一种面向配网1+N系统集中监控的告警同步方法和装置与流程
本发明涉及电力调度自动化技术领域,具体涉及一种面向配网1+n系统集中监控的告警同步方法和装置。
背景技术:
配网电力大数据分析已经成为当下许多电力专家和厂家研究的方向。电力的大数据来源是一切分析的前提条件,如果将分散的数据形成标准数据,再进行存储,形成大数据资产层,为电网企业提供高效、有价值的指导、预测和分析有着极为重要的意义。配网1+n系统是配电系统中地市侧和主站侧集中管理的系统,其中“1”是指配电主站侧,“n”是指配电地市侧。配网1+n系统集中监控时需要将配电地市侧告警同步到配电主站系统中进行统一、高效管理。在配网1+n系统中如何将分散的数据可靠的合并到一起需要高效安全的数据同步方法。目前数据库同步技术越来越成熟,开源技术层出不穷。配网1+n系统包含大量告警信息,数据多源,一旦出现数据丢失排查过程繁琐。由于各系统现场实际运行情况复杂多变,可能会出现数据同步问题,如何高效排查定位出丢失的告警数据也是配电运行人员关心的重要问题。
近年来适用于大数据及多源系统数据的技术包括kafka和protocolbuffers等。kafka是一种高吞吐量的分布式发布订阅消息系统,具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。protocolbuffers是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或rpc数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。可以利用这些技术实现多源系统告警数据的同步。
现有配电自动化领域数据同步技术主要是基于服务总线实现sql语句的同步的方式。一般过程是定期从数据源加载(增量)数据,按照转换逻辑进行处理,并写入目的地。根据业务需要和计算能力的不同,批量处理的延时通常从天到分钟级不等,而且无法较好的适用于多源系统的同步。
现有基于数据库之间各种类似etl工具同步技术,操作成本很高:它通常很慢,并且是时间和资源密集型的,而且是批量处理的方式,不利于数据的高效传输,在处理业务性较强的配电数据,不能实时更新频繁变化的过滤策略。
在大数据领域基于kafka的数据同步技术使用越来越多,也有不少的数据同步软件,要么不能适用于安全区管理需要,要么部署复杂,维护成本高,需要很强的运维能力。需要一种适用于当前配电自动化监控系统的数据同步技术,能够解决数据异构、高效同步、便于运维排查的方法。
技术实现要素:
为解决现有技术中的不足,本发明提供一种面向配网1+n系统集中监控的告警同步方法和装置,解决了现有大量告警数据同步处理效率低下、运维排查困难的问题。
为了实现上述目标,本发明采用如下技术方案:一种面向配网1+n系统集中监控的告警同步方法,包括步骤:
在配网1+n系统的配网主站侧配置各地市告警的告警同步策略和字段映射关系以及人工补招告警数据时间段;
获取并监听地市侧与配网主站通信的kafka系统的topic,若是同一个topic才能通信,按照同步策略从数据库中查询出需要同步的告警数据,通过protocolbuffers进行告警数据序列化后,再通过kafka系统发送到主站侧;
主站侧系统收到序列化后的告警数据,通过protocolbuffers进行反序列化,对反序列化后的数据根据字段映射关系逐条解析后,将数据存入主站侧数据库,将告警数据是否成功提交到数据库的状态信息写本地日志和发送到配电地市侧;
地市侧系统获取主站侧返回的告警是否成功入库信息,记录到日志后提示运维监控人员。
进一步的,所述同步策略包括同步的告警类型、同步时间段、同步频率、同步模式;
所述同步模式包括增量同步和存量同步;增量同步表示定时同步告警数据,存量同步表示按人工设置的补招时间段补招同步告警数据。
进一步的,所述字段映射关系表示各地市的告警字段和配网主站的各告警字段的对应关系。
进一步的,所述按照同步策略从数据库中查询出需要同步的告警数据,步骤包括:
地市侧系统判断收到的同步策略中的同步模式,若是存量模式,则:
配网地市侧系统检查本地记录中是否存在告警发送到主站失败信息,如果存在失败信息,地市侧系统从数据库中查询出失败时间段需要同步的告警数据;
若没有,则配网地市侧系统根据同步策略中的告警类型和定时的时间段从数据库中查询出需要同步的告警数据;
若是增量模式,则:
配网地市侧系统根据同步策略中的告警类型和定时的时间段从数据库中查询出需要同步的告警数据。
进一步的,所述配网1+n系统包括:1个配网主站和n个配网地市侧系统。
一种面向配网1+n系统集中监控的告警同步装置,包括配网主站中的同步维护模块和解析处理模块和n个配网地市侧系统中的源端数据抽取模块、校验通知模块、告警同步策略与映射模块;
同步维护模块,用于在配网1+n系统的配网主站侧配置地市侧系统向配网主站侧上送告警的同步策略和字段映射关系,以及人工补招告警数据时间段;
告警同步策略与映射模块,用于保存配网主站侧下发的同步策略、字段映射关系以及人工补招告警数据时间段;
源端数据抽取模块,用于监听地市侧与配网主站通信的kafka系统的topic,若是同一个topic才能通信;按照同步策略从数据库中查询出需要同步的告警数据,通过protocolbuffers进行告警数据序列化后,再通过kafka系统发送到主站侧;
解析处理模块,用于收到序列化后的告警数据,通过protocolbuffers进行反序列化,对反序列化后的数据根据字段映射关系逐条解析后,将数据存入主站侧数据库,将告警数据是否成功提交到数据库的状态信息写本地日志和发送到配电地市侧;
校验通知模块,用于获取主站侧返回的告警是否成功入库信息,记录到日志后提示运维监控人员。
进一步的,所述同步策略包括同步的告警类型、同步时间段、同步频率、同步模式;
所述同步模式包括增量同步和存量同步;增量同步表示定时同步告警数据,存量同步表示按人工设置的补招时间段补招同步告警数据。
进一步的,所述字段映射关系表示各地市的告警字段和配网主站的各告警字段的对应关系。
进一步的,所述按照同步策略从数据库中查询出需要同步的告警数据,步骤包括:
地市侧系统判断收到的同步策略中的同步模式,若是存量模式,则:
配网地市侧系统检查本地记录中是否存在告警发送到主站失败信息,如果存在失败信息,地市侧系统从数据库中查询出失败时间段需要同步的告警数据;
若没有,则配网地市侧系统根据同步策略中的告警类型和定时的时间段从数据库中查询出需要同步的告警数据;
若是增量模式,则:
配网地市侧系统根据同步策略中的告警类型和定时的时间段从数据库中查询出需要同步的告警数据。
进一步的,所述配网1+n系统包括:1个配网主站和n个配网地市侧系统。
本发明所达到的有益效果:本发明将通过在配网主站侧和配网多个地市侧部署各个模块,使用开源kafka系统实现了告警集中监控模式下大量数据的高效传输,让运行维护人员从浩繁的告警信息处理手工作业中解放出来,可以提高告警数据同步的一致性,有利于迅速定位位同步告警,提高设备监视、事故处理等运行作业的效率和水平,从而获得最大的安全效益。
附图说明
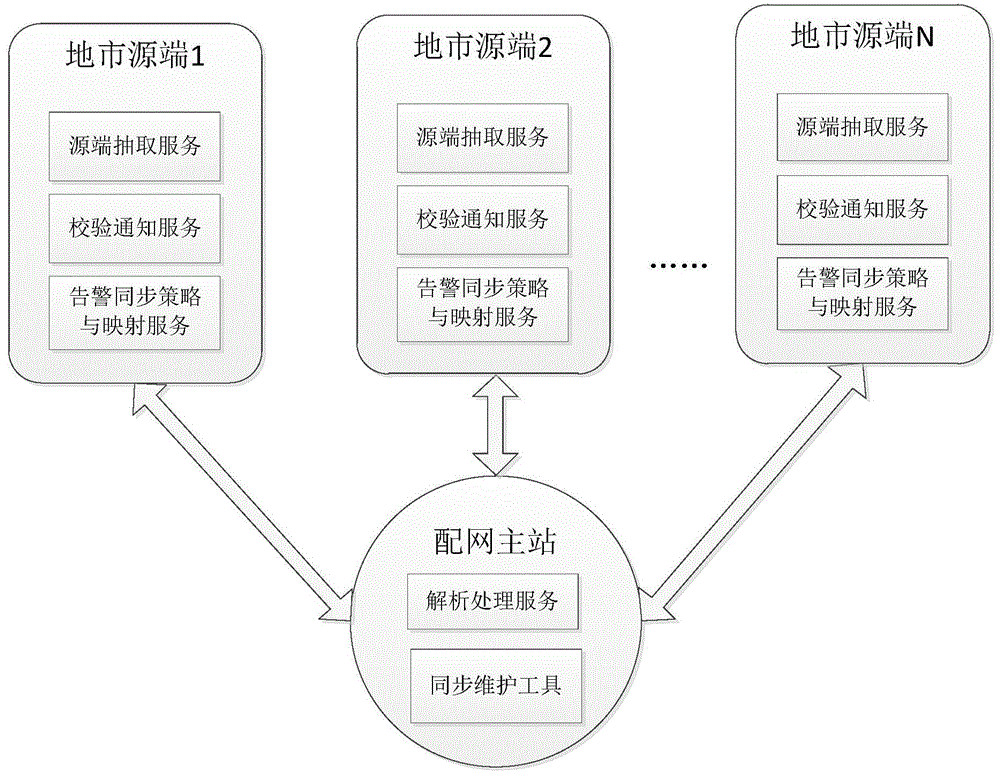
图1是本发明的配网1+n系统架构示意图。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
配网1+n系统包括:“1”个配网主站和“n”个配网地市源端。配网主站可以直接监控地市源端的电网数据,通过本发明,可以实现多个配电地市侧同时向配网主站侧同步告警数据。
实施例1:
如图1所示,一种面向配网1+n系统集中监控的告警同步装置,包括:
配网主站中的同步维护模块和解析处理模块和n个配网地市侧系统中的源端数据抽取模块、校验通知模块、告警同步策略与映射模块;
同步维护模块,用于在配网1+n系统的配网主站侧配置地市侧系统向配网主站侧上送告警的同步策略和字段映射关系,以及人工补招告警数据时间段;
同步策略包括同步的告警类型、同步时间段(非合法时间范围停止同步告警)、同步频率(定时同步)、同步模式(增量同步、存量同步)等,如仅在某日的9:00-12:00期间每隔5分钟进行配网开关变位告警数据的同步。增量同步表示定时同步告警数据,存量同步表示在历史数据库中按人工设置的补招时间段补招同步告警数据;字段映射关系表示各地市的告警字段和配网主站的各告警字段的对应关系。
告警同步策略与映射模块,用于保存配网主站侧下发的同步策略、字段映射关系以及人工补招告警数据时间段;
源端数据抽取模块,用于监听地市侧与配网主站通信的kafka系统的topic(主题或者通道),若是同一个topic才能通信;地市侧系统判断收到的同步策略中的同步模式,若是存量模式,则:
配网地市侧系统检查本地记录中是否存在告警发送到主站失败信息,如果存在失败信息,地市侧系统从数据库中查询出失败时间段需要同步的告警数据;这种方式可增强数据的一致性;
若没有,则配网地市侧系统根据同步策略中的告警类型和定时的时间段从数据库中查询出需要同步的告警数据;
通过protocolbuffers进行告警数据序列化后,再通过kafka系统发送到主站侧;
若是增量模式,则:
配网地市侧系统根据同步策略中的告警类型和定时的时间段从数据库中查询出需要同步的告警数据,通过protocolbuffers进行序列化后,再通过kafka系统发送到主站侧;
解析处理模块,用于收到序列化后的告警数据,通过protocolbuffers进行反序列化,对反序列化后的数据根据字段映射关系逐条解析后,将数据存入主站侧数据库,将告警数据是否成功提交到数据库的状态信息写本地日志和发送到配电地市侧。
校验通知模块,用于获取主站侧返回的告警是否成功入库信息,记录到日志后提示运维监控人员,如是否已同步、失败信息等。
实施例2:
一种面向配网1+n系统集中监控的告警同步方法,包括步骤:
步骤1,在配网1+n系统的配网主站侧配置各地市告警的告警同步策略和字段映射关系以及人工补招告警数据时间段;具体为:
配置地市侧系统向配网主站侧上送告警的同步策略和字段映射关系以及人工补招告警数据时间段,将告警同步策略和字段映射关系以及人工补招告警数据时间段通过开源的kafka系统下发到各地市侧系统。
同步策略包括同步的告警类型、同步时间段(非合法时间范围停止同步告警)、同步频率(定时同步)、同步模式(增量同步、存量同步)等,如仅在某日的9:00-12:00期间每隔5分钟进行配网开关变位告警数据的同步。增量同步表示定时同步告警数据,存量同步表示在历史数据库中按人工设置的补招时间段补招同步告警数据;字段映射关系表示各地市的告警字段和配网主站的各告警字段的对应关系。
步骤2,获取并监听地市侧与配网主站通信的kafka系统的topic(主题或者通道),若是同一个topic才能通信;地市侧系统判断收到的同步策略中的同步模式,若是存量模式,则:
配网地市侧系统检查本地记录中是否存在告警发送到主站失败信息,如果存在失败信息,地市侧系统从数据库中查询出失败时间段需要同步的告警数据;这种方式可增强数据的一致性;
若没有,则配网地市侧系统根据同步策略中的告警类型和定时的时间段从数据库中查询出需要同步的告警数据;
通过protocolbuffers进行告警数据序列化后,再通过kafka系统发送到主站侧;
若是增量模式,则:
配网地市侧系统根据同步策略中的告警类型和定时的时间段从数据库中查询出需要同步的告警数据,通过protocolbuffers进行序列化后,再通过kafka系统发送到主站侧;
步骤3,主站侧系统收到序列化后的告警数据,通过protocolbuffers进行反序列化,对反序列化后的数据根据字段映射关系逐条解析后,将数据存入主站侧数据库,将告警数据是否成功提交到数据库的状态信息写本地日志和发送到配电地市侧;
地市侧系统获取主站侧返回的告警是否成功入库信息,记录到日志后提示运维监控人员。
综上所述,配网“1+n”系统使用上述告警同步方法,不仅在地市侧实现了告警同步状态的可视化,而且使用开源kafka系统实现了告警集中监控模式下大量数据的高效传输。此外,在告警同步主站侧实现了对地市告警同步策略和字段映射关系的工具化配置,可以极大提高电网运行维护人员的工作效率。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!