一种用于森林云雾图像分割的方法、存储介质和设备与流程
本发明属于计算机视觉和森林防火视频监测领域,涉及一种用于森林云雾图像分割的方法、存储介质和设备。
背景技术:
森林火灾是一种破坏性大、难以消除的自然灾害,世界上每年因森林火灾带来的人员伤亡数以万计,财产损失更是难以估量,例如近年的美国加州森林大火、印尼森林大火、亚马逊森林火灾,引起了世界的广泛关注。这些引起世界关注的森林火灾事件,不仅造成了非常严重的人员伤亡和财产损失,也对地球环境造成了严重的影响。我国森林面积广阔,每年因森林火灾造成的损失更是非常严重。由于天气、气候等原因,一旦发生森林火灾,扑灭是非常困难的,需要投入大量的人力物力,因此森林火灾扑救应遵循早发现、早出动和早扑灭的“三早”原则,为了能够及早发现森林火灾,传统的方法中,通常是利用各类传感器对烟雾颗粒进行检测,但传感器检测系统容易发生漏检并且传感器工作环境要求严苛、维护成本高。随着视频处理技术的飞速发展,基于视频分析的森林烟火检测已然成为森林地区火灾检测的一种发展趋势,具有准确高效、报警时效性强、信息多样等重要优势。但是基于视频的森林烟火检测方法存在一个明显缺点,由于森林烟火检测算法主要检测的是火灾初期的烟雾,而火灾烟雾和森林中的云雾在形态特征上存在一定的相似性,容易造成误报情况,因此,为了提高森林烟火检测算法的可靠性,在检测之前,将云雾区域分割出来并加以屏蔽,降低算法的误报率,提高算法的泛化能力。
现有技术中,通常是采用暗通道方法进行森林云雾分割,但基于暗通道方法进行云雾分割时,依赖人工设置的阈值,并且只能分割大致的云雾区域,当场景变化时需要调整阈值才能正确分割,因此准确率比较低,且泛化能力和鲁棒性差。例如,在使用暗通道方法,分割单帧森林云雾图像时,需要的时间约为20ms,分割精度约为80%,虽然,分割速度较快,但是对于森林火灾而言,不仅要快速的对图像进行分割,同时要求具有高的分割精度,如果精度较低,造成误报,从而不能及时的发现火灾,相较于时间成本,造成的损失将是非常巨大的。
综上分析,目前进行森林云雾分割时,主要存在着分割准确率低、难以兼顾准确率和效率,并且还需要根据森林场景修改阈值,适用性差等缺点。
技术实现要素:
技术问题:本发明提供一种用于森林云雾图像分割的方法,旨在能够在不修改阈值的情况下,适用不同森林场景下的云雾图像分割问题,同时兼顾效率和准确率,准确高效地对森林云雾图像进行分割,从而准确地对森林烟火进行检测。同时提供一种用于森林云雾图像分割的存储介质和设备,用于工程部署。
技术方案:本发明的用于森林云雾图像分割的方法,首先获取森林云雾图像,然后采用轻量级神经网络串联编码模块和解码模块构成语义分割网络模型对森林云雾图像进行处理,森林云雾图像在所述语义分割网络模型中执行前向计算进行图像分割,输出森林云雾图像中云雾区域的掩码图。
进一步地,搭建所述语义分割网络模型并进行训练的步骤:
s1:建立森林云雾图像样本数据集,并对森林图像中云雾区域进行标定;
s2:搭建基于轻量级网络mobilenet的deeplab语义分割网络模型,采用预训练的轻量级网络mobilenet作为deeplab的骨干网络,并串联编码模块和解码模块;
s3:采用所述的森林云雾图像样本数据集,对所述语义分割网络模型进行训练,并保存权值文件。
进一步地,所述步骤s2中,采用轻量级网络mobilenetv2作为骨干网络,搭建deeplabv3+的语义分割网络。
进一步地,所述步骤s2中搭建的语义分割网络模型,输入尺寸为w×h森林云雾图像,输出相同尺寸的森林云雾图像的掩码图,w表示图像的宽度,h表示图像的高度。
进一步地,所述步骤s1中,建立森林云雾图像样本数据集时,考虑地形地貌、距离、光照和摄像机拍摄角度进行图像采集。
进一步地,所述步骤s1中,建立森林图像样本数据集时,样本数据集中单个样本图像中云雾占比大于易误报比。
进一步地,所述步骤s2中,训练语义分割网络模型时,采用随机梯度下降法。
进一步地,所述步骤s2中,训练网络模型时,损失函数采用交叉熵损失函数,具体公式为:
式中,l(p,q)表示损失函数,其中p是真实标签向量,q是网络预测的概率向量,pi是真实标签中的第i个元素,qi是网络实际输出概率中的第i个元素;对于本场景中的像素二分类问题,网络最终预测结果为0或1,0表示该像素预测为背景信息,1代表该像素预测为云雾,预测结果为1的概率为
本发明的用于森林云雾图像分割的存储介质,存储用于执行所述用于森林云雾图像分割的方法操作的程序指令,所述指令在被执行时使得所述介质能够:
读取森林云雾图像;
读取训练好的语义分割网络模型的权值文件,调用神经网络模型,对森林云雾图像进行分割,输出森林云雾图像的云雾区域的掩码图。
本发明的用于森林云雾图像分割的设备,包括一个或多个用于森林云雾图像分割的存储介质。
有益效果:本发明与现有技术相比,具有以下优点:
本发明的用于森林云雾图像分割的方法,采用轻量级网络mobilenet作为骨干网络,搭建deeplab语义分割网络模型,用于对森林云雾图像进行分割。mobilenet是为移动和嵌入式设备提出的高效模型,其基于流线型框架使用深度可分离卷积来构建轻量级深度神经网络,可显著减低计算消耗。对于本发明优选的mobilenetv2,采用深度可分离卷积并将最后的激活函数换成relu6,可以在减少网络计算量的同时,解决了梯度消失问题。deeplab是专门用于语义分割的网络模型,具有非常高的分割精度,尤其是本发明优选的deeplabv3+网络。但分割精度越高,导致分割速度下降,本发明将追求计算效率的mobilenet网络与deeplab网络结合,平衡语义分割的精度和速度,在保证精度满足应用要求的同时,具有较快的速度,从而能够高效准确地对森林云雾图像进行分割,进而降低了误报,从而能够准确地对森林烟火进行检测。
本发明的方法,无需像采用暗通道方法时,需要不断的改变阈值,即可准确高效地对森林云雾图像进行分割,解决了暗通道法依赖人工设置阈值且只能分割大致的云雾区域,准确率低的缺点,并且本发明的方法只需一个训练好的权值文件就能覆盖绝大部分的森林场景,具有较强的泛化能力和鲁棒性。能够适用于复杂的森林场景中,进行云雾图像分割,有效地提高了嵌入式设备的应用范围,提高了森林烟火检测的准确率,从而能够及时的发现森林烟火情况,对森林火灾进行及早扑救,减少人员伤亡和财产损失。
附图说明
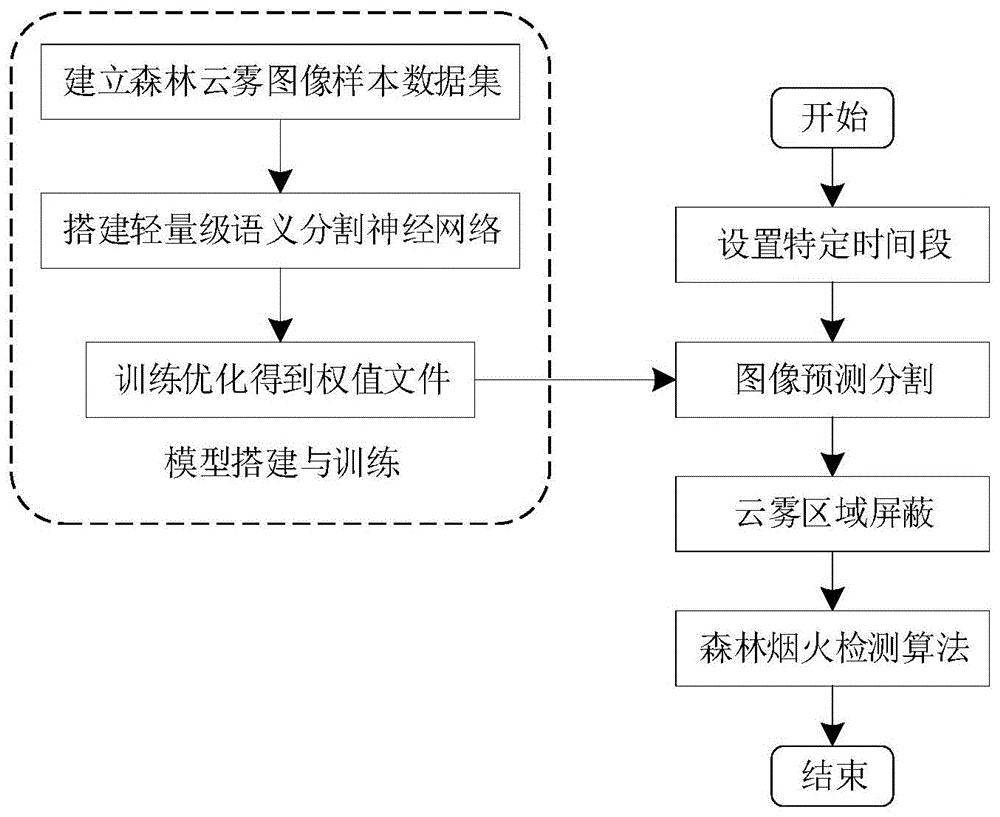
图1为本发明的用于森林云雾图像分割的方法的流程图;
图2为本发明搭建的语义分割网络模型结构图。
具体实施方式
下面结合实施例和说明书附图对本发明作进一步的说明。
本发明的用于森林云雾图像分割的方法,主要用于森林烟火检测过程中的图像预测分割阶段,该阶段主要作用是对设定时间段的图像进行分割,将图像中的云或雾分割出来,从而将疑似火灾烟雾区域进行遮蔽,从而为后续通过森林烟火检测算法进行烟火检测时提供基础,使得森林烟火检测算法能够快速准确的识别森林烟火。
结合图1,对本发明的具体实施方式进行详细说明,对与本发明的方法,其关键点在于搭建和训练语义分割模型,在搭建和训练语义分割模型时,按如下步骤进行:
s1:基于森林烟火视频监控系统,手工或自动收集森林云雾图像样本,建立森林云雾图像样本数据集,并将样本数据集按比例随机划分为训练集和测试集。
森林烟火监控视频能够对森林状况进行实时监控,因此可借助该系统手动或者自动的收集森林云雾图像,初步的建立森林云雾图像的样本数据集。由于本发明的目的是为了对云雾进行分割,因此需要提前对样本数据集中的样本图像进行精细的人工标定,标定出样本图像中的云雾区域。
将样本数据集标定完成后,按比例随机的将样本数据集划分为训练集和测试集,通常情况下,训练集和测试集的比例为8:2或7:3,具体也可以根据需要进行划分。
森林云雾图像样本在采集时,为保证训练样本有足够的代表性,需要考虑地形地貌、距离、光照、摄像机拍摄角度等因素,使得样本图像能够进行多种场景的覆盖。在实际应用中,要根据易误报比确定选择哪些图像作为样本,其中易误报比为自定义概念,所谓易误报比是指视频图像中云雾面积占比大于某一比例时,算法容易出现大面积误报,称这个比例为易误报比。通常情况下,当视频图像中云雾的面积占比大于30%时算法容易出现大面积误报,此时设备无需检测烟雾,因此为了契合实际应用,尽量选择单张图像中云雾占比大于30%作为样本数据集,避免正负样本的差距过大。
此外,由于从不同监控系统中收集的图像样本存在不同的尺寸,为了方便后续的处理,将照片压缩成统一尺寸。
s2:搭建基于轻量级网络mobilenet的deeplab语义分割网络结构,采用预训练好的轻量级网络mobilenet作为deeplab的骨干网络,并串联编码模块和解码模块搭建语义分割网络,进而平衡分割的速度与精度;
轻量级网络mobilenet是为移动和嵌入式设备提出的高效模型,其基于流线型框架使用深度可分离卷积来构建轻量级深度神经网络,可显著减低计算消耗。轻量级网络mobilenet系列已有v1、v2和v3三个版本,其中mobilenetv2具备成熟的框架方便模型部署,且具有较优的分割速度,使其能在嵌入式设备上运行,因此本发明优选的是采用预训练好的mobilenetv2作为语义分割的骨干网络,当然并不限于mobilenetv2,也可以采用mobilenetv1、mobilenetv3。
deeplab是一个专门用来处理语义分割的模型,主要框架是基于编码器-解码器结构实现,用于高精度的语义分割。deeplab系列目前推出4个版本,其中deeplabv3+版本是具备最优分割精度的模型,因此本发明优选的是deeplabv3+模型,当然在其他实施例中也可采用deeplab模型的其他版本。以mobilenetv2网络作为deeplabv3+的骨干网络,然后串联编码模块和解码模块,完成语义分割模型搭建。编码模块和解码模块的网络结构如图2所示,网络主要由卷积层、降采样层和上采样层(反卷积层)组成,编码部分采用空洞卷积atrousconvolution提取不同尺度的图像特征并进行融合,采用空洞卷积会在卷积中间插入0使得卷积核扩大,扩展感受野获取更多的上下文信息,同时采用完全连接的条件随机场提高模型捕获细节的能力。解码部分并非直接双线性上采样到原始分辨率,而是引入编码阶段不同分辨率的特征图,采用跳跃连接的方式得到原始分辨率图像的分割掩码图。
基于深度学习的语义分割方法存在分割精度越高模型越大导致运行速度越慢的矛盾,为了能够将本方法应用在实际工程中,本发明平衡分割精度与分割速度,将追求计算效率的moblienet网络与追求分割精度的deeplab框架相结合的方法,在deeplabv3+语义分割网络的框架下,采用mobilenetv2的预训练网络作为骨干网络可以大大减小模型进行前向传播时的计算量,更好的应用于工程实践。
对于所搭建的语义分割模型,输入尺寸为w×h森林云雾图像,w表示图像的宽度,h表示图像的高度,一般是采用像素进行表示,在实际工程中,通常可选择1280×720、1920×1280、800×450等尺寸。通常图像尺寸也可以用c×w×h表示,c表示图像通道数,一般为bgr三通道。在同一样本数据集中,应该保持图像尺寸一致,当修改了图像输入尺寸,调用网络时需要修改相应的参数。
s3:加载森林云雾图像样本数据集,调整网络模型的超参数进行训练优化,对模型参数进行迭代优化,根据测试精度挑选表现最优的模型,并保存权值文件。模型的超参数主要包括学习率、迭代次数、batch-size、优化器等,当使用deeplabv3+网络时,需要设置金字塔池化中三个并行的卷积扩张率,三个并行的卷积位置参见图2所示。
在进行语义分割网络模型训练时,可按如下步骤进行:
步骤s311:数据集处理
对数据集处理时,包括图像样本标定、制作样本指示文件、将数据打包成tfrecord格式、注册数据集操作,其中标定数据可采用labelme软件辅助标定;
步骤s312:数据不平衡处理
由于数据集中云雾区域面积和背景区域面积在总的样本中所占的比例有差距,因此可在编写的算法代码中增加分类为云雾区域的损失函数的权重,平衡各类样本的比重,使得训练得到的模型在验证集上有更高的准确率;
步骤s313:设置初始训练参数,通过不断调整网络模型的超参数,使得优化后模型的分割精度达到最优;
步骤s314:可视化分割结果,评估分割的精度并测试分割一张图片需要消耗的时间。
在步骤s3中,采用随机梯度下降法进行模型参数优化,即优化器选择的是随机梯度下降法,并且采用交叉熵损失函数作为损失函数,其中交叉熵损失函数的公式为:
式中,l(p,q)表示损失函数,其中p是真实标签向量,q是网络预测的概率向量,pi是真实标签中的第i个元素,qi是网络实际输出概率中的第i个元素;对于本场景中的像素二分类问题,网络最终预测结果为0或1,0表示该像素预测为背景信息,1代表该像素预测为云雾,预测结果为1的概率为
为了对本发明的效果进行进一步的验证,基于上述步骤完成语义模型的搭建与训练,完成一帧图像的森林云雾分割,并与暗通道方法进行结果对比。
首先建立森林云雾样本数据集,该数据集包括3620个样本图像,并将所有样本图像统一裁剪为800×450大小,按8:2的比例随机划分训练集和测试集。然后采用mobilenetv2作为骨架网络,搭建deeplabv3+的语义分割模型。将学习率设置为0.0001,迭代次数为30000次,根据gpu选择batch-size为4,deeplabv3+网络的金字塔池化中三个并行的卷积扩张率分别为6、12、18。然后在tensorflow框架中建立网络模型,对模型进行训练,并将表现效果最优的模型的权值文件保存。最后输入一帧森林视频图像进行分割,并输出掩码图。
采用同样的样本数据集,应用暗通道方法,对视频图像进行分割。采用本发明的方法与暗通道方法的对比结果如表1所示:
表1本发明的方法与暗通道方法的结果对比
由表1可以看出,采用本发明的方法精度达到了96.21%,分割单张图像的所需时间为50.3ms,而采用暗通道的方法精度仅为79.18%,分割单张图像所需时间为16.7ms。本发明的方法相比暗通道方法进度提高了17.03%,可以显著提高云雾分割精度,虽然在处理时间上比不过传统的基于暗通道分割的方法,但是本方法平均分割效率在50ms左右,能够在原有的嵌入式设备上部署应用。虽然采用暗通道方法分割图像的速度很高,但是其精度却明显不如本发明的方法,在分割速度上,本发明的方法与暗通道方法相比,都在毫秒级,且均在100毫秒以下,完全都能满足嵌入式设备的需求,但是本发明的方法,分割精度高达96.21%,是非常准确的,能够有效地避免误报。相较于时间成本,因为误报难以准确识别森林火灾,从而不能及时扑救,造成的损失将是非常庞大的。并且相比暗通道方法,本发明的方法不需要人工设定阈值,泛化能力强,能够适用于复杂的森林场景下森林云雾图像的分割,因此综合精度、时间以及实际应用需求进行考量,本发明的方法具有显著的优点,在具有较高效率的同时,兼具更高的精度,能够对森林云雾进行精确分割,从而减少森林烟火检测的误报率,进而准确发现森林火灾。
本发明的方法中采用的轻量级神经网络,并不局限与mobilenet网络模型,还可以采用其他轻量级网络的替代,例如:squeezenet、shufflenet、igcv、densenet、xception。
本发明的方法通过计算机编写成为可执行的程序指令,训练好的语义分割模型的权值文件存储在存储介质中,当指令被执行后,能够完成如下操作:读取森林云雾图像;读取训练好的语义分割网络模型的权值文件,调用神经网络模型,对森林云雾图像进行分割,输出森林云雾图像的云雾区域的掩码图。
同时,本发明还提供了一种用于森林云雾分割的设备,该设备中包括一个或多个上述的存储介质,实际工程中,直接部署该设备,完成森林云雾图像的分割。
上述实施例仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和等同替换,这些对本发明权利要求进行改进和等同替换后的技术方案,均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!