的许多不同应用。先前的cnn模型典型地需要高能量消耗、存储器存储和芯片面积来执行。因此,需要存在如下cnn:该cnn不需要那么多的芯片面积和存储器,并且在执行时不需要大量能量。
技术实现要素:
在一个实施例中,公开了一种用于实现接收输入数据的卷积神经网络(cnn)的系统和方法。然后,cnn可以在不提供预定义的序数结构的情况下,通过应用学习位特定相关性的按位加权算法来对输入数据进行过滤,以生成直接二进制输入数据(dbid)。所应用的按位加权算法可以是每个单独的输入值与被应用于该输入值的每一位的位特定权重相乘的所得总和。然后dbid可以被提供给cnn内的一个或多个卷积层。
dbid也可以被提供给卷积层,而不对输入数据执行附加的归一化。在一方面,cnn可以进一步包括一个或多个全连接层和柔性最大(softmax)层。在另一方面,cnn还可以包括具有一个或多个卷积核(k)滤波器的二进制输入层,该滤波器具有至少为1×1阵列的滤波器大小。
附图说明
图1是具有浮点或定点整数输入层的卷积神经网络的图;
图2是3通道彩色图像数据集的图示;
图3是具有直接二进制输入层的卷积神经网络的图;
图4是具有二进制输入层的卷积神经网络的图;以及
图5是直接二进制输入数据方法的图形图示。
具体实施方式
根据需要,在本文中公开了详细的实施例;然而,要理解的是,所公开的实施例仅仅是示例性的,并且可以以各种和替代的形式来体现。各图不一定是按比例的;一些特征可能被夸大或最小化以示出特定组件的细节。因此,本文中所公开的具体结构和功能细节将不解释为限制性的,而是仅仅作为用于教导本领域技术人员以各种方式采用本实施例的代表性基础。
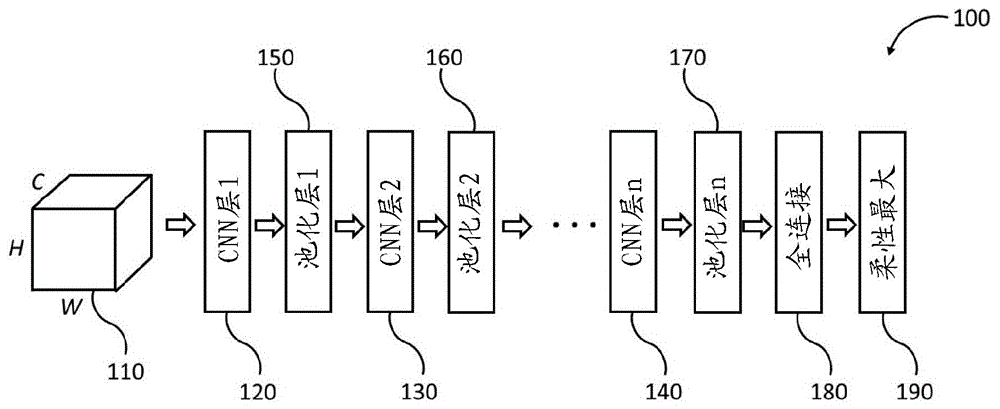
在神经网络领域中,对于包括计算机视觉(例如,对象识别或面部识别)和语音识别在内的各种各样的应用,已经增加了对深度卷积神经网络(cnn)的使用。参考图1,cnn100可以包括:输入数据110;一个或多个卷积层120-140;一个或多个池化层(poolinglayer)150-170;全连接层160;以及柔性最大层170。
输入数据110可以是原始图像数据、声音数据或文本数据。输入数据110还可以包括从传感器读数接收到的测量结果。替代地,可以在将输入数据110提供给cnn100之前对其进行轻度处理。卷积层120-140然后从输入数据110中提取特征。卷积层120-140一般在将结果传递到cnn100的下一层之前应用过滤操作(例如,核)。例如,图2图示了彩色图像200,其可以是卷积层120接收到的输入数据110。如所示出的,彩色图像200可以包括6×6的红色值阵列210、6×6的绿色值阵列220和6×6的蓝色值阵列230。由于cnn输入数据典型地被定义为高度×宽度×通道,因此彩色图像200可以被定义为6×6×3阵列。对于如彩色图像200这样的数据,卷积层可以执行过滤例程以执行诸如图像标识、图像边缘检测和图像锐化之类的操作。
cnn还可以包括一个或多个池化层150-170,该池化层150-170从相应的卷积层120-140接收卷积数据。池化层150-170可以包括一个或多个池化层单元,该池化层单元使用池化函数将池化函数应用于在不同带(band)处计算的一个或多个卷积层输出。例如,池化层150可以将池化函数应用于从卷积层120接收到的核输出。由池化层150-170实现的池化函数可以是平均值或最大值函数,或是将多个值聚合成单个值的任何其他函数。
接下来,全连接层180可以尝试学习针对从卷积层120-140和池化层150-170接收到的输出数据中的高级特征的非线性组合。最后,cnn100可以包括柔性最大层190,该柔性最大层190使用柔性最大函数来对全连接层180的输出进行组合。
如cnn100这样的模型典型地需要高的能量消耗、存储器存储和芯片面积。如果要在如现场可编程门区域(fpga)或专用集成电路(asic)这样的处理器上实现cnn100,这种缺点一般将属实。典型地,cnn100将需要具有大量存储器的耗电的微控制器或图形处理单元来存储必要的参数。实际上,对于大多数应用而言,在fpga或asic上执行所需的表面积的量将太大。因此,在具有较少处理功率和存储器的低功率边缘设备(例如,智能手表或iphone)上执行具有多个层和大量卷积滤波器的大版本cnn100一般是不可行的。实现cnn100模型的全部潜力可能无法被实现。
cnn100的高能量消耗和存储器使用可以可归因于以下事实:输入数据110的值由具有所定义量的位分辨率(即精度)的定点整数构成。输入数据110的值还可以使用以下等式(1)被表示为具有m位分辨率的定点整数:
其中,
x是单独的输入值;
m是每个输入值的位分辨率;并且
m是x的第m位值。
对于cnn100,位分辨率取决于应用可能在大小方面有所不同。例如,对于图像数据,位分辨率可以高达8位(即,m=8位),对于内部和环境传感器数据,位分辨率可以高达16位,并且对于音频数据,位分辨率可以高达24位。但是要理解的是,位分辨率可以小于8位或大于24位。输入数据一旦被归一化就将已经从m位定点整数值转换为浮点数。
为了处理包括定点整数或浮点值的输入数据,已经开发了一种系统,该系统包括在深度方面(depth-wise)可分离的卷积,该卷积减少了cnn100的前几层中的计算。处理输入数据的另一种方法涉及使用网络参数的低位宽度量化来简化cnn100,以在可穿戴设备(例如,智能手表)或其他边缘设备上实现推断(inference)。
例如,在应用某种裁剪(clipping)之前,可以将浮点输入与浮点权重相乘,使得值可以用二进制格式来表示并且由cnn100处理。对输入数据使用二进制化权重和激活已经导致关于图像分类基准数据集(如cifar-10或svhn)的较低功率消耗、芯片面积使用和存储器使用。使用图像分类数据库(如imagenet)评估的二进制权重cnn网络也已经示出了较低的功率消耗和存储器使用,而同时实现与全精度cnn网络相当的准确度。
可以通过下面的等式(2)来实现用于在第一层处对乘法进行二进制化的另一种方法:
其中,
s是所得总和;
x是单独的输入值;
m是每个输入值的位分辨率;
m是x的第m位值;并且
wb是应用于输入值的二进制权重。
上面的方法消除了归一化步骤,并且乘法可以使用m位定点整数来执行。然而,这种定点输入数据(fpid)方法也可能呈现缺陷。首先,输入值
一般而言,通过在第一层(以及可能地最后一层)处对输入数据进行二进制化,可以实现在cnn的能量使用和芯片面积使用方面的更大减少,这是因为在cnn的第一层内所需的参数数量和所执行的计算在与残差网络相比时可能相对低。例如,输入数据典型地具有比残差网络(例如,具有512个滤波器的cnn层)内相同数据的表示少得多的通道(例如,彩色图像200仅包括3个通道:红色、绿色和蓝色)。
对第一数据的二进制化的一个限制可能是:可能需要具有不同位宽度的两个不同的乘法器类型来执行计算。其中完全二进制化的系统可能有利于进一步最小化能量消耗和成本的应用(例如,可穿戴设备,诸如applewatch或fitbit)可能会超出这种限制。在一个这种方法中,设想到使用针对权重、激活和梯度的1位、2位和4位分辨率对完整网络(包括第一层)的二进制化。在这种方法下,由于具有m位精度的非二进制输入数据与二进制权重相乘,因此在第一层处执行的计算可以不由二进制乘法器来执行。
因此,设想到一种系统和方法,其中可以用二进制格式来执行整个cnn网络,从而允许在输入层处对所有乘法进行高效的二进制计算。通过使用位特定的二进制权重,cnn模型可以学习输入数据的哪些位是相关的,并且哪些是不相关的。这可以通过将每个位与其自己的1位权重相乘来完成。设想到的是,可以在训练阶段期间使用针对特定或给定用例的经标记的数据集来训练这些位特定的二进制权重。例如,可以使用已知的图像分类数据集(例如,svhn和cifar-10)或已知的基于可穿戴的人类活动识别数据集(例如,pamap2)来训练位特定的二进制权重。
例如,可以使用直接二进制输入数据(dbid)系统和方法来执行cnn网络,在所述直接二进制输入数据系统和方法中,输入数据是二进制的并且不需要对输入数据进行进一步的归一化(例如,将所有输入数据(x)缩放到[0,1]内的范围)。cnn模型可以包括归一化,其中将增益和偏移添加到输入数据,使得可以使用输入分辨率的整体范围。本方法和系统不需要作为整体地评估数。取而代之,本方法和系统能够评估输入数据的单独的位。由此,可以通过本方法和系统来应用归一化。例如,如果输入信号未达到输入分辨率动态范围的50%,则最高位将永远不会改变值,从而使得很可能在训练阶段之后该位的权重为“0”。可以基于以下等式(3)来执行dbid方法:
其中,
s是所得总和;
x是单独的输入值;
m是每个输入值的位分辨率;
m是x的第m位值;并且
图3图示了使用一个或多个实施例的dbid系统和方法执行的cnn300。如所示出的,输入数据310现在以二进制格式被定义为h×w×(c×m)。输入数据310与输入数据110之间的差异是添加的维度“m”。输入数据310的每个通道不再包括附加的“m”维度数据,所述“m”维度数据在分辨率方面可以是1位。
图5图示了基于等式(3)对以二进制格式的输入数据310进行过滤的示例。如所示出的,可以将8位整数值510表示为位值
这与被定义为归一化的浮点值或具有m位分辨率的定点整数值的输入数据110形成对照。尽管现在已经以二进制格式定义了输入数据310,但cnn300的其余部分如cnn100那样构造。例如,cnn300包括一个或多个卷积层320-340和池化层350-370。cnn300还包括至少一个全连接层380和柔性最大层390。还设想到的是,cnn300可以代替地是递归神经元网络(rnn)。设想到的是,rnn可以具有取代于至少一个全连接层380、或者在一个或多个卷积层320-340之间的一个或多个递归神经元网络层。
图4图示了替代的cnn400,其中在二进制输入数据410之后包括附加的二进制输入层424(bil)。bil424是可以在cnn400的二进制输入数据410与第一卷积层414之间添加的附加卷积滤波器层。bil424的卷积核滤波器可以被定义为至少为1×1阵列的滤波器大小。bil424允许在深度方面和点方面(point-wise)的卷积中分解(factorize)卷积。然后,可以将来自bil424的输出数据412(被表示为具有维度w×h×k的数据容器)提供给一个或多个附加卷积层414-418和池化层426-430。cnn400还包括至少一个全连接层420和柔性最大层422。
以下表1是已知的cnn方法(例如,基线和定点)、dbid方法和bil方法之间的比较。
基线和定点整数模型(fpid)代表上面使用图1所图示和描述的cnn100。dbid模型代表上面使用图2所图示和描述的cnn300。最后,bil模型代表上面使用图3所图示和描述的cnn400。对于数据集,将输入数据定义为具有形状高度×宽度×通道以及m位的精度。对于数据集,第一卷积层可以包括被定义为具有大小f×f的一个或多个卷积核滤波器。bil模型进一步包括具有1×1的滤波器大小的一个或多个卷积核滤波器。
在使用已知学习数据集(例如pamp2)的评估期间,bil模型展示出从基线模型为98.14%的相对芯片面积使用和能量使用减少,在基线模型中,输入数据和权重类型两者都被定义为浮点值。在使用已知学习数据集(例如pamp2)的进一步评估期间,dbid模型展示出从基线模型为99.79%的相对芯片面积使用和能量使用减少。
还可以使用图像分类数据集(svhn和cifar-10)和基于可穿戴的人类活动识别数据集(pamap2)来评估基线、fpid、dbid和bil模型。例如,以下表2提供了各种cnn方法的示例性结果集合。示例性结果包括当在第一层处为全精度数据和权重时网络的验证误差(%)。而且,以下表2说明了针对bil方法来修改卷积滤波器的数量。然而,设想到的是,结果可能与以下图表不同。
上面的结果基于示例性实验,在所述示例性实验中,pamap2数据集被设计成使用腕部传感器(例如,3d加速度计和陀螺仪)和心率监测器(总共7维)的数据来模拟智能手表的行为。实验输入是1秒长时间窗口(以fs=100hz的采样率而结果得到100个值),其具有可以是[7×100×1]的输入维度。对于pamap2示例,网络被定义为:24−c3+mp2+32−c3+mp2+64−c64+mp2+fc256+softmax。对于pamap2示例,可以沿时间维度执行卷积和最大池化层,其中c3具有滤波器形状[1×3],并且mp2具有滤波器形状[1×2]。进一步设想到的是,对于pamap2示例,可以在每一层之后添加批量归一化,并且在全连接层之前可能有丢弃层(dropoutlayer)存在。
svhn的结果还基于使用来自门牌号码(housenumber)的照片的示例性实验,其中数据集的剪裁格式是以每个数字为中心的32×32像素彩色图像。对于svhn示例,7层网络被定义为:48−c5+mp2−2*(64−c3)−mp2−3*(128−c3)−fc512−softmax。对于svhn示例,执行每一层处的批量归一化,并且网络在全连接层之前包括丢弃层。最后,svhn示例将图片调整大小为40×40像素。
最后,cifar-10的结果还基于遵循vgg启发式架构的示例性实验,该架构被定义为:2*(128−c3)+mp2+2*(256−c3)+mp2+2*(512−c3)+mp2+1024−fc+softmax。对于cifar-10示例,使用数据增强来增加训练数据的大小。
如表2所图示的,pamap2和svhn数据集之间存在类似的倾向(propensity)。例如,fpid或dbid方法对于pamap2显著增加了验证误差,并且对于svhn稍微增加了验证误差。通过添加具有64个卷积核滤波器(k=64)的bil层,可以将误差减小为类似于基线模型的级别。对于pamap2数据集,bil模型甚至可以优于基线误差达1.92个百分点(即,21.66%−19.74%=1.92%)。
基于所评估的数据集,设想到的是,关于bil模型为什么可以优于基线模型,可能存在若干原因。首先,pamap2是已知的多模态数据集,其包括加速度计、陀螺仪和心率数据。与图像数据集(例如,svhn和cifar-10)形成对照,可能不包括传感器模态的完整范围(例如,非常高的加速度)。因此,可能并非所有输入位都同等地相关。这进而激发了位特定的二进制权重的使用。其次,针对pamap2与针对图像数据集(即,svhn和cifar-10)不同地来处理通道。对于pamap2,输入数据具有形状[高度=7×宽度=100×通道=1],而对于svhn图像数据集,形状可以是[高度=40×宽度=40×通道=3],并且cifar-10图像数据集,形状可以是[高度=32×宽度=32×通道=3]。结果是,在svhn和cifar-10数据集的情况下,(rgb)通道将在第一层处融合,而它们针对pamap2数据集可以保持分离。
由于bil卷积滤波器的数量(k)对于所有数据集可能是相同的,因此图像分类模型可能具有较少的参数来学习输入数据的有意义的表示。例如,对于cifar-10数据集,具有卷积滤波器k=256的bil模型可能导致比基线模型大4.58pp(即,13.65%-9.07%=4.58%)的验证误差。然而,可以通过增加bil卷积滤波器的数量(k)或通过独立于通道的网络的实现来减少svhn和cifar-10数据集的验证误差。还设想到的是,cifar-10由于小的数据集大小——其是svhn的1/12——而导致高的误差率。
本文中公开的过程、方法或算法可以可递交给处理设备、控制器或计算机/由处理设备、控制器或计算机来实现,所述处理设备、控制器或计算机可以包括任何现有的可编程电子控制单元或专用电子控制单元。类似地,可以以许多形式将过程、方法或算法存储为可由控制器或计算机执行的数据、逻辑和指令,所述形式包括但不限于:永久地存储在不可写存储介质(诸如rom设备)上的信息、以及可更改地存储在可写存储介质(诸如,软盘、磁带、cd、ram设备和其他磁性和光学介质)上的信息。过程、方法或算法还可以在软件可执行对象中实现。替代地,可以使用合适的硬件组件来整体或部分地体现过程、方法或算法,所述合适的硬件组件诸如:专用集成电路(asic),现场可编程门阵列(fpga),状态机,控制器或者其他硬件组件或设备,或者硬件、软件和固件组件的组合。
虽然上面描述了示例性实施例,但是并不意图这些实施例描述了本发明的所有可能形式。而是,说明书中使用的词语是描述而不是限制的词语,并且要理解的是,可以在不脱离本发明的精神和范围的情况下做出各种改变。附加地,各种实现实施例的特征可以被组合以形成本发明的进一步实施例。
- 还没有人留言评论。精彩留言会获得点赞!